 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabelCraft: Empowering Short Video Recommendations with Automated Label Crafting
Dec 18, 2023Short video recommendations often face limitations due to the quality of user feedback, which may not accurately depict user interests. To tackle this challenge, a new task has emerged: generating more dependable labels from original feedback. Existing label generation methods rely on manual rules, demanding substantial human effort and potentially misaligning with the desired objectives of the platform. To transcend these constraints, we introduce LabelCraft, a novel automated label generation method explicitly optimizing pivotal operational metrics for platform success. By formulating label generation as a higher-level optimization problem above recommender model optimization, LabelCraft introduces a trainable labeling model for automatic label mechanism modeling. Through meta-learning techniques, LabelCraft effectively addresses the bi-level optimization hurdle posed by the recommender and labeling models, enabling the automatic acquisition of intricate label generation mechanisms.Extensive experiments on real-world datasets corroborate LabelCraft's excellence across varied operational metrics, encompassing usage time, user engagement, and retention. Codes are available at https://github.com/baiyimeng/LabelCraft.
Inverse Learning with Extremely Sparse Feedback for Recommendation
Nov 20, 2023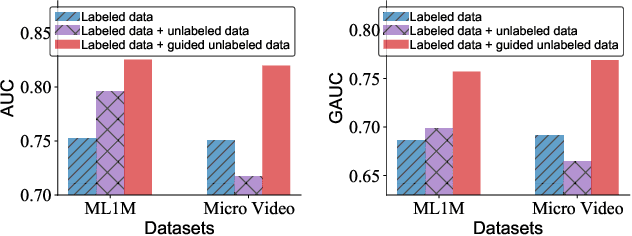
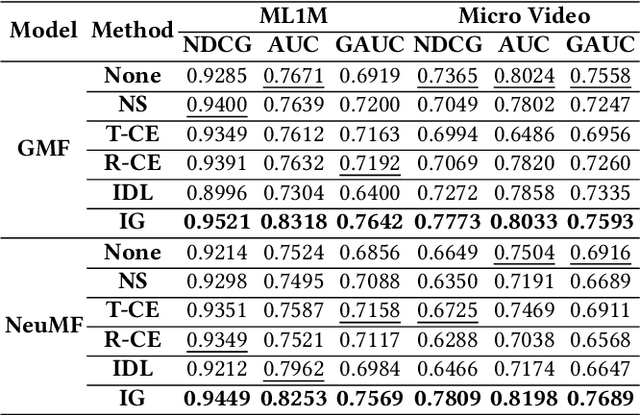
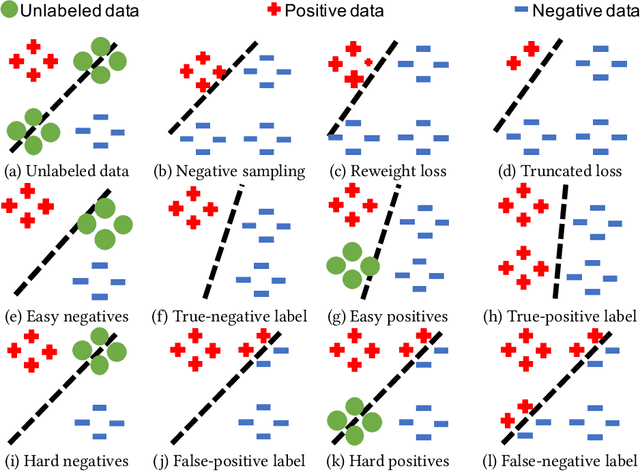

Modern personalized recommendation services often rely on user feedback, either explicit or implicit, to improve the quality of services. Explicit feedback refers to behaviors like ratings, while implicit feedback refers to behaviors like user clicks. However, in the scenario of full-screen video viewing experiences like Tiktok and Reels, the click action is absent, resulting in unclear feedback from users, hence introducing noises in modeling training. Existing approaches on de-noising recommendation mainly focus on positive instances while ignoring the noise in a large amount of sampled negative feedback. In this paper, we propose a meta-learning method to annotate the unlabeled data from loss and gradient perspectives, which considers the noises in both positive and negative instances. Specifically, we first propose an Inverse Dual Loss (IDL) to boost the true label learning and prevent the false label learning. Then we further propose an Inverse Gradient (IG) method to explore the correct updating gradient and adjust the updating based on meta-learning. Finally, we conduct extensive experiments on both benchmark and industrial datasets where our proposed method can significantly improve AUC by 9.25% against state-of-the-art methods. Further analysis verifies the proposed inverse learning framework is model-agnostic and can improve a variety of recommendation backbones. The source code, along with the best hyper-parameter settings, is available at this link: https://github.com/Guanyu-Lin/InverseLearning.
Mixed Attention Network for Cross-domain Sequential Recommendation
Nov 14, 2023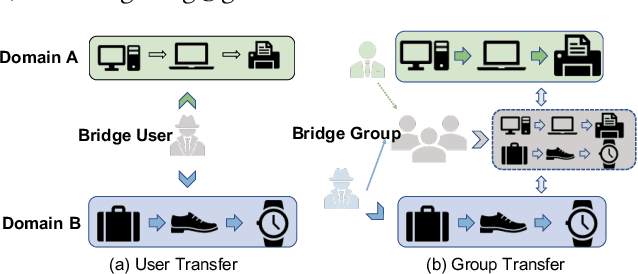
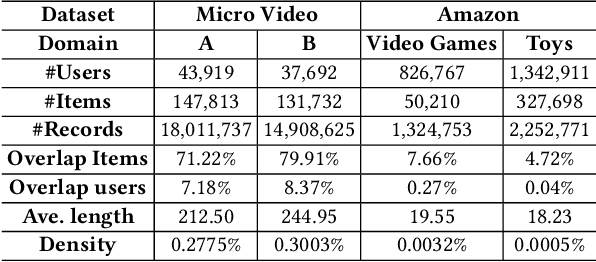
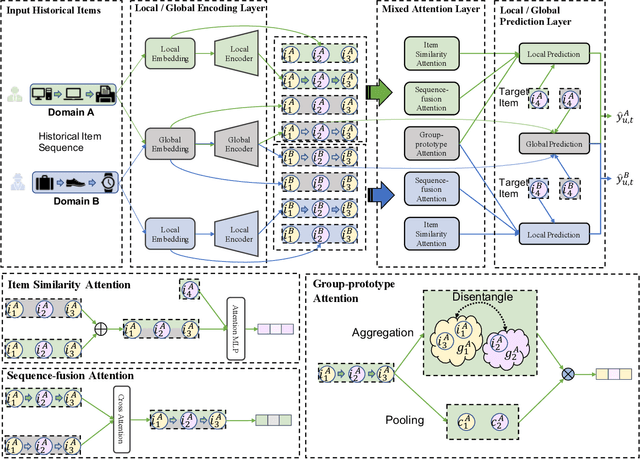
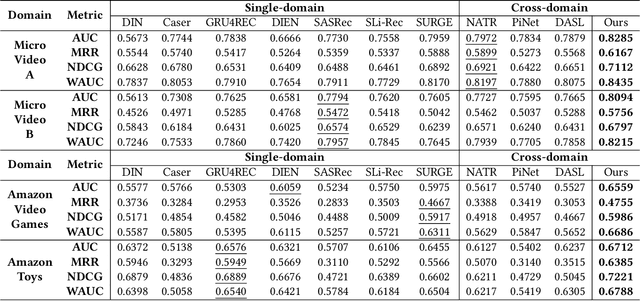
In modern recommender systems, sequential recommendation leverages chronological user behaviors to make effective next-item suggestions, which suffers from data sparsity issues, especially for new users. One promising line of work is the cross-domain recommendation, which trains models with data across multiple domains to improve the performance in data-scarce domains. Recent proposed cross-domain sequential recommendation models such as PiNet and DASL have a common drawback relying heavily on overlapped users in different domains, which limits their usage in practical recommender systems. In this paper, we propose a Mixed Attention Network (MAN) with local and global attention modules to extract the domain-specific and cross-domain information. Firstly, we propose a local/global encoding layer to capture the domain-specific/cross-domain sequential pattern. Then we propose a mixed attention layer with item similarity attention, sequence-fusion attention, and group-prototype attention to capture the local/global item similarity, fuse the local/global item sequence, and extract the user groups across different domains, respectively. Finally, we propose a local/global prediction layer to further evolve and combine the domain-specific and cross-domain interests. Experimental results on two real-world datasets (each with two domains) demonstrate the superiority of our proposed model. Further study also illustrates that our proposed method and components are model-agnostic and effective, respectively. The code and data are available at https://github.com/Guanyu-Lin/MAN.
Learning and Optimization of Implicit Negative Feedback for Industrial Short-video Recommender System
Aug 25, 2023Short-video recommendation is one of the most important recommendation applications in today's industrial information systems. Compared with other recommendation tasks, the enormous amount of feedback is the most typical characteristic. Specifically, in short-video recommendation, the easiest-to-collect user feedback is from the skipping behaviors, which leads to two critical challenges for the recommendation model. First, the skipping behavior reflects implicit user preferences, and thus it is challenging for interest extraction. Second, the kind of special feedback involves multiple objectives, such as total watching time, which is also very challenging. In this paper, we present our industrial solution in Kuaishou, which serves billion-level users every day. Specifically, we deploy a feedback-aware encoding module which well extracts user preference taking the impact of context into consideration. We further design a multi-objective prediction module which well distinguishes the relation and differences among different model objectives in the short-video recommendation. We conduct extensive online A/B testing, along with detailed and careful analysis, which verifies the effectiveness of our solution.
Understanding and Modeling Passive-Negative Feedback for Short-video Sequential Recommendation
Aug 08, 2023Sequential recommendation is one of the most important tasks in recommender systems, which aims to recommend the next interacted item with historical behaviors as input. Traditional sequential recommendation always mainly considers the collected positive feedback such as click, purchase, etc. However, in short-video platforms such as TikTok, video viewing behavior may not always represent positive feedback. Specifically, the videos are played automatically, and users passively receive the recommended videos. In this new scenario, users passively express negative feedback by skipping over videos they do not like, which provides valuable information about their preferences. Different from the negative feedback studied in traditional recommender systems, this passive-negative feedback can reflect users' interests and serve as an important supervision signal in extracting users' preferences. Therefore, it is essential to carefully design and utilize it in this novel recommendation scenario. In this work, we first conduct analyses based on a large-scale real-world short-video behavior dataset and illustrate the significance of leveraging passive feedback. We then propose a novel method that deploys the sub-interest encoder, which incorporates positive feedback and passive-negative feedback as supervision signals to learn the user's current active sub-interest. Moreover, we introduce an adaptive fusion layer to integrate various sub-interests effectively. To enhance the robustness of our model, we then introduce a multi-task learning module to simultaneously optimize two kinds of feedback -- passive-negative feedback and traditional randomly-sampled negative feedback. The experiments on two large-scale datasets verify that the proposed method can significantly outperform state-of-the-art approaches. The code is released at https://github.com/tsinghua-fib-lab/RecSys2023-SINE.
Leveraging Watch-time Feedback for Short-Video Recommendations: A Causal Labeling Framework
Jun 30, 2023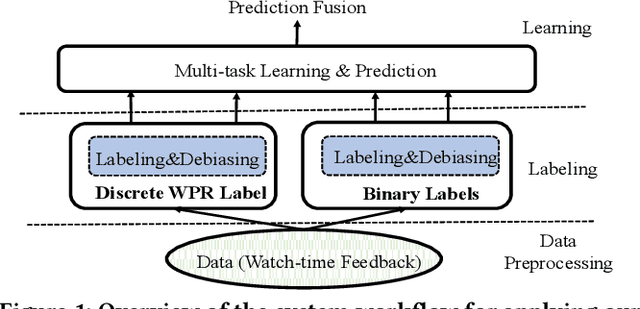

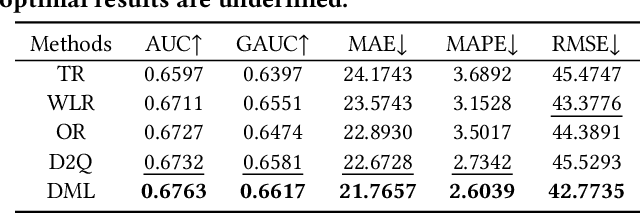
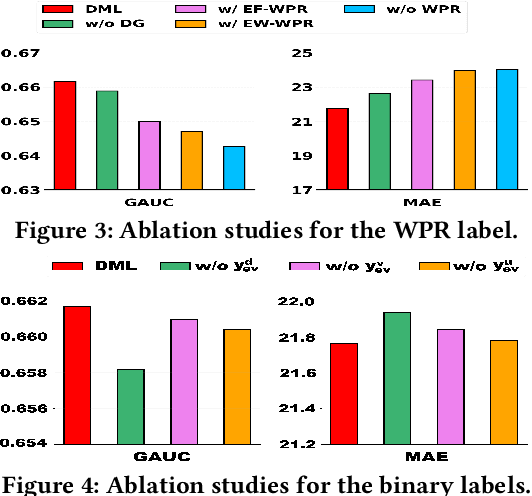
With the proliferation of short video applications, the significance of short video recommendations has vastly increased. Unlike other recommendation scenarios, short video recommendation systems heavily rely on feedback from watch time. Existing approaches simply treat watch time as a direct label, failing to effectively harness its extensive semantics and introduce bias, thereby limiting the potential for modeling user interests based on watch time. To overcome this challenge, we propose a framework named Debiasied Multiple-semantics-extracting Labeling (DML). DML constructs labels that encompass various semantics by utilizing quantiles derived from the distribution of watch time, prioritizing relative order rather than absolute label values. This approach facilitates easier model learning while aligning with the ranking objective of recommendations. Furthermore, we introduce a method inspired by causal adjustment to refine label definitions, thereby reducing the impact of bias on the label and directly mitigating bias at the label level. We substantiate the effectiveness of our DML framework through both online and offline experiments. Extensive results demonstrate that our DML could effectively leverage watch time to discover users' real interests, enhancing their engagement in our application.
Dual-interest Factorization-heads Attention for Sequential Recommendation
Feb 10, 2023



Accurate user interest modeling is vital for recommendation scenarios. One of the effective solutions is the sequential recommendation that relies on click behaviors, but this is not elegant in the video feed recommendation where users are passive in receiving the streaming contents and return skip or no-skip behaviors. Here skip and no-skip behaviors can be treated as negative and positive feedback, respectively. With the mixture of positive and negative feedback, it is challenging to capture the transition pattern of behavioral sequence. To do so, FeedRec has exploited a shared vanilla Transformer, which may be inelegant because head interaction of multi-heads attention does not consider different types of feedback. In this paper, we propose Dual-interest Factorization-heads Attention for Sequential Recommendation (short for DFAR) consisting of feedback-aware encoding layer, dual-interest disentangling layer and prediction layer. In the feedback-aware encoding layer, we first suppose each head of multi-heads attention can capture specific feedback relations. Then we further propose factorization-heads attention which can mask specific head interaction and inject feedback information so as to factorize the relation between different types of feedback. Additionally, we propose a dual-interest disentangling layer to decouple positive and negative interests before performing disentanglement on their representations. Finally, we evolve the positive and negative interests by corresponding towers whose outputs are contrastive by BPR loss. Experiments on two real-world datasets show the superiority of our proposed method against state-of-the-art baselines. Further ablation study and visualization also sustain its effectiveness. We release the source code here: https://github.com/tsinghua-fib-lab/WWW2023-DFAR.
TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou
Feb 05, 2023Life-long user behavior modeling, i.e., extracting a user's hidden interests from rich historical behaviors in months or even years, plays a central role in modern CTR prediction systems. Conventional algorithms mostly follow two cascading stages: a simple General Search Unit (GSU) for fast and coarse search over tens of thousands of long-term behaviors and an Exact Search Unit (ESU) for effective Target Attention (TA) over the small number of finalists from GSU. Although efficient, existing algorithms mostly suffer from a crucial limitation: the \textit{inconsistent} target-behavior relevance metrics between GSU and ESU. As a result, their GSU usually misses highly relevant behaviors but retrieves ones considered irrelevant by ESU. In such case, the TA in ESU, no matter how attention is allocated, mostly deviates from the real user interests and thus degrades the overall CTR prediction accuracy. To address such inconsistency, we propose \textbf{TWo-stage Interest Network (TWIN)}, where our Consistency-Preserved GSU (CP-GSU) adopts the identical target-behavior relevance metric as the TA in ESU, making the two stages twins. Specifically, to break TA's computational bottleneck and extend it from ESU to GSU, or namely from behavior length $10^2$ to length $10^4-10^5$, we build a novel attention mechanism by behavior feature splitting. For the video inherent features of a behavior, we calculate their linear projection by efficient pre-computing \& caching strategies. And for the user-item cross features, we compress each into a one-dimentional bias term in the attention score calculation to save the computational cost. The consistency between two stages, together with the effective TA-based relevance metric in CP-GSU, contributes to significant performance gain in CTR prediction.
PEPNet: Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information
Feb 05, 2023With the increase of content pages and display styles in online services such as online-shopping and video-watching websites, industrial-scale recommender systems face challenges in multi-domain and multi-task recommendations. The core of multi-task and multi-domain recommendation is to accurately capture user interests in different domains given different user behaviors. In this paper, we propose a plug-and-play \textit{\textbf{P}arameter and \textbf{E}mbedding \textbf{P}ersonalized \textbf{Net}work (\textbf{PEPNet})} for multi-task recommendation in the multi-domain setting. PEPNet takes features with strong biases as input and dynamically scales the bottom-layer embeddings and the top-layer DNN hidden units in the model through a gate mechanism. By mapping personalized priors to scaling weights ranging from 0 to 2, PEPNet introduces both parameter personalization and embedding personalization. Embedding Personalized Network (EPNet) selects and aligns embeddings with different semantics under multiple domains. Parameter Personalized Network (PPNet) influences DNN parameters to balance interdependent targets in multiple tasks. We have made a series of special engineering optimizations combining the Kuaishou training framework and the online deployment environment. We have deployed the model in Kuaishou apps, serving over 300 million daily users. Both online and offline experiments have demonstrated substantial improvements in multiple metrics. In particular, we have seen a more than 1\% online increase in three major scenarios.
When Multi-Level Meets Multi-Interest: A Multi-Grained Neural Model for Sequential Recommendation
May 03, 2022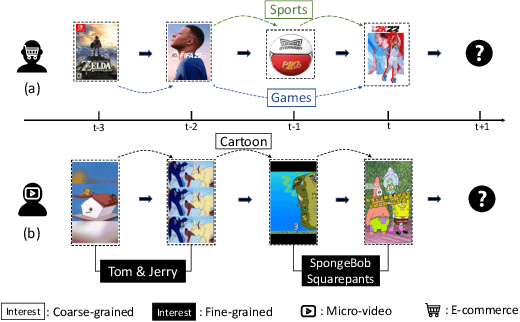
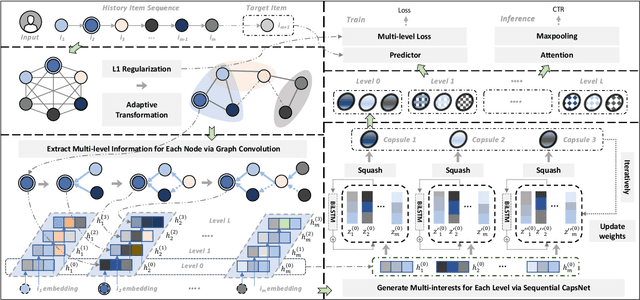
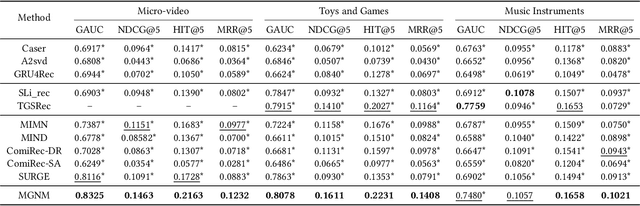
Sequential recommendation aims at identifying the next item that is preferred by a user based on their behavioral history. Compared to conventional sequential models that leverage attention mechanisms and RNNs, recent efforts mainly follow two directions for improvement: multi-interest learning and graph convolutional aggregation. Specifically, multi-interest methods such as ComiRec and MIMN, focus on extracting different interests for a user by performing historical item clustering, while graph convolution methods including TGSRec and SURGE elect to refine user preferences based on multi-level correlations between historical items. Unfortunately, neither of them realizes that these two types of solutions can mutually complement each other, by aggregating multi-level user preference to achieve more precise multi-interest extraction for a better recommendation. To this end, in this paper, we propose a unified multi-grained neural model(named MGNM) via a combination of multi-interest learning and graph convolutional aggregation. Concretely, MGNM first learns the graph structure and information aggregation paths of the historical items for a user. It then performs graph convolution to derive item representations in an iterative fashion, in which the complex preferences at different levels can be well captured. Afterwards, a novel sequential capsule network is proposed to inject the sequential patterns into the multi-interest extraction process, leading to a more precise interest learning in a multi-grained manner.