 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Structure-Guided Latent Diffusion for Multimodal MRI Translation
Mar 13, 2026Although diffusion models have achieved remarkable progress in multi-modal magnetic resonance imaging (MRI) translation tasks, existing methods still tend to suffer from anatomical inconsistencies or degraded texture details when handling arbitrary missing-modality scenarios. To address these issues, we propose a latent diffusion-based multi-modal MRI translation framework, termed MSG-LDM. By leveraging the available modalities, the proposed method infers complete structural information, which preserves reliable boundary details. Specifically, we introduce a style--structure disentanglement mechanism in the latent space, which explicitly separates modality-specific style features from shared structural representations, and jointly models low-frequency anatomical layouts and high-frequency boundary details in a multi-scale feature space. During the structure disentanglement stage, high-frequency structural information is explicitly incorporated to enhance feature representations, guiding the model to focus on fine-grained structural cues while learning modality-invariant low-frequency anatomical representations. Furthermore, to reduce interference from modality-specific styles and improve the stability of structure representations, we design a style consistency loss and a structure-aware loss. Extensive experiments on the BraTS2020 and WMH datasets demonstrate that the proposed method outperforms existing MRI synthesis approaches, particularly in reconstructing complete structures. The source code is publicly available at https://github.com/ziyi-start/MSG-LDM.
Visually-Guided Controllable Medical Image Generation via Fine-Grained Semantic Disentanglement
Mar 11, 2026Medical image synthesis is crucial for alleviating data scarcity and privacy constraints. However, fine-tuning general text-to-image (T2I) models remains challenging, mainly due to the significant modality gap between complex visual details and abstract clinical text. In addition, semantic entanglement persists, where coarse-grained text embeddings blur the boundary between anatomical structures and imaging styles, thus weakening controllability during generation. To address this, we propose a Visually-Guided Text Disentanglement framework. We introduce a cross-modal latent alignment mechanism that leverages visual priors to explicitly disentangle unstructured text into independent semantic representations. Subsequently, a Hybrid Feature Fusion Module (HFFM) injects these features into a Diffusion Transformer (DiT) through separated channels, enabling fine-grained structural control. Experimental results in three datasets demonstrate that our method outperforms existing approaches in terms of generation quality and significantly improves performance on downstream classification tasks. The source code is available at https://github.com/hx111/VG-MedGen.
BrainSTR: Spatio-Temporal Contrastive Learning for Interpretable Dynamic Brain Network Modeling
Mar 10, 2026Dynamic functional connectivity captures time-varying brain states for better neuropsychiatric diagnosis and spatio-temporal interpretability, i.e., identifying when discriminative disease signatures emerge and where they reside in the connectivity topology. Reliable interpretability faces major challenges: diagnostic signals are often subtle and sparsely distributed across both time and topology, while nuisance fluctuations and non-diagnostic connectivities are pervasive. To address these issues, we propose BrainSTR, a spatio-temporal contrastive learning framework for interpretable dynamic brain network modeling. BrainSTR learns state-consistent phase boundaries via a data-driven Adaptive Phase Partition module, identifies diagnostically critical phases with attention, and extracts disease-related connectivity within each phase using an Incremental Graph Structure Generator regularized by binarization, temporal smoothness, and sparsity. Then, we introduce a spatio-temporal supervised contrastive learning approach that leverages diagnosis-relevant spatio-temporal patterns to refine the similarity metric between samples and capture more discriminative spatio-temporal features, thereby constructing a well-structured semantic space for coherent and interpretable representations. Experiments on ASD, BD, and MDD validate the effectiveness of BrainSTR, and the discovered critical phases and subnetworks provide interpretable evidence consistent with prior neuroimaging findings. Our code: https://anonymous.4open.science/r/BrainSTR1.
Learning the Hierarchical Organization in Brain Network for Brain Disorder Diagnosis
Mar 10, 2026Brain network analysis based on functional Magnetic Resonance Imaging (fMRI) is pivotal for diagnosing brain disorders. Existing approaches typically rely on predefined functional sub-networks to construct sub-network associations. However, we identified many cross-network interaction patterns with high Pearson correlations that this strict, prior-based organization fails to capture. To overcome this limitation, we propose the Brain Hierarchical Organization Learning (BrainHO) to learn inherently hierarchical brain network dependencies based on their intrinsic features rather than predefined sub-network labels. Specifically, we design a hierarchical attention mechanism that allows the model to aggregate nodes into a hierarchical organization, effectively capturing intricate connectivity patterns at the subgraph level. To ensure diverse, complementary, and stable organizations, we incorporate an orthogonality constraint loss, alongside a hierarchical consistency constraint strategy, to refine node-level features using high-level graph semantics. Extensive experiments on the publicly available ABIDE and REST-meta-MDD datasets demonstrate that BrainHO not only achieves state-of-the-art classification performance but also uncovers interpretable, clinically significant biomarkers by precisely localizing disease-related sub-networks.
GSTurb: Gaussian Splatting for Atmospheric Turbulence Mitigation
Feb 26, 2026Atmospheric turbulence causes significant image degradation due to pixel displacement (tilt) and blur, particularly in long-range imaging applications. In this paper, we propose a novel framework for atmospheric turbulence mitigation, GSTurb, which integrates optical flow-guided tilt correction and Gaussian splatting for modeling non-isoplanatic blur. The framework employs Gaussian parameters to represent tilt and blur, and optimizes them across multiple frames to enhance restoration. Experimental results on the ATSyn-static dataset demonstrate the effectiveness of our method, achieving a peak PSNR of 27.67 dB and SSIM of 0.8735. Compared to the state-of-the-art method, GSTurb improves PSNR by 1.3 dB (a 4.5% increase) and SSIM by 0.048 (a 5.8% increase). Additionally, on real datasets, including the TSRWGAN Real-World and CLEAR datasets, GSTurb outperforms existing methods, showing significant improvements in both qualitative and quantitative performance. These results highlight that combining optical flow-guided tilt correction with Gaussian splatting effectively enhances image restoration under both synthetic and real-world turbulence conditions. The code for this method will be available at https://github.com/DuhlLiamz/3DGS_turbulence/tree/main.
E2Former-V2: On-the-Fly Equivariant Attention with Linear Activation Memory
Jan 23, 2026Equivariant Graph Neural Networks (EGNNs) have become a widely used approach for modeling 3D atomistic systems. However, mainstream architectures face critical scalability bottlenecks due to the explicit construction of geometric features or dense tensor products on \textit{every} edge. To overcome this, we introduce \textbf{E2Former-V2}, a scalable architecture that integrates algebraic sparsity with hardware-aware execution. We first propose \textbf{E}quivariant \textbf{A}xis-\textbf{A}ligned \textbf{S}parsification (EAAS). EAAS builds on Wigner-$6j$ convolution by exploiting an $\mathrm{SO}(3) \rightarrow \mathrm{SO}(2)$ change of basis to transform computationally expensive dense tensor contractions into efficient, sparse parity re-indexing operations. Building on this representation, we introduce \textbf{On-the-Fly Equivariant Attention}, a fully node-centric mechanism implemented via a custom fused Triton kernel. By eliminating materialized edge tensors and maximizing SRAM utilization, our kernel achieves a \textbf{20$\times$ improvement in TFLOPS} compared to standard implementations. Extensive experiments on the SPICE and OMol25 datasets demonstrate that E2Former-V2 maintains comparable predictive performance while notably accelerating inference. This work demonstrates that large equivariant transformers can be trained efficiently using widely accessible GPU platforms. The code is avalible at https://github.com/IQuestLab/UBio-MolFM/tree/e2formerv2.
SynMatch: Rethinking Consistency in Medical Image Segmentation with Sparse Annotations
Aug 10, 2025Label scarcity remains a major challenge in deep learning-based medical image segmentation. Recent studies use strong-weak pseudo supervision to leverage unlabeled data. However, performance is often hindered by inconsistencies between pseudo labels and their corresponding unlabeled images. In this work, we propose \textbf{SynMatch}, a novel framework that sidesteps the need for improving pseudo labels by synthesizing images to match them instead. Specifically, SynMatch synthesizes images using texture and shape features extracted from the same segmentation model that generates the corresponding pseudo labels for unlabeled images. This design enables the generation of highly consistent synthesized-image-pseudo-label pairs without requiring any training parameters for image synthesis. We extensively evaluate SynMatch across diverse medical image segmentation tasks under semi-supervised learning (SSL), weakly-supervised learning (WSL), and barely-supervised learning (BSL) settings with increasingly limited annotations. The results demonstrate that SynMatch achieves superior performance, especially in the most challenging BSL setting. For example, it outperforms the recent strong-weak pseudo supervision-based method by 29.71\% and 10.05\% on the polyp segmentation task with 5\% and 10\% scribble annotations, respectively. The code will be released at https://github.com/Senyh/SynMatch.
What Is Next for LLMs? Next-Generation AI Computing Hardware Using Photonic Chips
May 09, 2025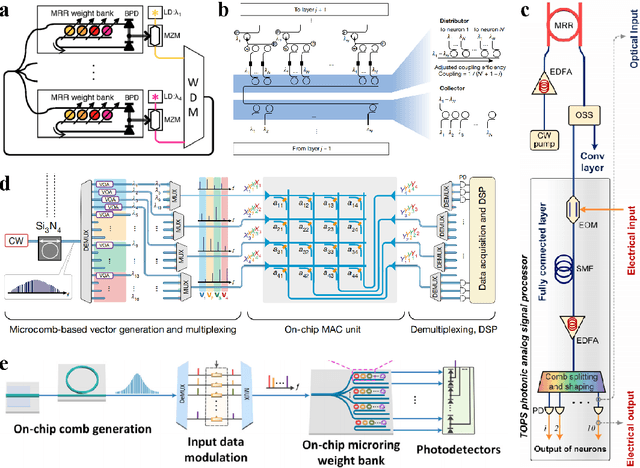
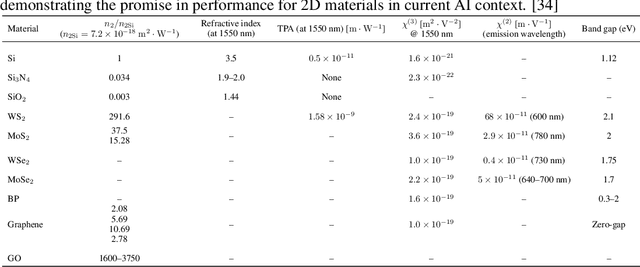
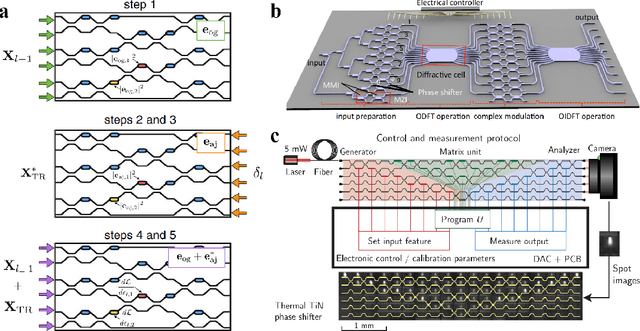
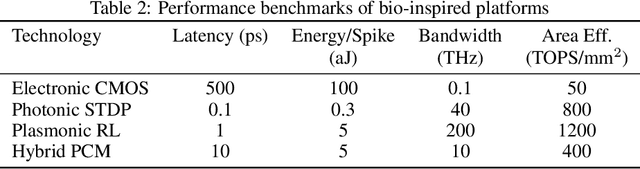
Large language models (LLMs) are rapidly pushing the limits of contemporary computing hardware. For example, training GPT-3 has been estimated to consume around 1300 MWh of electricity, and projections suggest future models may require city-scale (gigawatt) power budgets. These demands motivate exploration of computing paradigms beyond conventional von Neumann architectures. This review surveys emerging photonic hardware optimized for next-generation generative AI computing. We discuss integrated photonic neural network architectures (e.g., Mach-Zehnder interferometer meshes, lasers, wavelength-multiplexed microring resonators) that perform ultrafast matrix operations. We also examine promising alternative neuromorphic devices, including spiking neural network circuits and hybrid spintronic-photonic synapses, which combine memory and processing. The integration of two-dimensional materials (graphene, TMDCs) into silicon photonic platforms is reviewed for tunable modulators and on-chip synaptic elements. Transformer-based LLM architectures (self-attention and feed-forward layers) are analyzed in this context, identifying strategies and challenges for mapping dynamic matrix multiplications onto these novel hardware substrates. We then dissect the mechanisms of mainstream LLMs, such as ChatGPT, DeepSeek, and LLaMA, highlighting their architectural similarities and differences. We synthesize state-of-the-art components, algorithms, and integration methods, highlighting key advances and open issues in scaling such systems to mega-sized LLM models. We find that photonic computing systems could potentially surpass electronic processors by orders of magnitude in throughput and energy efficiency, but require breakthroughs in memory, especially for long-context windows and long token sequences, and in storage of ultra-large datasets.
GaussianCAD: Robust Self-Supervised CAD Reconstruction from Three Orthographic Views Using 3D Gaussian Splatting
Mar 07, 2025



The automatic reconstruction of 3D computer-aided design (CAD) models from CAD sketches has recently gained significant attention in the computer vision community. Most existing methods, however, rely on vector CAD sketches and 3D ground truth for supervision, which are often difficult to be obtained in industrial applications and are sensitive to noise inputs. We propose viewing CAD reconstruction as a specific instance of sparse-view 3D reconstruction to overcome these limitations. While this reformulation offers a promising perspective, existing 3D reconstruction methods typically require natural images and corresponding camera poses as inputs, which introduces two major significant challenges: (1) modality discrepancy between CAD sketches and natural images, and (2) difficulty of accurate camera pose estimation for CAD sketches. To solve these issues, we first transform the CAD sketches into representations resembling natural images and extract corresponding masks. Next, we manually calculate the camera poses for the orthographic views to ensure accurate alignment within the 3D coordinate system. Finally, we employ a customized sparse-view 3D reconstruction method to achieve high-quality reconstructions from aligned orthographic views. By leveraging raster CAD sketches for self-supervision, our approach eliminates the reliance on vector CAD sketches and 3D ground truth. Experiments on the Sub-Fusion360 dataset demonstrate that our proposed method significantly outperforms previous approaches in CAD reconstruction performance and exhibits strong robustness to noisy inputs.
SyncAnimation: A Real-Time End-to-End Framework for Audio-Driven Human Pose and Talking Head Animation
Jan 24, 2025Generating talking avatar driven by audio remains a significant challenge. Existing methods typically require high computational costs and often lack sufficient facial detail and realism, making them unsuitable for applications that demand high real-time performance and visual quality. Additionally, while some methods can synchronize lip movement, they still face issues with consistency between facial expressions and upper body movement, particularly during silent periods. In this paper, we introduce SyncAnimation, the first NeRF-based method that achieves audio-driven, stable, and real-time generation of speaking avatar by combining generalized audio-to-pose matching and audio-to-expression synchronization. By integrating AudioPose Syncer and AudioEmotion Syncer, SyncAnimation achieves high-precision poses and expression generation, progressively producing audio-synchronized upper body, head, and lip shapes. Furthermore, the High-Synchronization Human Renderer ensures seamless integration of the head and upper body, and achieves audio-sync lip. The project page can be found at https://syncanimation.github.io