 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERMAID: Memory-Enhanced Retrieval and Reasoning with Multi-Agent Iterative Knowledge Grounding for Veracity Assessment
Jan 29, 2026Assessing the veracity of online content has become increasingly critical. Large language models (LLMs) have recently enabled substantial progress in automated veracity assessment, including automated fact-checking and claim verification systems. Typical veracity assessment pipelines break down complex claims into sub-claims, retrieve external evidence, and then apply LLM reasoning to assess veracity. However, existing methods often treat evidence retrieval as a static, isolated step and do not effectively manage or reuse retrieved evidence across claims. In this work, we propose MERMAID, a memory-enhanced multi-agent veracity assessment framework that tightly couples the retrieval and reasoning processes. MERMAID integrates agent-driven search, structured knowledge representations, and a persistent memory module within a Reason-Action style iterative process, enabling dynamic evidence acquisition and cross-claim evidence reuse. By retaining retrieved evidence in an evidence memory, the framework reduces redundant searches and improves verification efficiency and consistency. We evaluate MERMAID on three fact-checking benchmarks and two claim-verification datasets using multiple LLMs, including GPT, LLaMA, and Qwen families. Experimental results show that MERMAID achieves state-of-the-art performance while improving the search efficiency, demonstrating the effectiveness of synergizing retrieval, reasoning, and memory for reliable veracity assessment.
PulseMind: A Multi-Modal Medical Model for Real-World Clinical Diagnosis
Jan 12, 2026Recent advances in medical multi-modal models focus on specialized image analysis like dermatology, pathology, or radiology. However, they do not fully capture the complexity of real-world clinical diagnostics, which involve heterogeneous inputs and require ongoing contextual understanding during patient-physician interactions. To bridge this gap, we introduce PulseMind, a new family of multi-modal diagnostic models that integrates a systematically curated dataset, a comprehensive evaluation benchmark, and a tailored training framework. Specifically, we first construct a diagnostic dataset, MediScope, which comprises 98,000 real-world multi-turn consultations and 601,500 medical images, spanning over 10 major clinical departments and more than 200 sub-specialties. Then, to better reflect the requirements of real-world clinical diagnosis, we develop the PulseMind Benchmark, a multi-turn diagnostic consultation benchmark with a four-dimensional evaluation protocol comprising proactiveness, accuracy, usefulness, and language quality. Finally, we design a training framework tailored for multi-modal clinical diagnostics, centered around a core component named Comparison-based Reinforcement Policy Optimization (CRPO). Compared to absolute score rewards, CRPO uses relative preference signals from multi-dimensional com-parisons to provide stable and human-aligned training guidance. Extensive experiments demonstrate that PulseMind achieves competitive performance on both the diagnostic consultation benchmark and public medical benchmarks.
SongSage: A Large Musical Language Model with Lyric Generative Pre-training
Jan 03, 2026Large language models have achieved significant success in various domains, yet their understanding of lyric-centric knowledge has not been fully explored. In this work, we first introduce PlaylistSense, a dataset to evaluate the playlist understanding capability of language models. PlaylistSense encompasses ten types of user queries derived from common real-world perspectives, challenging LLMs to accurately grasp playlist features and address diverse user intents. Comprehensive evaluations indicate that current general-purpose LLMs still have potential for improvement in playlist understanding. Inspired by this, we introduce SongSage, a large musical language model equipped with diverse lyric-centric intelligence through lyric generative pretraining. SongSage undergoes continual pretraining on LyricBank, a carefully curated corpus of 5.48 billion tokens focused on lyrical content, followed by fine-tuning with LyricBank-SFT, a meticulously crafted instruction set comprising 775k samples across nine core lyric-centric tasks. Experimental results demonstrate that SongSage exhibits a strong understanding of lyric-centric knowledge, excels in rewriting user queries for zero-shot playlist recommendations, generates and continues lyrics effectively, and performs proficiently across seven additional capabilities. Beyond its lyric-centric expertise, SongSage also retains general knowledge comprehension and achieves a competitive MMLU score. We will keep the datasets inaccessible due to copyright restrictions and release the SongSage and training script to ensure reproducibility and support music AI research and applications, the datasets release plan details are provided in the appendix.
Unleashing Degradation-Carrying Features in Symmetric U-Net: Simpler and Stronger Baselines for All-in-One Image Restoration
Dec 11, 2025All-in-one image restoration aims to handle diverse degradations (e.g., noise, blur, adverse weather) within a unified framework, yet existing methods increasingly rely on complex architectures (e.g., Mixture-of-Experts, diffusion models) and elaborate degradation prompt strategies. In this work, we reveal a critical insight: well-crafted feature extraction inherently encodes degradation-carrying information, and a symmetric U-Net architecture is sufficient to unleash these cues effectively. By aligning feature scales across encoder-decoder and enabling streamlined cross-scale propagation, our symmetric design preserves intrinsic degradation signals robustly, rendering simple additive fusion in skip connections sufficient for state-of-the-art performance. Our primary baseline, SymUNet, is built on this symmetric U-Net and achieves better results across benchmark datasets than existing approaches while reducing computational cost. We further propose a semantic enhanced variant, SE-SymUNet, which integrates direct semantic injection from frozen CLIP features via simple cross-attention to explicitly amplify degradation priors. Extensive experiments on several benchmarks validate the superiority of our methods. Both baselines SymUNet and SE-SymUNet establish simpler and stronger foundations for future advancements in all-in-one image restoration. The source code is available at https://github.com/WenlongJiao/SymUNet.
End-to-end Contrastive Language-Speech Pretraining Model For Long-form Spoken Question Answering
Nov 12, 2025Significant progress has been made in spoken question answering (SQA) in recent years. However, many existing methods, including large audio language models, struggle with processing long audio. Follow the success of retrieval augmented generation, a speech-related retriever shows promising in help preprocessing long-form speech. But the performance of existing speech-related retrievers is lacking. To address this challenge, we propose CLSR, an end-to-end contrastive language-speech retriever that efficiently extracts question-relevant segments from long audio recordings for downstream SQA task. Unlike conventional speech-text contrastive models, CLSR incorporates an intermediate step that converts acoustic features into text-like representations prior to alignment, thereby more effectively bridging the gap between modalities. Experimental results across four cross-modal retrieval datasets demonstrate that CLSR surpasses both end-to-end speech related retrievers and pipeline approaches combining speech recognition with text retrieval, providing a robust foundation for advancing practical long-form SQA applications.
Performance Analysis of End-to-End LEO Satellite-Aided Shore-to-Ship Communications: A Stochastic Geometry Approach
Oct 23, 2025Low Earth orbit (LEO) satellite networks have shown strategic superiority in maritime communications, assisting in establishing signal transmissions from shore to ship through space-based links. Traditional performance modeling based on multiple circular orbits is challenging to characterize large-scale LEO satellite constellations, thus requiring a tractable approach to accurately evaluate the network performance. In this paper, we propose a theoretical framework for an LEO satellite-aided shore-to-ship communication network (LEO-SSCN), where LEO satellites are distributed as a binomial point process (BPP) on a specific spherical surface. The framework aims to obtain the end-to-end transmission performance by considering signal transmissions through either a marine link or a space link subject to Rician or Shadowed Rician fading, respectively. Due to the indeterminate position of the serving satellite, accurately modeling the distance from the serving satellite to the destination ship becomes intractable. To address this issue, we propose a distance approximation approach. Then, by approximation and incorporating a threshold-based communication scheme, we leverage stochastic geometry to derive analytical expressions of end-to-end transmission success probability and average transmission rate capacity. Extensive numerical results verify the accuracy of the analysis and demonstrate the effect of key parameters on the performance of LEO-SSCN.
A Secure Affine Frequency Division Multiplexing for Wireless Communication Systems
Oct 02, 2025Affine frequency division multiplexing (AFDM) has garnered significant attention due to its superior performance in high-mobility scenarios, coupled with multiple waveform parameters that provide greater degrees of freedom for system design. This paper introduces a novel secure affine frequency division multiplexing (SE-AFDM) system, which advances prior designs by dynamically varying an AFDM pre-chirp parameter to enhance physical-layer security. In the SE-AFDM system, the pre-chirp parameter is dynamically generated from a codebook controlled by a long-period pseudo-noise (LPPN) sequence. Instead of applying spreading in the data domain, our parameter-domain spreading approach provides additional security while maintaining reliability and high spectrum efficiency. We also propose a synchronization framework to solve the problem of reliably and rapidly synchronizing the time-varying parameter in fast time-varying channels. The theoretical derivations prove that unsynchronized eavesdroppers cannot eliminate the nonlinear impact of the time-varying parameter and further provide useful guidance for codebook design. Simulation results demonstrate the security advantages of the proposed SE-AFDM system in high-mobility scenarios, while our hardware prototype validates the effectiveness of the proposed synchronization framework.
Plug-and-play Diffusion Models for Image Compressive Sensing with Data Consistency Projection
Sep 11, 2025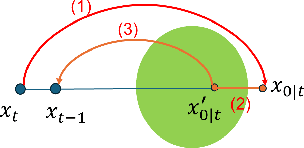
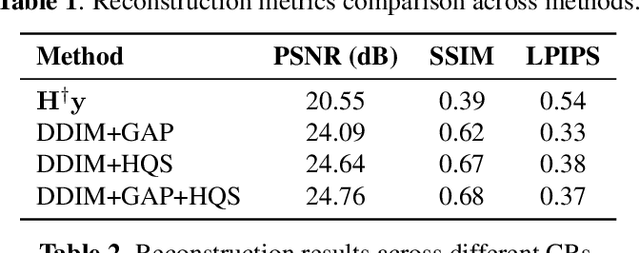

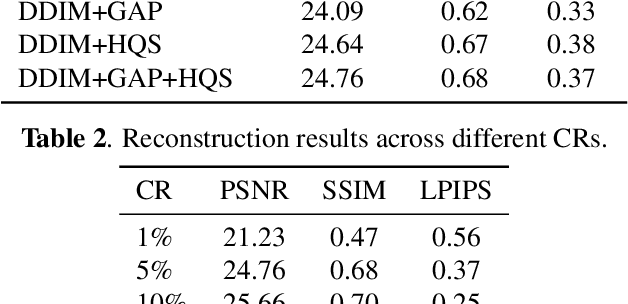
We explore the connection between Plug-and-Play (PnP) methods and Denoising Diffusion Implicit Models (DDIM) for solving ill-posed inverse problems, with a focus on single-pixel imaging. We begin by identifying key distinctions between PnP and diffusion models-particularly in their denoising mechanisms and sampling procedures. By decoupling the diffusion process into three interpretable stages: denoising, data consistency enforcement, and sampling, we provide a unified framework that integrates learned priors with physical forward models in a principled manner. Building upon this insight, we propose a hybrid data-consistency module that linearly combines multiple PnP-style fidelity terms. This hybrid correction is applied directly to the denoised estimate, improving measurement consistency without disrupting the diffusion sampling trajectory. Experimental results on single-pixel imaging tasks demonstrate that our method achieves better reconstruction quality.
High-Speed FHD Full-Color Video Computer-Generated Holography
Aug 27, 2025Computer-generated holography (CGH) is a promising technology for next-generation displays. However, generating high-speed, high-quality holographic video requires both high frame rate display and efficient computation, but is constrained by two key limitations: ($i$) Learning-based models often produce over-smoothed phases with narrow angular spectra, causing severe color crosstalk in high frame rate full-color displays such as depth-division multiplexing and thus resulting in a trade-off between frame rate and color fidelity. ($ii$) Existing frame-by-frame optimization methods typically optimize frames independently, neglecting spatial-temporal correlations between consecutive frames and leading to computationally inefficient solutions. To overcome these challenges, in this paper, we propose a novel high-speed full-color video CGH generation scheme. First, we introduce Spectrum-Guided Depth Division Multiplexing (SGDDM), which optimizes phase distributions via frequency modulation, enabling high-fidelity full-color display at high frame rates. Second, we present HoloMamba, a lightweight asymmetric Mamba-Unet architecture that explicitly models spatial-temporal correlations across video sequences to enhance reconstruction quality and computational efficiency. Extensive simulated and real-world experiments demonstrate that SGDDM achieves high-fidelity full-color display without compromise in frame rate, while HoloMamba generates FHD (1080p) full-color holographic video at over 260 FPS, more than 2.6$\times$ faster than the prior state-of-the-art Divide-Conquer-and-Merge Strategy.
SpindleKV: A Novel KV Cache Reduction Method Balancing Both Shallow and Deep Layers
Jul 09, 2025Large Language Models (LLMs) have achieved impressive accomplishments in recent years. However, the increasing memory consumption of KV cache has possessed a significant challenge to the inference system. Eviction methods have revealed the inherent redundancy within the KV cache, demonstrating its potential for reduction, particularly in deeper layers. However, KV cache reduction for shallower layers has been found to be insufficient. Based on our observation that, the KV cache exhibits a high degree of similarity. Based on this observation, we proposed a novel KV cache reduction method, SpindleKV, which balances both shallow and deep layers. For deep layers, we employ an attention weight based eviction method, while for shallow layers, we apply a codebook based replacement approach which is learnt by similarity and merging policy. Moreover, SpindleKV addressed the Grouped-Query Attention (GQA) dilemma faced by other attention based eviction methods. Experiments on two common benchmarks with three different LLMs shown that SpindleKV obtained better KV cache reduction effect compared to baseline methods, while preserving similar or even better model performance.