 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM Machine Unlearning via Visual Knowledge Distillation
Dec 12, 2025Recently, machine unlearning approaches have been proposed to remove sensitive information from well-trained large models. However, most existing methods are tailored for LLMs, while MLLM-oriented unlearning remains at its early stage. Inspired by recent studies exploring the internal mechanisms of MLLMs, we propose to disentangle the visual and textual knowledge embedded within MLLMs and introduce a dedicated approach to selectively erase target visual knowledge while preserving textual knowledge. Unlike previous unlearning methods that rely on output-level supervision, our approach introduces a Visual Knowledge Distillation (VKD) scheme, which leverages intermediate visual representations within the MLLM as supervision signals. This design substantially enhances both unlearning effectiveness and model utility. Moreover, since our method only fine-tunes the visual components of the MLLM, it offers significant efficiency advantages. Extensive experiments demonstrate that our approach outperforms state-of-the-art unlearning methods in terms of both effectiveness and efficiency. Moreover, we are the first to evaluate the robustness of MLLM unlearning against relearning attacks.
Whispers of Data: Unveiling Label Distributions in Federated Learning Through Virtual Client Simulation
Apr 30, 2025



Federated Learning enables collaborative training of a global model across multiple geographically dispersed clients without the need for data sharing. However, it is susceptible to inference attacks, particularly label inference attacks. Existing studies on label distribution inference exhibits sensitive to the specific settings of the victim client and typically underperforms under defensive strategies. In this study, we propose a novel label distribution inference attack that is stable and adaptable to various scenarios. Specifically, we estimate the size of the victim client's dataset and construct several virtual clients tailored to the victim client. We then quantify the temporal generalization of each class label for the virtual clients and utilize the variation in temporal generalization to train an inference model that predicts the label distribution proportions of the victim client. We validate our approach on multiple datasets, including MNIST, Fashion-MNIST, FER2013, and AG-News. The results demonstrate the superiority of our method compared to state-of-the-art techniques. Furthermore, our attack remains effective even under differential privacy defense mechanisms, underscoring its potential for real-world applications.
HumorReject: Decoupling LLM Safety from Refusal Prefix via A Little Humor
Jan 23, 2025

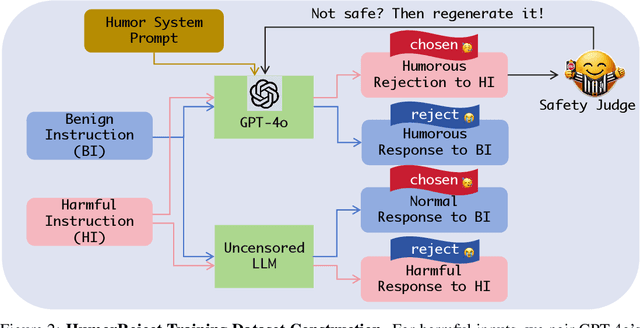
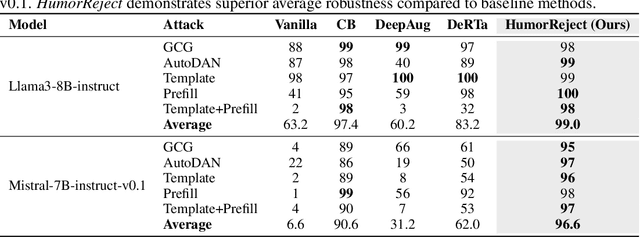
Large Language Models (LLMs) commonly rely on explicit refusal prefixes for safety, making them vulnerable to prefix injection attacks. We introduce HumorReject, a novel data-driven approach that fundamentally reimagines LLM safety by decoupling it from refusal prefixes through the use of humor as an indirect refusal strategy. Rather than explicitly rejecting harmful instructions, HumorReject responds with contextually appropriate humor that naturally defuses potentially dangerous requests while maintaining engaging interactions. Our approach effectively addresses the common "over-defense" issues in existing safety mechanisms, demonstrating superior robustness against various attack vectors while preserving natural and high-quality interactions on legitimate tasks. Our findings suggest that innovations at the data level are even more fundamental than the alignment algorithm itself in achieving effective LLM safety, opening new directions for developing more resilient and user-friendly AI systems.
Mining Glitch Tokens in Large Language Models via Gradient-based Discrete Optimization
Oct 19, 2024
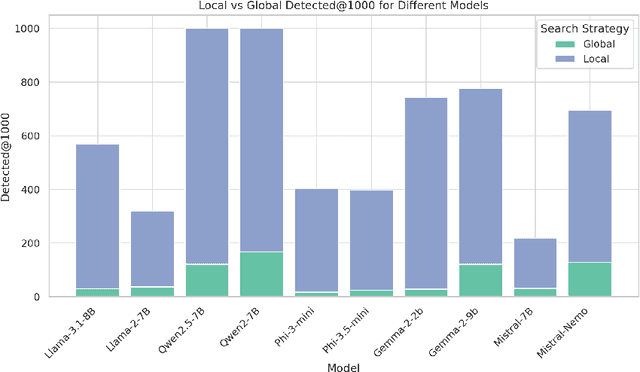
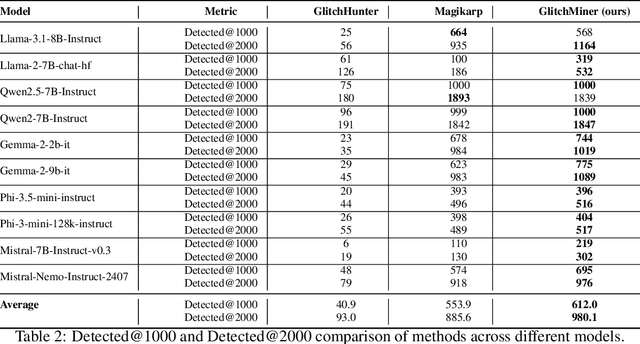
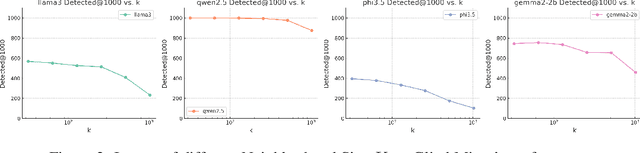
Glitch tokens in Large Language Models (LLMs) can trigger unpredictable behaviors, compromising model reliability and safety. Existing detection methods often rely on manual observation to infer the prior distribution of glitch tokens, which is inefficient and lacks adaptability across diverse model architectures. To address these limitations, we introduce GlitchMiner, a gradient-based discrete optimization framework designed for efficient glitch token detection in LLMs. GlitchMiner leverages an entropy-based loss function to quantify the uncertainty in model predictions and integrates first-order Taylor approximation with a local search strategy to effectively explore the token space. Our evaluation across various mainstream LLM architectures demonstrates that GlitchMiner surpasses existing methods in both detection precision and adaptability. In comparison to the previous state-of-the-art, GlitchMiner achieves an average improvement of 19.07% in precision@1000 for glitch token detection. By enabling efficient detection of glitch tokens, GlitchMiner provides a valuable tool for assessing and mitigating potential vulnerabilities in LLMs, contributing to their overall security.
The Dark Side of Function Calling: Pathways to Jailbreaking Large Language Models
Jul 25, 2024



Large language models (LLMs) have demonstrated remarkable capabilities, but their power comes with significant security considerations. While extensive research has been conducted on the safety of LLMs in chat mode, the security implications of their function calling feature have been largely overlooked. This paper uncovers a critical vulnerability in the function calling process of LLMs, introducing a novel "jailbreak function" attack method that exploits alignment discrepancies, user coercion, and the absence of rigorous safety filters. Our empirical study, conducted on six state-of-the-art LLMs including GPT-4o, Claude-3.5-Sonnet, and Gemini-1.5-pro, reveals an alarming average success rate of over 90\% for this attack. We provide a comprehensive analysis of why function calls are susceptible to such attacks and propose defensive strategies, including the use of defensive prompts. Our findings highlight the urgent need for enhanced security measures in the function calling capabilities of LLMs, contributing to the field of AI safety by identifying a previously unexplored risk, designing an effective attack method, and suggesting practical defensive measures. Our code is available at https://github.com/wooozihui/jailbreakfunction.
SoK: Acoustic Side Channels
Aug 06, 2023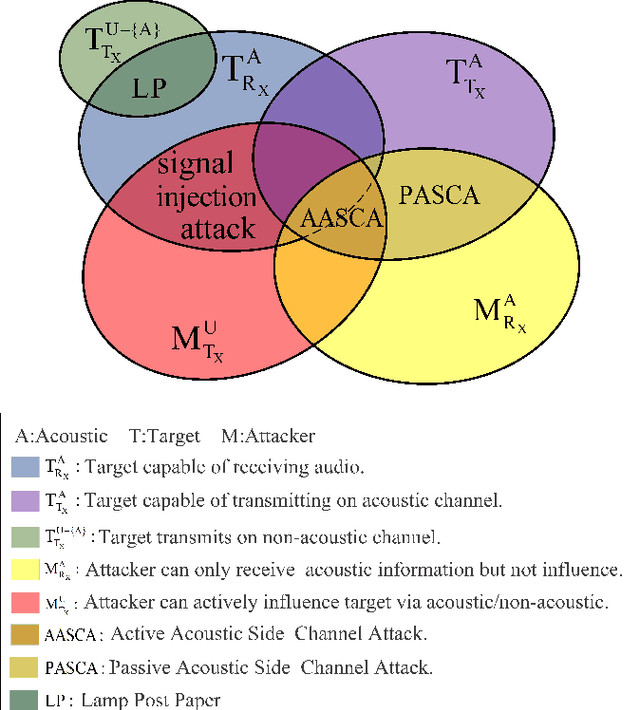

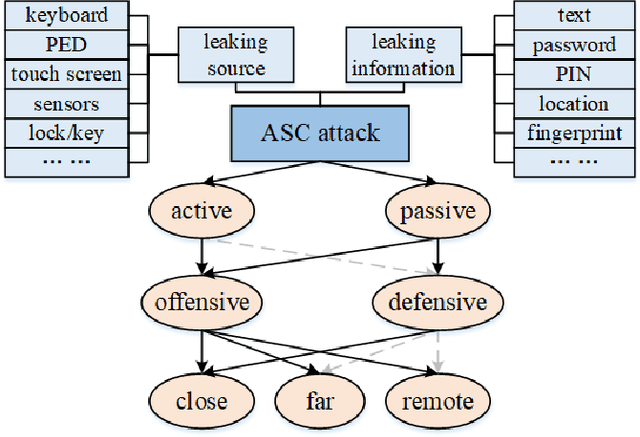

We provide a state-of-the-art analysis of acoustic side channels, cover all the significant academic research in the area, discuss their security implications and countermeasures, and identify areas for future research. We also make an attempt to bridge side channels and inverse problems, two fields that appear to be completely isolated from each other but have deep connections.
AdvFunMatch: When Consistent Teaching Meets Adversarial Robustness
May 25, 2023

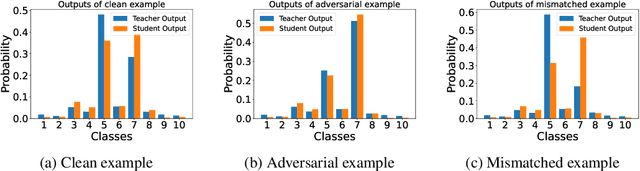
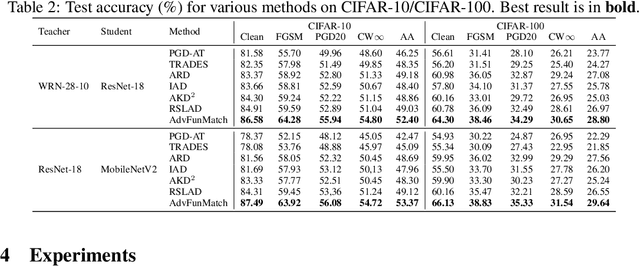
\emph{Consistent teaching} is an effective paradigm for implementing knowledge distillation (KD), where both student and teacher models receive identical inputs, and KD is treated as a function matching task (FunMatch). However, one limitation of FunMatch is that it does not account for the transfer of adversarial robustness, a model's resistance to adversarial attacks. To tackle this problem, we propose a simple but effective strategy called Adversarial Function Matching (AdvFunMatch), which aims to match distributions for all data points within the $\ell_p$-norm ball of the training data, in accordance with consistent teaching. Formulated as a min-max optimization problem, AdvFunMatch identifies the worst-case instances that maximizes the KL-divergence between teacher and student model outputs, which we refer to as "mismatched examples," and then matches the outputs on these mismatched examples. Our experimental results show that AdvFunMatch effectively produces student models with both high clean accuracy and robustness. Furthermore, we reveal that strong data augmentations (\emph{e.g.}, AutoAugment) are beneficial in AdvFunMatch, whereas prior works have found them less effective in adversarial training. Code is available at \url{https://gitee.com/zihui998/adv-fun-match}.
Lower Difficulty and Better Robustness: A Bregman Divergence Perspective for Adversarial Training
Aug 26, 2022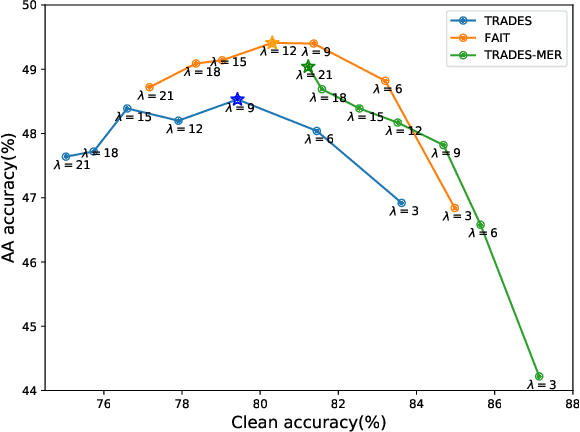
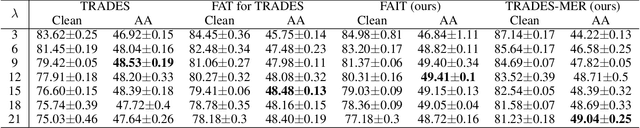
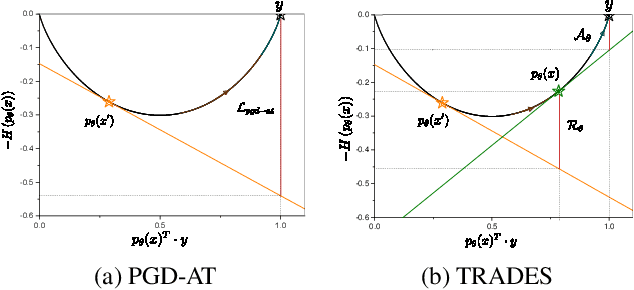
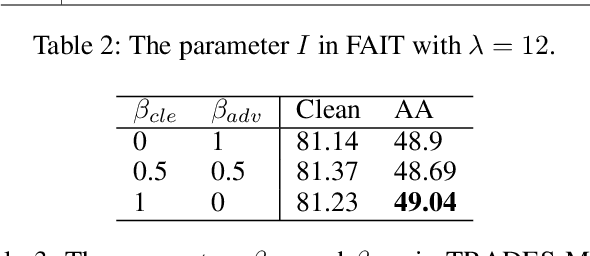
In this paper, we investigate on improving the adversarial robustness obtained in adversarial training (AT) via reducing the difficulty of optimization. To better study this problem, we build a novel Bregman divergence perspective for AT, in which AT can be viewed as the sliding process of the training data points on the negative entropy curve. Based on this perspective, we analyze the learning objectives of two typical AT methods, i.e., PGD-AT and TRADES, and we find that the optimization process of TRADES is easier than PGD-AT for that TRADES separates PGD-AT. In addition, we discuss the function of entropy in TRADES, and we find that models with high entropy can be better robustness learners. Inspired by the above findings, we propose two methods, i.e., FAIT and MER, which can both not only reduce the difficulty of optimization under the 10-step PGD adversaries, but also provide better robustness. Our work suggests that reducing the difficulty of optimization under the 10-step PGD adversaries is a promising approach for enhancing the adversarial robustness in AT.
Alleviating Robust Overfitting of Adversarial Training With Consistency Regularization
May 24, 2022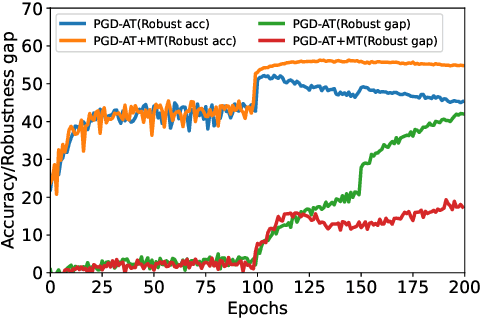
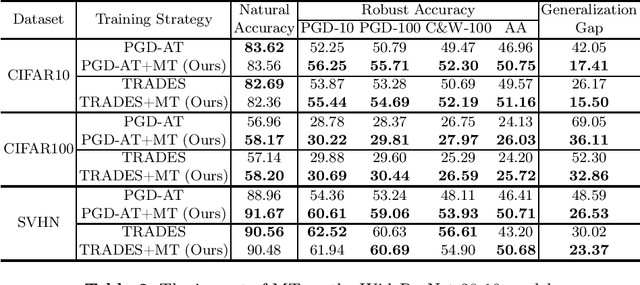


Adversarial training (AT) has proven to be one of the most effective ways to defend Deep Neural Networks (DNNs) against adversarial attacks. However, the phenomenon of robust overfitting, i.e., the robustness will drop sharply at a certain stage, always exists during AT. It is of great importance to decrease this robust generalization gap in order to obtain a robust model. In this paper, we present an in-depth study towards the robust overfitting from a new angle. We observe that consistency regularization, a popular technique in semi-supervised learning, has a similar goal as AT and can be used to alleviate robust overfitting. We empirically validate this observation, and find a majority of prior solutions have implicit connections to consistency regularization. Motivated by this, we introduce a new AT solution, which integrates the consistency regularization and Mean Teacher (MT) strategy into AT. Specifically, we introduce a teacher model, coming from the average weights of the student models over the training steps. Then we design a consistency loss function to make the prediction distribution of the student models over adversarial examples consistent with that of the teacher model over clean samples. Experiments show that our proposed method can effectively alleviate robust overfitting and improve the robustness of DNN models against common adversarial attacks.