 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible and Efficient Spatio-Temporal Transformer for Sequential Visual Place Recognition
Oct 05, 2025Sequential Visual Place Recognition (Seq-VPR) leverages transformers to capture spatio-temporal features effectively; however, existing approaches prioritize performance at the expense of flexibility and efficiency. In practice, a transformer-based Seq-VPR model should be flexible to the number of frames per sequence (seq-length), deliver fast inference, and have low memory usage to meet real-time constraints. To our knowledge, no existing transformer-based Seq-VPR method achieves both flexibility and efficiency. To address this gap, we propose Adapt-STformer, a Seq-VPR method built around our novel Recurrent Deformable Transformer Encoder (Recurrent-DTE), which uses an iterative recurrent mechanism to fuse information from multiple sequential frames. This design naturally supports variable seq-lengths, fast inference, and low memory usage. Experiments on the Nordland, Oxford, and NuScenes datasets show that Adapt-STformer boosts recall by up to 17% while reducing sequence extraction time by 36% and lowering memory usage by 35% compared to the second-best baseline.
3D Plant Root Skeleton Detection and Extraction
Aug 11, 2025Plant roots typically exhibit a highly complex and dense architecture, incorporating numerous slender lateral roots and branches, which significantly hinders the precise capture and modeling of the entire root system. Additionally, roots often lack sufficient texture and color information, making it difficult to identify and track root traits using visual methods. Previous research on roots has been largely confined to 2D studies; however, exploring the 3D architecture of roots is crucial in botany. Since roots grow in real 3D space, 3D phenotypic information is more critical for studying genetic traits and their impact on root development. We have introduced a 3D root skeleton extraction method that efficiently derives the 3D architecture of plant roots from a few images. This method includes the detection and matching of lateral roots, triangulation to extract the skeletal structure of lateral roots, and the integration of lateral and primary roots. We developed a highly complex root dataset and tested our method on it. The extracted 3D root skeletons showed considerable similarity to the ground truth, validating the effectiveness of the model. This method can play a significant role in automated breeding robots. Through precise 3D root structure analysis, breeding robots can better identify plant phenotypic traits, especially root structure and growth patterns, helping practitioners select seeds with superior root systems. This automated approach not only improves breeding efficiency but also reduces manual intervention, making the breeding process more intelligent and efficient, thus advancing modern agriculture.
Topological GCN for Improving Detection of Hip Landmarks from B-Mode Ultrasound Images
Aug 24, 2024
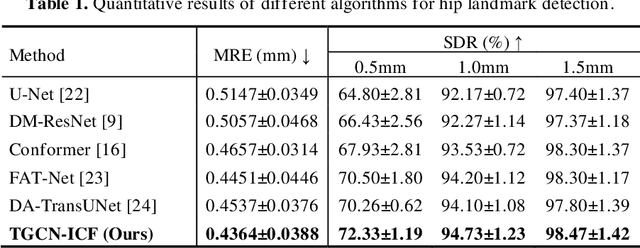
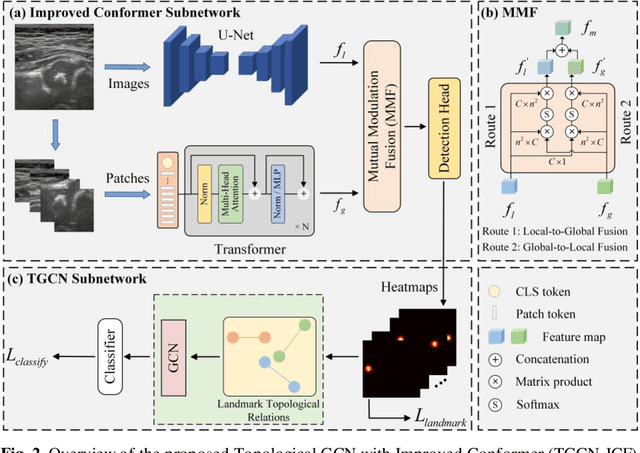
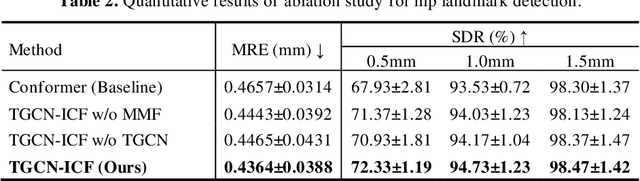
The B-mode ultrasound based computer-aided diagnosis (CAD) has demonstrated its effectiveness for diagnosis of Developmental Dysplasia of the Hip (DDH) in infants. However, due to effect of speckle noise in ultrasound im-ages, it is still a challenge task to accurately detect hip landmarks. In this work, we propose a novel hip landmark detection model by integrating the Topological GCN (TGCN) with an Improved Conformer (TGCN-ICF) into a unified frame-work to improve detection performance. The TGCN-ICF includes two subnet-works: an Improved Conformer (ICF) subnetwork to generate heatmaps and a TGCN subnetwork to additionally refine landmark detection. This TGCN can effectively improve detection accuracy with the guidance of class labels. Moreo-ver, a Mutual Modulation Fusion (MMF) module is developed for deeply ex-changing and fusing the features extracted from the U-Net and Transformer branches in ICF. The experimental results on the real DDH dataset demonstrate that the proposed TGCN-ICF outperforms all the compared algorithms.
pTSE: A Multi-model Ensemble Method for Probabilistic Time Series Forecasting
May 16, 2023



Various probabilistic time series forecasting models have sprung up and shown remarkably good performance. However, the choice of model highly relies on the characteristics of the input time series and the fixed distribution that the model is based on. Due to the fact that the probability distributions cannot be averaged over different models straightforwardly, the current time series model ensemble methods cannot be directly applied to improve the robustness and accuracy of forecasting. To address this issue, we propose pTSE, a multi-model distribution ensemble method for probabilistic forecasting based on Hidden Markov Model (HMM). pTSE only takes off-the-shelf outputs from member models without requiring further information about each model. Besides, we provide a complete theoretical analysis of pTSE to prove that the empirical distribution of time series subject to an HMM will converge to the stationary distribution almost surely. Experiments on benchmarks show the superiority of pTSE overall member models and competitive ensemble methods.
MixSeq: Connecting Macroscopic Time Series Forecasting with Microscopic Time Series Data
Oct 27, 2021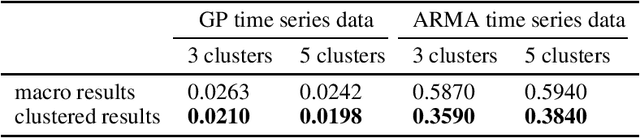


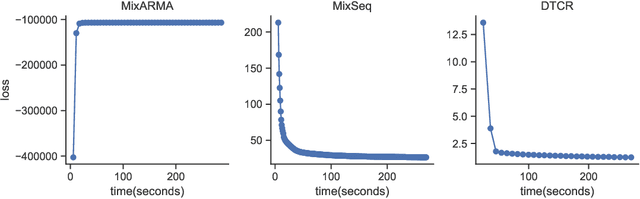
Time series forecasting is widely used in business intelligence, e.g., forecast stock market price, sales, and help the analysis of data trend. Most time series of interest are macroscopic time series that are aggregated from microscopic data. However, instead of directly modeling the macroscopic time series, rare literature studied the forecasting of macroscopic time series by leveraging data on the microscopic level. In this paper, we assume that the microscopic time series follow some unknown mixture probabilistic distributions. We theoretically show that as we identify the ground truth latent mixture components, the estimation of time series from each component could be improved because of lower variance, thus benefitting the estimation of macroscopic time series as well. Inspired by the power of Seq2seq and its variants on the modeling of time series data, we propose Mixture of Seq2seq (MixSeq), an end2end mixture model to cluster microscopic time series, where all the components come from a family of Seq2seq models parameterized by different parameters. Extensive experiments on both synthetic and real-world data show the superiority of our approach.
FANDA: A Novel Approach to Perform Follow-up Query Analysis
Jan 24, 2019


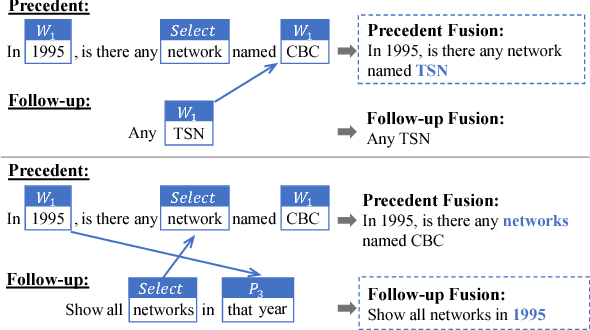
Recent work on Natural Language Interfaces to Databases (NLIDB) has attracted considerable attention. NLIDB allow users to search databases using natural language instead of SQL-like query languages. While saving the users from having to learn query languages, multi-turn interaction with NLIDB usually involves multiple queries where contextual information is vital to understand the users' query intents. In this paper, we address a typical contextual understanding problem, termed as follow-up query analysis. In spite of its ubiquity, follow-up query analysis has not been well studied due to two primary obstacles: the multifarious nature of follow-up query scenarios and the lack of high-quality datasets. Our work summarizes typical follow-up query scenarios and provides a new FollowUp dataset with $1000$ query triples on 120 tables. Moreover, we propose a novel approach FANDA, which takes into account the structures of queries and employs a ranking model with weakly supervised max-margin learning. The experimental results on FollowUp demonstrate the superiority of FANDA over multiple baselines across multiple metrics.
Highly Efficient 8-bit Low Precision Inference of Convolutional Neural Networks with IntelCaffe
May 04, 2018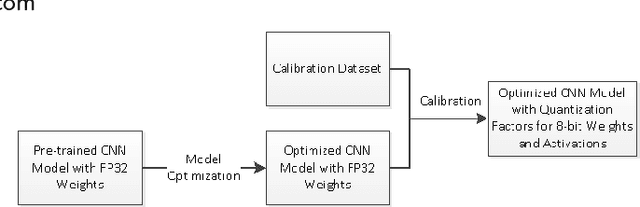
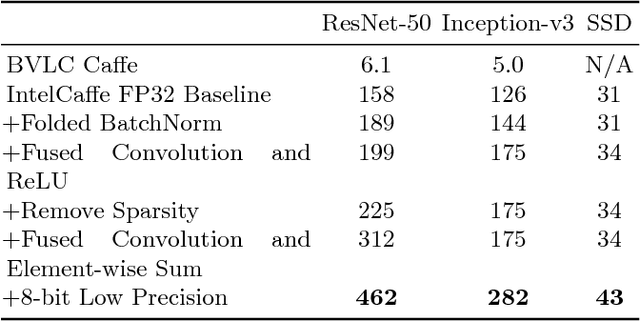

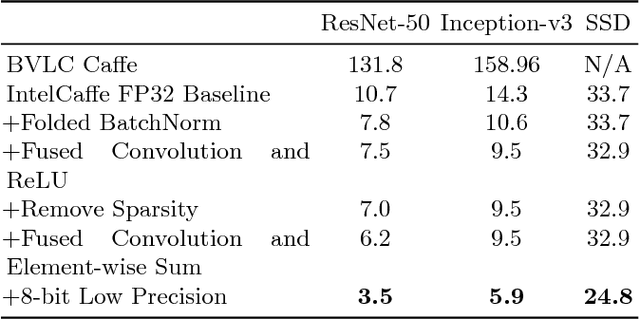
High throughput and low latency inference of deep neural networks are critical for the deployment of deep learning applications. This paper presents the efficient inference techniques of IntelCaffe, the first Intel optimized deep learning framework that supports efficient 8-bit low precision inference and model optimization techniques of convolutional neural networks on Intel Xeon Scalable Processors. The 8-bit optimized model is automatically generated with a calibration process from FP32 model without the need of fine-tuning or retraining. We show that the inference throughput and latency with ResNet-50, Inception-v3 and SSD are improved by 1.38X-2.9X and 1.35X-3X respectively with neglectable accuracy loss from IntelCaffe FP32 baseline and by 56X-75X and 26X-37X from BVLC Caffe. All these techniques have been open-sourced on IntelCaffe GitHub1, and the artifact is provided to reproduce the result on Amazon AWS Cloud.