 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedPriv-Bench: Benchmarking the Privacy-Utility Trade-off of Large Language Models in Medical Open-End Question Answering
Mar 15, 2026Recent advances in Retrieval-Augmented Generation (RAG) have enabled large language models (LLMs) to ground outputs in clinical evidence. However, connecting LLMs with external databases introduces the risk of contextual leakage: a subtle privacy threat where unique combinations of medical details enable patient re-identification even without explicit identifiers. Current benchmarks in healthcare heavily focus on accuracy, ignoring such privacy issues, despite strict regulations like Health Insurance Portability and Accountability Act (HIPAA) and General Data Protection Regulation (GDPR). To fill this gap, we present MedPriv-Bench, the first benchmark specifically designed to jointly evaluate privacy preservation and clinical utility in medical open-ended question answering. Our framework utilizes a multi-agent, human-in-the-loop pipeline to synthesize sensitive medical contexts and clinically relevant queries that create realistic privacy pressure. We establish a standardized evaluation protocol leveraging a pre-trained RoBERTa-Natural Language Inference (NLI) model as an automated judge to quantify data leakage, achieving an average of 85.9% alignment with human experts. Through an extensive evaluation of 9 representative LLMs, we demonstrate a pervasive privacy-utility trade-off. Our findings underscore the necessity of domain-specific benchmarks to validate the safety and efficacy of medical AI systems in privacy-sensitive environments.
PsyLite Technical Report
Jun 26, 2025With the rapid development of digital technology, AI-driven psychological counseling has gradually become an important research direction in the field of mental health. However, existing models still have deficiencies in dialogue safety, detailed scenario handling, and lightweight deployment. To address these issues, this study proposes PsyLite, a lightweight psychological counseling large language model agent developed based on the base model InternLM2.5-7B-chat. Through a two-stage training strategy (hybrid distillation data fine-tuning and ORPO preference optimization), PsyLite enhances the model's deep-reasoning ability, psychological counseling ability, and safe dialogue ability. After deployment using Ollama and Open WebUI, a custom workflow is created with Pipelines. An innovative conditional RAG is designed to introduce crosstalk humor elements at appropriate times during psychological counseling to enhance user experience and decline dangerous requests to strengthen dialogue safety. Evaluations show that PsyLite outperforms the baseline models in the Chinese general evaluation (CEval), psychological counseling professional evaluation (CPsyCounE), and dialogue safety evaluation (SafeDialBench), particularly in psychological counseling professionalism (CPsyCounE score improvement of 47.6\%) and dialogue safety (\safe{} score improvement of 2.4\%). Additionally, the model uses quantization technology (GGUF q4\_k\_m) to achieve low hardware deployment (5GB memory is sufficient for operation), providing a feasible solution for psychological counseling applications in resource-constrained environments.
Graph Neural Network Aided Detection for the Multi-User Multi-Dimensional Index Modulated Uplink
May 27, 2025The concept of Compressed Sensing-aided Space-Frequency Index Modulation (CS-SFIM) is conceived for the Large-Scale Multi-User Multiple-Input Multiple-Output Uplink (LS-MU-MIMO-UL) of Next-Generation (NG) networks. Explicitly, in CS-SFIM, the information bits are mapped to both spatial- and frequency-domain indices, where we treat the activation patterns of the transmit antennas and of the subcarriers separately. Serving a large number of users in an MU-MIMO-UL system leads to substantial Multi-User Interference (MUI). Hence, we design the Space-Frequency (SF) domain matrix as a joint factor graph, where the Approximate Message Passing (AMP) and Expectation Propagation (EP) based MU detectors can be utilized. In the LS-MU-MIMO-UL scenario considered, the proposed system uses optimal Maximum Likelihood (ML) and Minimum Mean Square Error (MMSE) detectors as benchmarks for comparison with the proposed MP-based detectors. These MP-based detectors significantly reduce the detection complexity compared to ML detection, making the design eminently suitable for LS-MU scenarios. To further reduce the detection complexity and improve the detection performance, we propose a pair of Graph Neural Network (GNN) based detectors, which rely on the orthogonal AMP (OAMP) and on the EP algorithm, which we refer to as the GNN-AMP and GEPNet detectors, respectively. The GEPNet detector maximizes the detection performance, while the GNN-AMP detector strikes a performance versus complexity trade-off. The GNN is trained for a single system configuration and yet it can be used for any number of users in the system. The simulation results show that the GNN-based detector approaches the ML performance in various configurations.
LLMs Can Generate a Better Answer by Aggregating Their Own Responses
Mar 06, 2025Large Language Models (LLMs) have shown remarkable capabilities across tasks, yet they often require additional prompting techniques when facing complex problems. While approaches like self-correction and response selection have emerged as popular solutions, recent studies have shown these methods perform poorly when relying on the LLM itself to provide feedback or selection criteria. We argue this limitation stems from the fact that common LLM post-training procedures lack explicit supervision for discriminative judgment tasks. In this paper, we propose Generative Self-Aggregation (GSA), a novel prompting method that improves answer quality without requiring the model's discriminative capabilities. GSA first samples multiple diverse responses from the LLM, then aggregates them to obtain an improved solution. Unlike previous approaches, our method does not require the LLM to correct errors or compare response quality; instead, it leverages the model's generative abilities to synthesize a new response based on the context of multiple samples. While GSA shares similarities with the self-consistency (SC) approach for response aggregation, SC requires specific verifiable tokens to enable majority voting. In contrast, our approach is more general and can be applied to open-ended tasks. Empirical evaluation demonstrates that GSA effectively improves response quality across various tasks, including mathematical reasoning, knowledge-based problems, and open-ended generation tasks such as code synthesis and conversational responses.
Knowledge-Guided Dynamic Modality Attention Fusion Framework for Multimodal Sentiment Analysis
Oct 06, 2024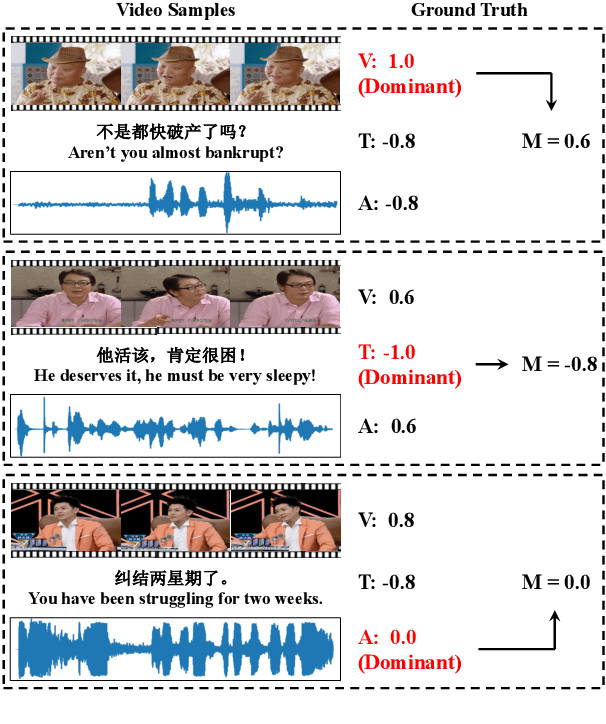
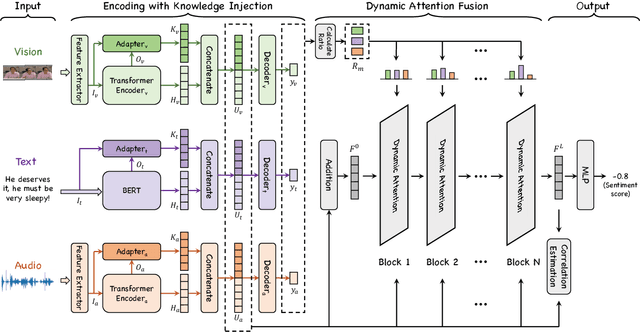
Multimodal Sentiment Analysis (MSA) utilizes multimodal data to infer the users' sentiment. Previous methods focus on equally treating the contribution of each modality or statically using text as the dominant modality to conduct interaction, which neglects the situation where each modality may become dominant. In this paper, we propose a Knowledge-Guided Dynamic Modality Attention Fusion Framework (KuDA) for multimodal sentiment analysis. KuDA uses sentiment knowledge to guide the model dynamically selecting the dominant modality and adjusting the contributions of each modality. In addition, with the obtained multimodal representation, the model can further highlight the contribution of dominant modality through the correlation evaluation loss. Extensive experiments on four MSA benchmark datasets indicate that KuDA achieves state-of-the-art performance and is able to adapt to different scenarios of dominant modality.
EFMVFL: An Efficient and Flexible Multi-party Vertical Federated Learning without a Third Party
Jan 17, 2022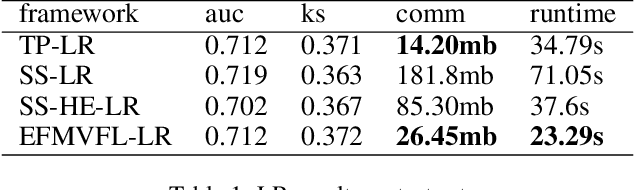
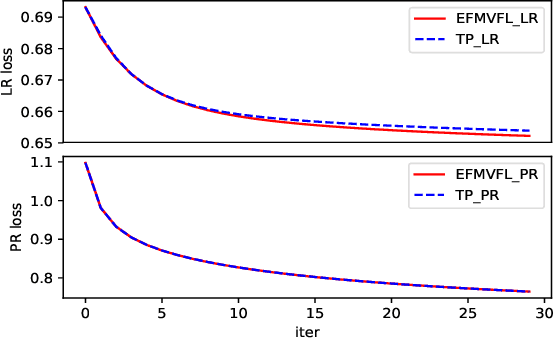
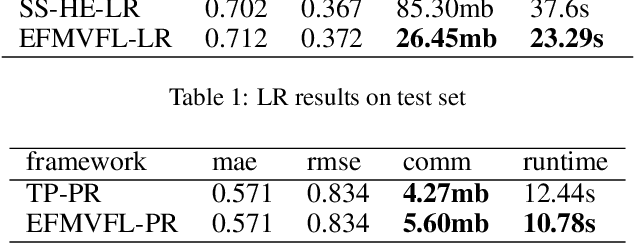
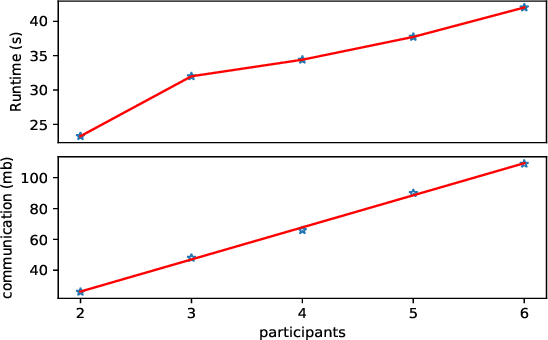
Federated learning allows multiple participants to conduct joint modeling without disclosing their local data. Vertical federated learning (VFL) handles the situation where participants share the same ID space and different feature spaces. In most VFL frameworks, to protect the security and privacy of the participants' local data, a third party is needed to generate homomorphic encryption key pairs and perform decryption operations. In this way, the third party is granted the right to decrypt information related to model parameters. However, it isn't easy to find such a credible entity in the real world. Existing methods for solving this problem are either communication-intensive or unsuitable for multi-party scenarios. By combining secret sharing and homomorphic encryption, we propose a novel VFL framework without a third party called EFMVFL, which supports flexible expansion to multiple participants with low communication overhead and is applicable to generalized linear models. We give instantiations of our framework under logistic regression and Poisson regression. Theoretical analysis and experiments show that our framework is secure, more efficient, and easy to be extended to multiple participants.