 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the generalization of drug target affinity prediction algorithms via similarity aware evaluation
Apr 13, 2025Drug-target binding affinity prediction is a fundamental task for drug discovery. It has been extensively explored in literature and promising results are reported. However, in this paper, we demonstrate that the results may be misleading and cannot be well generalized to real practice. The core observation is that the canonical randomized split of a test set in conventional evaluation leaves the test set dominated by samples with high similarity to the training set. The performance of models is severely degraded on samples with lower similarity to the training set but the drawback is highly overlooked in current evaluation. As a result, the performance can hardly be trusted when the model meets low-similarity samples in real practice. To address this problem, we propose a framework of similarity aware evaluation in which a novel split methodology is proposed to adapt to any desired distribution. This is achieved by a formulation of optimization problems which are approximately and efficiently solved by gradient descent. We perform extensive experiments across five representative methods in four datasets for two typical target evaluations and compare them with various counterpart methods. Results demonstrate that the proposed split methodology can significantly better fit desired distributions and guide the development of models. Code is released at https://github.com/Amshoreline/SAE/tree/main.
TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou
Jul 23, 2024



The significance of modeling long-term user interests for CTR prediction tasks in large-scale recommendation systems is progressively gaining attention among researchers and practitioners. Existing work, such as SIM and TWIN, typically employs a two-stage approach to model long-term user behavior sequences for efficiency concerns. The first stage rapidly retrieves a subset of sequences related to the target item from a long sequence using a search-based mechanism namely the General Search Unit (GSU), while the second stage calculates the interest scores using the Exact Search Unit (ESU) on the retrieved results. Given the extensive length of user behavior sequences spanning the entire life cycle, potentially reaching up to 10^6 in scale, there is currently no effective solution for fully modeling such expansive user interests. To overcome this issue, we introduced TWIN-V2, an enhancement of TWIN, where a divide-and-conquer approach is applied to compress life-cycle behaviors and uncover more accurate and diverse user interests. Specifically, a hierarchical clustering method groups items with similar characteristics in life-cycle behaviors into a single cluster during the offline phase. By limiting the size of clusters, we can compress behavior sequences well beyond the magnitude of 10^5 to a length manageable for online inference in GSU retrieval. Cluster-aware target attention extracts comprehensive and multi-faceted long-term interests of users, thereby making the final recommendation results more accurate and diverse. Extensive offline experiments on a multi-billion-scale industrial dataset and online A/B tests have demonstrated the effectiveness of TWIN-V2. Under an efficient deployment framework, TWIN-V2 has been successfully deployed to the primary traffic that serves hundreds of millions of daily active users at Kuaishou.
Two-shot Video Object Segmentation
Mar 21, 2023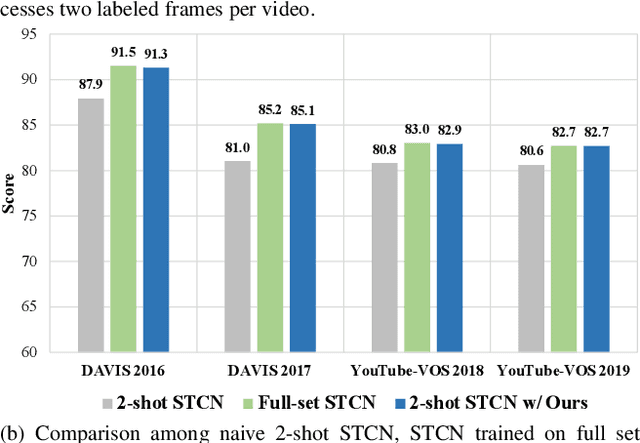
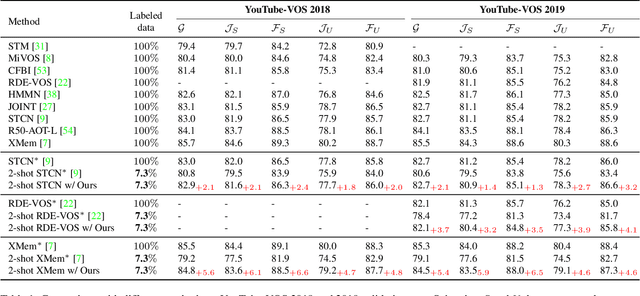
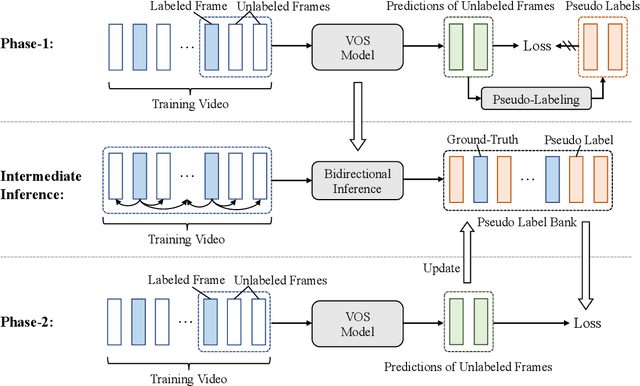
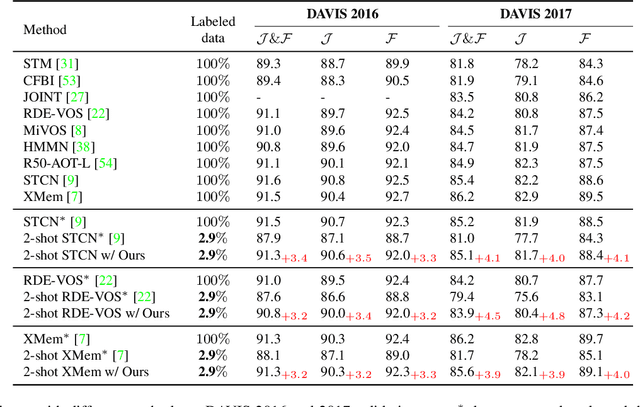
Previous works on video object segmentation (VOS) are trained on densely annotated videos. Nevertheless, acquiring annotations in pixel level is expensive and time-consuming. In this work, we demonstrate the feasibility of training a satisfactory VOS model on sparsely annotated videos-we merely require two labeled frames per training video while the performance is sustained. We term this novel training paradigm as two-shot video object segmentation, or two-shot VOS for short. The underlying idea is to generate pseudo labels for unlabeled frames during training and to optimize the model on the combination of labeled and pseudo-labeled data. Our approach is extremely simple and can be applied to a majority of existing frameworks. We first pre-train a VOS model on sparsely annotated videos in a semi-supervised manner, with the first frame always being a labeled one. Then, we adopt the pre-trained VOS model to generate pseudo labels for all unlabeled frames, which are subsequently stored in a pseudo-label bank. Finally, we retrain a VOS model on both labeled and pseudo-labeled data without any restrictions on the first frame. For the first time, we present a general way to train VOS models on two-shot VOS datasets. By using 7.3% and 2.9% labeled data of YouTube-VOS and DAVIS benchmarks, our approach achieves comparable results in contrast to the counterparts trained on fully labeled set. Code and models are available at https://github.com/yk-pku/Two-shot-Video-Object-Segmentation.
TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou
Feb 05, 2023Life-long user behavior modeling, i.e., extracting a user's hidden interests from rich historical behaviors in months or even years, plays a central role in modern CTR prediction systems. Conventional algorithms mostly follow two cascading stages: a simple General Search Unit (GSU) for fast and coarse search over tens of thousands of long-term behaviors and an Exact Search Unit (ESU) for effective Target Attention (TA) over the small number of finalists from GSU. Although efficient, existing algorithms mostly suffer from a crucial limitation: the \textit{inconsistent} target-behavior relevance metrics between GSU and ESU. As a result, their GSU usually misses highly relevant behaviors but retrieves ones considered irrelevant by ESU. In such case, the TA in ESU, no matter how attention is allocated, mostly deviates from the real user interests and thus degrades the overall CTR prediction accuracy. To address such inconsistency, we propose \textbf{TWo-stage Interest Network (TWIN)}, where our Consistency-Preserved GSU (CP-GSU) adopts the identical target-behavior relevance metric as the TA in ESU, making the two stages twins. Specifically, to break TA's computational bottleneck and extend it from ESU to GSU, or namely from behavior length $10^2$ to length $10^4-10^5$, we build a novel attention mechanism by behavior feature splitting. For the video inherent features of a behavior, we calculate their linear projection by efficient pre-computing \& caching strategies. And for the user-item cross features, we compress each into a one-dimentional bias term in the attention score calculation to save the computational cost. The consistency between two stages, together with the effective TA-based relevance metric in CP-GSU, contributes to significant performance gain in CTR prediction.
PEPNet: Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information
Feb 05, 2023With the increase of content pages and display styles in online services such as online-shopping and video-watching websites, industrial-scale recommender systems face challenges in multi-domain and multi-task recommendations. The core of multi-task and multi-domain recommendation is to accurately capture user interests in different domains given different user behaviors. In this paper, we propose a plug-and-play \textit{\textbf{P}arameter and \textbf{E}mbedding \textbf{P}ersonalized \textbf{Net}work (\textbf{PEPNet})} for multi-task recommendation in the multi-domain setting. PEPNet takes features with strong biases as input and dynamically scales the bottom-layer embeddings and the top-layer DNN hidden units in the model through a gate mechanism. By mapping personalized priors to scaling weights ranging from 0 to 2, PEPNet introduces both parameter personalization and embedding personalization. Embedding Personalized Network (EPNet) selects and aligns embeddings with different semantics under multiple domains. Parameter Personalized Network (PPNet) influences DNN parameters to balance interdependent targets in multiple tasks. We have made a series of special engineering optimizations combining the Kuaishou training framework and the online deployment environment. We have deployed the model in Kuaishou apps, serving over 300 million daily users. Both online and offline experiments have demonstrated substantial improvements in multiple metrics. In particular, we have seen a more than 1\% online increase in three major scenarios.
Inferring Prototypes for Multi-Label Few-Shot Image Classification with Word Vector Guided Attention
Dec 07, 2021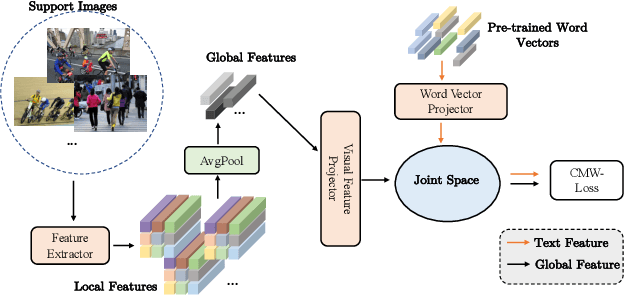
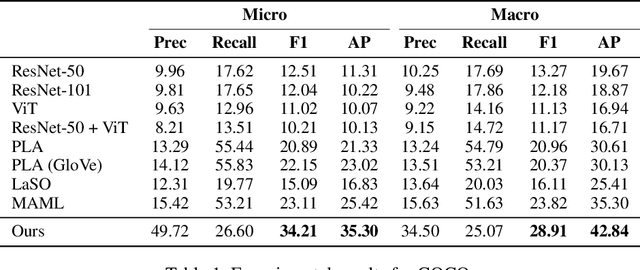
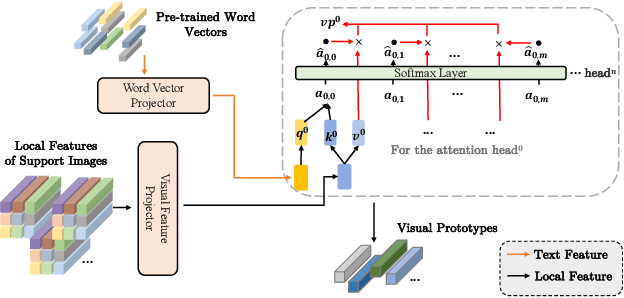
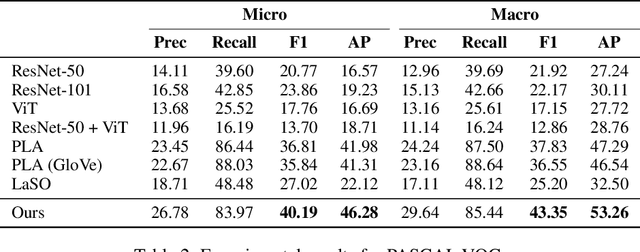
Multi-label few-shot image classification (ML-FSIC) is the task of assigning descriptive labels to previously unseen images, based on a small number of training examples. A key feature of the multi-label setting is that images often have multiple labels, which typically refer to different regions of the image. When estimating prototypes, in a metric-based setting, it is thus important to determine which regions are relevant for which labels, but the limited amount of training data makes this highly challenging. As a solution, in this paper we propose to use word embeddings as a form of prior knowledge about the meaning of the labels. In particular, visual prototypes are obtained by aggregating the local feature maps of the support images, using an attention mechanism that relies on the label embeddings. As an important advantage, our model can infer prototypes for unseen labels without the need for fine-tuning any model parameters, which demonstrates its strong generalization abilities. Experiments on COCO and PASCAL VOC furthermore show that our model substantially improves the current state-of-the-art.
Large-scale Gastric Cancer Screening and Localization Using Multi-task Deep Neural Network
Oct 12, 2019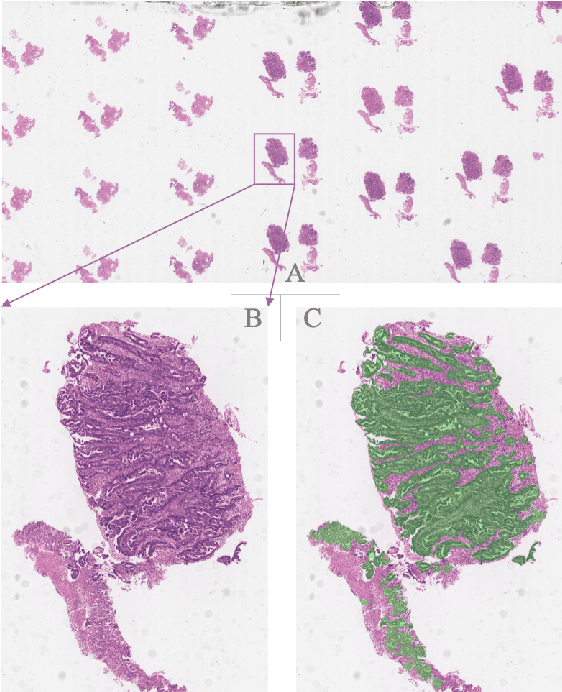
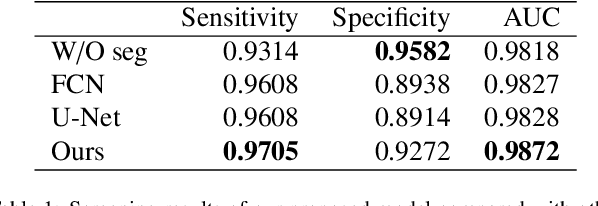
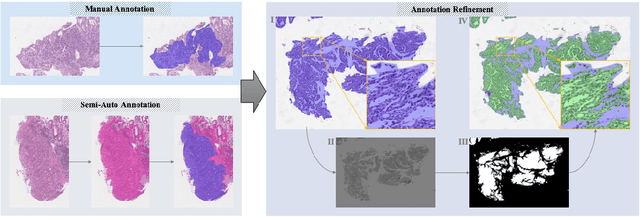
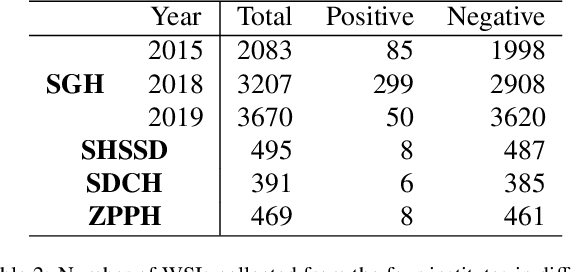
Gastric cancer is one of the most common cancers, which ranks third among the leading causes of cancer death. Biopsy of gastric mucosal is a standard procedure in gastric cancer screening test. However, manual pathological inspection is labor-intensive and time-consuming. Besides, it is challenging for an automated algorithm to locate the small lesion regions in the gigapixel whole-slide image and make the decision correctly. To tackle these issues, we collected large-scale whole-slide image dataset with detailed lesion region annotation and designed a whole-slide image analyzing framework consisting of 3 networks which could not only determine the screen result but also present the suspicious areas to the pathologist for reference. Experiments demonstrated that our proposed framework achieves sensitivity of 97.05% and specificity of 92.72% in screening task and Dice coefficient of 0.8331 in segmentation task. Furthermore, we tested our best model in real-world scenario on 10, 316 whole-slide images collected from 4 medical centers.
Additive Adversarial Learning for Unbiased Authentication
May 28, 2019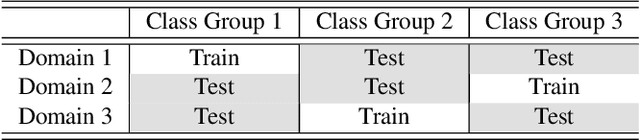
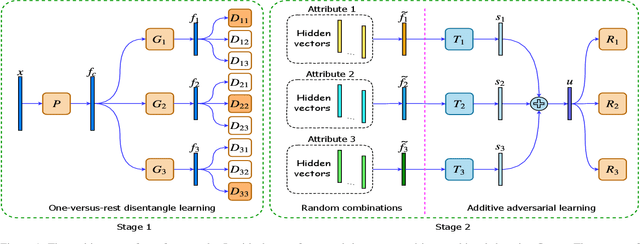

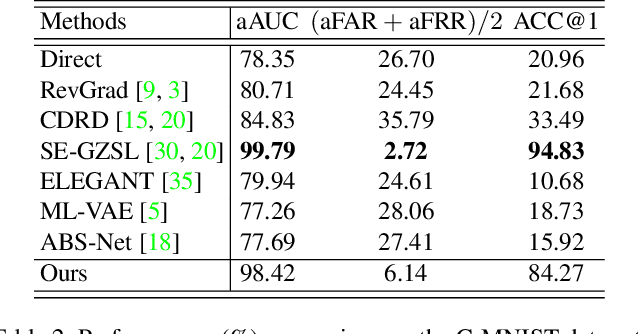
Authentication is a task aiming to confirm the truth between data instances and personal identities. Typical authentication applications include face recognition, person re-identification, authentication based on mobile devices and so on. The recently-emerging data-driven authentication process may encounter undesired biases, i.e., the models are often trained in one domain (e.g., for people wearing spring outfits) while required to apply in other domains (e.g., they change the clothes to summer outfits). To address this issue, we propose a novel two-stage method that disentangles the class/identity from domain-differences, and we consider multiple types of domain-difference. In the first stage, we learn disentangled representations by a one-versus-rest disentangle learning (OVRDL) mechanism. In the second stage, we improve the disentanglement by an additive adversarial learning (AAL) mechanism. Moreover, we discuss the necessity to avoid a learning dilemma due to disentangling causally related types of domain-difference. Comprehensive evaluation results demonstrate the effectiveness and superiority of the proposed method.
Quantum robot: structure, algorithms and applications
Oct 25, 2008



This paper has been withdrawn.