 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTENet: Superpixel Token Enhancing Network for RGB-D Salient Object Detection
Mar 23, 2026Transformer-based methods for RGB-D Salient Object Detection (SOD) have gained significant interest, owing to the transformer's exceptional capacity to capture long-range pixel dependencies. Nevertheless, current RGB-D SOD methods face challenges, such as the quadratic complexity of the attention mechanism and the limited local detail extraction. To overcome these limitations, we propose a novel Superpixel Token Enhancing Network (STENet), which introduces superpixels into cross-modal interaction. STENet follows the two-stream encoder-decoder structure. Its cores are two tailored superpixel-driven cross-modal interaction modules, responsible for global and local feature enhancement. Specifically, we update the superpixel generation method by expanding the neighborhood range of each superpixel, allowing for flexible transformation between pixels and superpixels. With the updated superpixel generation method, we first propose the Superpixel Attention Global Enhancing Module to model the global pixel-to-superpixel relationship rather than the traditional global pixel-to-pixel relationship, which can capture region-level information and reduce computational complexity. We also propose the Superpixel Attention Local Refining Module, which leverages pixel similarity within superpixels to filter out a subset of pixels (i.e., local pixels) and then performs feature enhancement on these local pixels, thereby capturing concerned local details. Furthermore, we fuse the globally and locally enhanced features along with the cross-scale features to achieve comprehensive feature representation. Experiments on seven RGB-D SOD datasets reveal that our STENet achieves competitive performance compared to state-of-the-art methods. The code and results of our method are available at https://github.com/Mark9010/STENet.
C2PO: Diagnosing and Disentangling Bias Shortcuts in LLMs
Dec 29, 2025Bias in Large Language Models (LLMs) poses significant risks to trustworthiness, manifesting primarily as stereotypical biases (e.g., gender or racial stereotypes) and structural biases (e.g., lexical overlap or position preferences). However, prior paradigms typically address these in isolation, often mitigating one at the expense of exacerbating the other. To address this, we conduct a systematic exploration of these reasoning failures and identify a primary inducement: the latent spurious feature correlations within the input that drive these erroneous reasoning shortcuts. Driven by these findings, we introduce Causal-Contrastive Preference Optimization (C2PO), a unified alignment framework designed to tackle these specific failures by simultaneously discovering and suppressing these correlations directly within the optimization process. Specifically, C2PO leverages causal counterfactual signals to isolate bias-inducing features from valid reasoning paths, and employs a fairness-sensitive preference update mechanism to dynamically evaluate logit-level contributions and suppress shortcut features. Extensive experiments across multiple benchmarks covering stereotypical bias (BBQ, Unqover), structural bias (MNLI, HANS, Chatbot, MT-Bench), out-of-domain fairness (StereoSet, WinoBias), and general utility (MMLU, GSM8K) demonstrate that C2PO effectively mitigates stereotypical and structural biases while preserving robust general reasoning capabilities.
Representation Learning with Mutual Influence of Modalities for Node Classification in Multi-Modal Heterogeneous Networks
May 12, 2025Nowadays, numerous online platforms can be described as multi-modal heterogeneous networks (MMHNs), such as Douban's movie networks and Amazon's product review networks. Accurately categorizing nodes within these networks is crucial for analyzing the corresponding entities, which requires effective representation learning on nodes. However, existing multi-modal fusion methods often adopt either early fusion strategies which may lose the unique characteristics of individual modalities, or late fusion approaches overlooking the cross-modal guidance in GNN-based information propagation. In this paper, we propose a novel model for node classification in MMHNs, named Heterogeneous Graph Neural Network with Inter-Modal Attention (HGNN-IMA). It learns node representations by capturing the mutual influence of multiple modalities during the information propagation process, within the framework of heterogeneous graph transformer. Specifically, a nested inter-modal attention mechanism is integrated into the inter-node attention to achieve adaptive multi-modal fusion, and modality alignment is also taken into account to encourage the propagation among nodes with consistent similarities across all modalities. Moreover, an attention loss is augmented to mitigate the impact of missing modalities. Extensive experiments validate the superiority of the model in the node classification task, providing an innovative view to handle multi-modal data, especially when accompanied with network structures.
Learning from Mistakes: Self-correct Adversarial Training for Chinese Unnatural Text Correction
Dec 23, 2024



Unnatural text correction aims to automatically detect and correct spelling errors or adversarial perturbation errors in sentences. Existing methods typically rely on fine-tuning or adversarial training to correct errors, which have achieved significant success. However, these methods exhibit poor generalization performance due to the difference in data distribution between training data and real-world scenarios, known as the exposure bias problem. In this paper, we propose a self-correct adversarial training framework for \textbf{L}earn\textbf{I}ng from \textbf{MI}s\textbf{T}akes (\textbf{LIMIT}), which is a task- and model-independent framework to correct unnatural errors or mistakes. Specifically, we fully utilize errors generated by the model that are actively exposed during the inference phase, i.e., predictions that are inconsistent with the target. This training method not only simulates potential errors in real application scenarios, but also mitigates the exposure bias of the traditional training process. Meanwhile, we design a novel decoding intervention strategy to maintain semantic consistency. Extensive experimental results on Chinese unnatural text error correction datasets show that our proposed method can correct multiple forms of errors and outperforms the state-of-the-art text correction methods. In addition, extensive results on Chinese and English datasets validate that LIMIT can serve as a plug-and-play defense module and can extend to new models and datasets without further training.
Towards Fair Graph Neural Networks via Graph Counterfactual without Sensitive Attributes
Dec 13, 2024


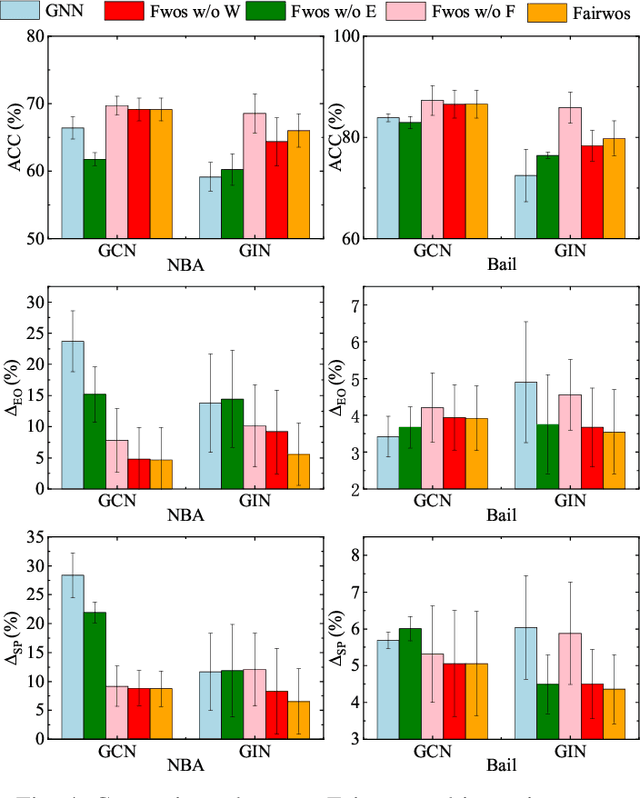
Graph-structured data is ubiquitous in today's connected world, driving extensive research in graph analysis. Graph Neural Networks (GNNs) have shown great success in this field, leading to growing interest in developing fair GNNs for critical applications. However, most existing fair GNNs focus on statistical fairness notions, which may be insufficient when dealing with statistical anomalies. Hence, motivated by causal theory, there has been growing attention to mitigating root causes of unfairness utilizing graph counterfactuals. Unfortunately, existing methods for generating graph counterfactuals invariably require the sensitive attribute. Nevertheless, in many real-world applications, it is usually infeasible to obtain sensitive attributes due to privacy or legal issues, which challenge existing methods. In this paper, we propose a framework named Fairwos (improving Fairness without sensitive attributes). In particular, we first propose a mechanism to generate pseudo-sensitive attributes to remedy the problem of missing sensitive attributes, and then design a strategy for finding graph counterfactuals from the real dataset. To train fair GNNs, we propose a method to ensure that the embeddings from the original data are consistent with those from the graph counterfactuals, and dynamically adjust the weight of each pseudo-sensitive attribute to balance its contribution to fairness and utility. Furthermore, we theoretically demonstrate that minimizing the relation between these pseudo-sensitive attributes and the prediction can enable the fairness of GNNs. Experimental results on six real-world datasets show that our approach outperforms state-of-the-art methods in balancing utility and fairness.
Knowledge-Guided Dynamic Modality Attention Fusion Framework for Multimodal Sentiment Analysis
Oct 06, 2024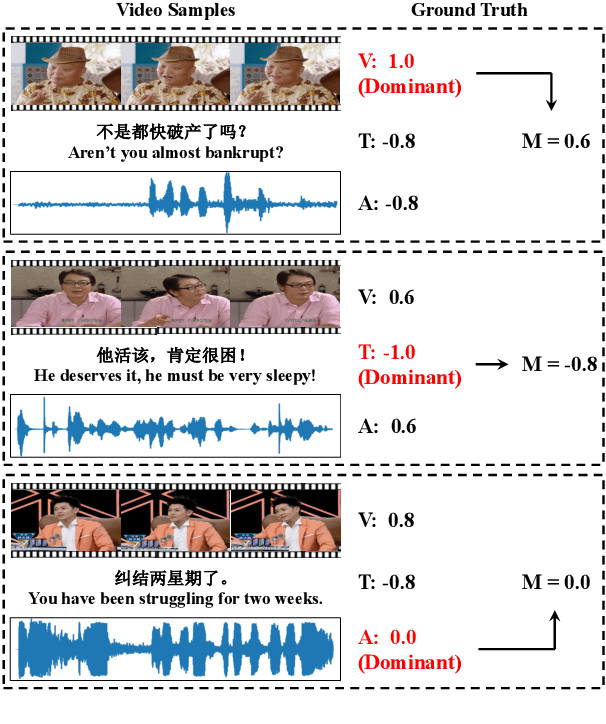
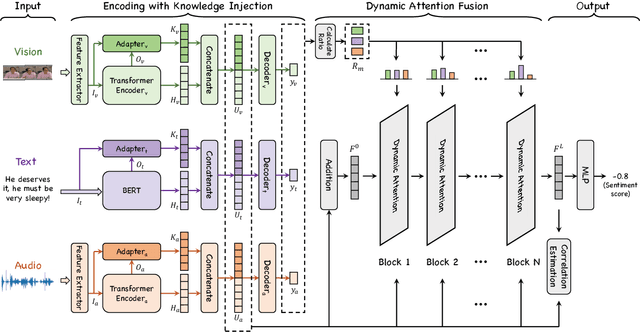
Multimodal Sentiment Analysis (MSA) utilizes multimodal data to infer the users' sentiment. Previous methods focus on equally treating the contribution of each modality or statically using text as the dominant modality to conduct interaction, which neglects the situation where each modality may become dominant. In this paper, we propose a Knowledge-Guided Dynamic Modality Attention Fusion Framework (KuDA) for multimodal sentiment analysis. KuDA uses sentiment knowledge to guide the model dynamically selecting the dominant modality and adjusting the contributions of each modality. In addition, with the obtained multimodal representation, the model can further highlight the contribution of dominant modality through the correlation evaluation loss. Extensive experiments on four MSA benchmark datasets indicate that KuDA achieves state-of-the-art performance and is able to adapt to different scenarios of dominant modality.
One-Shot Learning for Pose-Guided Person Image Synthesis in the Wild
Sep 15, 2024



Current Pose-Guided Person Image Synthesis (PGPIS) methods depend heavily on large amounts of labeled triplet data to train the generator in a supervised manner. However, they often falter when applied to in-the-wild samples, primarily due to the distribution gap between the training datasets and real-world test samples. While some researchers aim to enhance model generalizability through sophisticated training procedures, advanced architectures, or by creating more diverse datasets, we adopt the test-time fine-tuning paradigm to customize a pre-trained Text2Image (T2I) model. However, naively applying test-time tuning results in inconsistencies in facial identities and appearance attributes. To address this, we introduce a Visual Consistency Module (VCM), which enhances appearance consistency by combining the face, text, and image embedding. Our approach, named OnePoseTrans, requires only a single source image to generate high-quality pose transfer results, offering greater stability than state-of-the-art data-driven methods. For each test case, OnePoseTrans customizes a model in around 48 seconds with an NVIDIA V100 GPU.
ConStyle v2: A Strong Prompter for All-in-One Image Restoration
Jun 26, 2024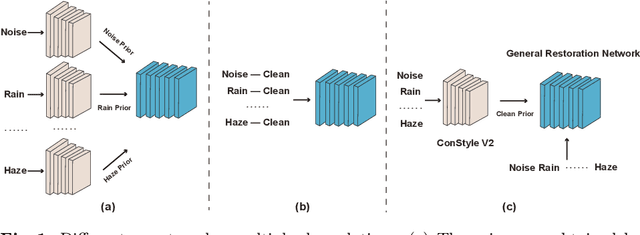
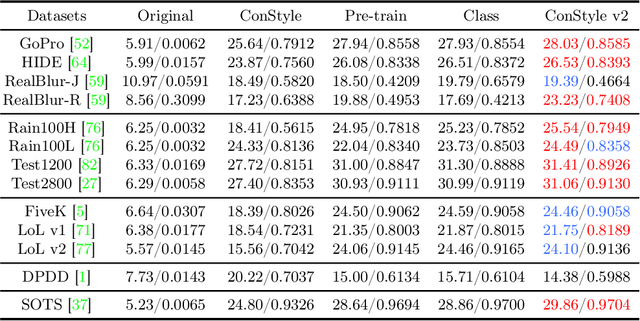
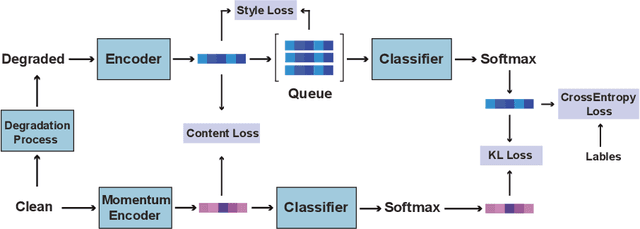
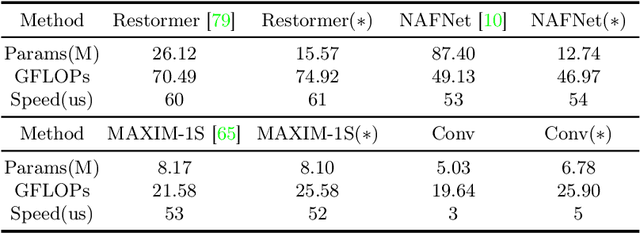
This paper introduces ConStyle v2, a strong plug-and-play prompter designed to output clean visual prompts and assist U-Net Image Restoration models in handling multiple degradations. The joint training process of IRConStyle, an Image Restoration framework consisting of ConStyle and a general restoration network, is divided into two stages: first, pre-training ConStyle alone, and then freezing its weights to guide the training of the general restoration network. Three improvements are proposed in the pre-training stage to train ConStyle: unsupervised pre-training, adding a pretext task (i.e. classification), and adopting knowledge distillation. Without bells and whistles, we can get ConStyle v2, a strong prompter for all-in-one Image Restoration, in less than two GPU days and doesn't require any fine-tuning. Extensive experiments on Restormer (transformer-based), NAFNet (CNN-based), MAXIM-1S (MLP-based), and a vanilla CNN network demonstrate that ConStyle v2 can enhance any U-Net style Image Restoration models to all-in-one Image Restoration models. Furthermore, models guided by the well-trained ConStyle v2 exhibit superior performance in some specific degradation compared to ConStyle.
IRConStyle: Image Restoration Framework Using Contrastive Learning and Style Transfer
Mar 07, 2024
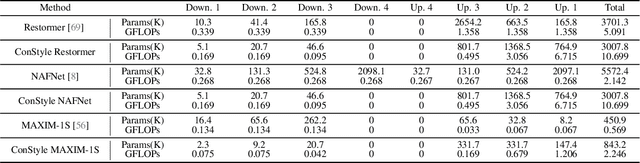
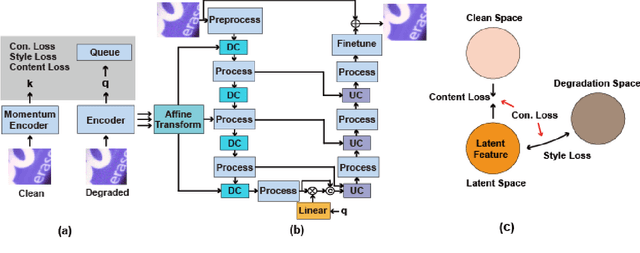
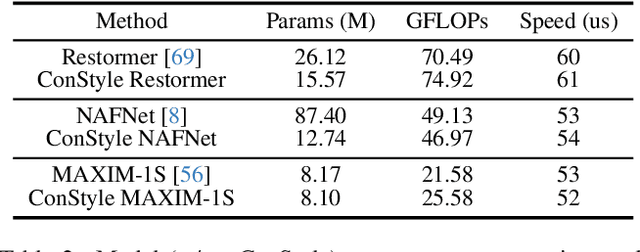
Recently, the contrastive learning paradigm has achieved remarkable success in high-level tasks such as classification, detection, and segmentation. However, contrastive learning applied in low-level tasks, like image restoration, is limited, and its effectiveness is uncertain. This raises a question: Why does the contrastive learning paradigm not yield satisfactory results in image restoration? In this paper, we conduct in-depth analyses and propose three guidelines to address the above question. In addition, inspired by style transfer and based on contrastive learning, we propose a novel module for image restoration called \textbf{ConStyle}, which can be efficiently integrated into any U-Net structure network. By leveraging the flexibility of ConStyle, we develop a \textbf{general restoration network} for image restoration. ConStyle and the general restoration network together form an image restoration framework, namely \textbf{IRConStyle}. To demonstrate the capability and compatibility of ConStyle, we replace the general restoration network with transformer-based, CNN-based, and MLP-based networks, respectively. We perform extensive experiments on various image restoration tasks, including denoising, deblurring, deraining, and dehazing. The results on 19 benchmarks demonstrate that ConStyle can be integrated with any U-Net-based network and significantly enhance performance. For instance, ConStyle NAFNet significantly outperforms the original NAFNet on SOTS outdoor (dehazing) and Rain100H (deraining) datasets, with PSNR improvements of 4.16 dB and 3.58 dB with 85% fewer parameters.
LIR: Efficient Degradation Removal for Lightweight Image Restoration
Feb 02, 2024



Recently, there have been significant advancements in Image Restoration based on CNN and transformer. However, the inherent characteristics of the Image Restoration task are often overlooked in many works. These works often focus on the basic block design and stack numerous basic blocks to the model, leading to redundant parameters and unnecessary computations and hindering the efficiency of the image restoration. In this paper, we propose a Lightweight Image Restoration network called LIR to efficiently remove degradation (blur, rain, noise, haze, etc.). A key component in LIR is the Efficient Adaptive Attention (EAA) Block, which is mainly composed of Adaptive Filters and Attention Blocks. It is capable of adaptively sharpening contours, removing degradation, and capturing global information in various image restoration scenes in an efficient and computation-friendly manner. In addition, through a simple structural design, LIR addresses the degradations existing in the local and global residual connections that are ignored by modern networks. Extensive experiments demonstrate that our LIR achieves comparable performance to state-of-the-art networks on most benchmarks with fewer parameters and computations. It is worth noting that our LIR produces better visual results than state-of-the-art networks that are more in line with the human aesthetic.