 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepTSE: A Multi-model Ensemble Method for Probabilistic Time Series Forecasting
May 16, 2023



Various probabilistic time series forecasting models have sprung up and shown remarkably good performance. However, the choice of model highly relies on the characteristics of the input time series and the fixed distribution that the model is based on. Due to the fact that the probability distributions cannot be averaged over different models straightforwardly, the current time series model ensemble methods cannot be directly applied to improve the robustness and accuracy of forecasting. To address this issue, we propose pTSE, a multi-model distribution ensemble method for probabilistic forecasting based on Hidden Markov Model (HMM). pTSE only takes off-the-shelf outputs from member models without requiring further information about each model. Besides, we provide a complete theoretical analysis of pTSE to prove that the empirical distribution of time series subject to an HMM will converge to the stationary distribution almost surely. Experiments on benchmarks show the superiority of pTSE overall member models and competitive ensemble methods.
Alleviating Robust Overfitting of Adversarial Training With Consistency Regularization
May 24, 2022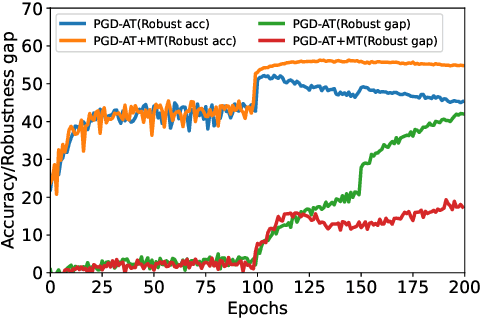
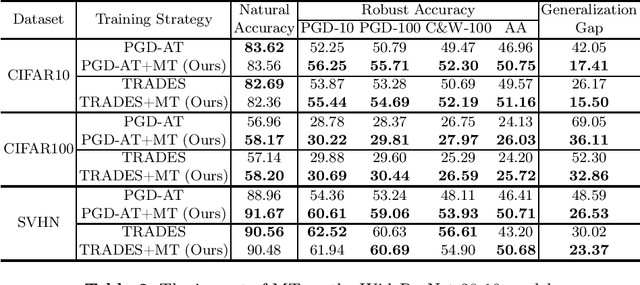


Adversarial training (AT) has proven to be one of the most effective ways to defend Deep Neural Networks (DNNs) against adversarial attacks. However, the phenomenon of robust overfitting, i.e., the robustness will drop sharply at a certain stage, always exists during AT. It is of great importance to decrease this robust generalization gap in order to obtain a robust model. In this paper, we present an in-depth study towards the robust overfitting from a new angle. We observe that consistency regularization, a popular technique in semi-supervised learning, has a similar goal as AT and can be used to alleviate robust overfitting. We empirically validate this observation, and find a majority of prior solutions have implicit connections to consistency regularization. Motivated by this, we introduce a new AT solution, which integrates the consistency regularization and Mean Teacher (MT) strategy into AT. Specifically, we introduce a teacher model, coming from the average weights of the student models over the training steps. Then we design a consistency loss function to make the prediction distribution of the student models over adversarial examples consistent with that of the teacher model over clean samples. Experiments show that our proposed method can effectively alleviate robust overfitting and improve the robustness of DNN models against common adversarial attacks.