 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuffle the Context: RoPE-Perturbed Self-Distillation for Long-Context Adaptation
Apr 15, 2026Large language models (LLMs) increasingly operate in settings that require reliable long-context understanding, such as retrieval-augmented generation and multi-document reasoning. A common strategy is to fine-tune pretrained short-context models at the target sequence length. However, we find that standard long-context adaptation can remain brittle: model accuracy depends strongly on the absolute placement of relevant evidence, exhibiting high positional variance even when controlling for task format and difficulty. We propose RoPE-Perturbed Self-Distillation, a training regularizer that improves positional robustness. The core idea is to form alternative "views" of the same training sequence by perturbing its RoPE indices -- effectively moving parts of the context to different positions -- and to train the model to produce consistent predictions across views via self-distillation. This encourages reliance on semantic signals instead of brittle position dependencies. Experiments on long-context adaptation of Llama-3-8B and Qwen-3-4B demonstrate consistent gains on long-context benchmarks, including up to 12.04% improvement on RULER-64K for Llama-3-8B and 2.71% on RULER-256K for Qwen-3-4B after SFT, alongside improved length extrapolation beyond the training context window.
Controllable and Verifiable Tool-Use Data Synthesis for Agentic Reinforcement Learning
Apr 10, 2026Existing synthetic tool-use corpora are primarily designed for offline supervised fine-tuning, yet reinforcement learning (RL) requires executable environments that support reward-checkable online rollouts. We propose COVERT, a two-stage pipeline that first generates reliable base tool-use trajectories through self-evolving synthesis with multi-level validation, and then applies oracle-preserving augmentations that systematically increase environmental complexity. These augmentations introduce distractor tools, indirect or ambiguous user queries, and noisy, multi-format, or erroneous tool outputs, while strictly preserving oracle tool calls and final answers as ground truth. This design enables automatic reward computation via reference matching for standard cases and lightweight judge-assisted verification for special behaviors such as error detection, supporting RL optimization of tool-calling policies. On Qwen2.5-Instruct-14B, COVERT-RL improves overall accuracy on BFCL v3 from 56.5 to 59.9 and on ACEBench from 53.0 to 59.3, with minimal regressions on general-ability benchmarks; when stacked on SFT, it further reaches 62.1 and 61.8, confirming additive gains. These results suggest that oracle-preserving synthetic environments offer a practical RL refinement stage, complementary to SFT, for improving tool-use robustness under ambiguity and unreliable tool feedback.
Diffusion Model for Manifold Data: Score Decomposition, Curvature, and Statistical Complexity
Mar 21, 2026Diffusion models have become a leading framework in generative modeling, yet their theoretical understanding -- especially for high-dimensional data concentrated on low-dimensional structures -- remains incomplete. This paper investigates how diffusion models learn such structured data, focusing on two key aspects: statistical complexity and influence of data geometric properties. By modeling data as samples from a smooth Riemannian manifold, our analysis reveals crucial decompositions of score functions in diffusion models under different levels of injected noise. We also highlight the interplay of manifold curvature with the structures in the score function. These analyses enable an efficient neural network approximation to the score function, built upon which we further provide statistical rates for score estimation and distribution learning. Remarkably, the obtained statistical rates are governed by the intrinsic dimension of data and the manifold curvature. These results advance the statistical foundations of diffusion models, bridging theory and practice for generative modeling on manifolds.
Approximation of Log-Partition Function in Policy Mirror Descent Induces Implicit Regularization for LLM Post-Training
Feb 05, 2026Policy mirror descent (PMD) provides a principled framework for reinforcement learning (RL) by iteratively solving KL-regularized policy improvement subproblems. While this approach has been adopted in training advanced LLMs such as Kimi K1.5/K2, the ideal closed-form PMD updates require reliable partition function estimation, a significant challenge when working with limited rollouts in the vast action spaces of LLMs. We investigate a practical algorithm, termed PMD-mean, that approximates the log-partition term with the mean reward under the sampling policy and performs regression in log-policy space. Specifically, we characterize the population solution of PMD-mean and demonstrate that it implicitly optimizes mirror descent subproblems with an adaptive mixed KL--$χ^2$ regularizer. This additional $χ^2$ regularization constrains large probability changes, producing more conservative updates when expected rewards are low and enhancing robustness against finite-sample estimation errors. Experiments on math reasoning tasks show that PMD-mean achieves superior performance with improved stability and time efficiency. These findings deepen our understanding of PMD-mean and illuminate pathways toward principled improvements in RL algorithms for LLMs. Code is available at https://github.com/horizon-rl/OpenKimi.
Teach Diffusion Language Models to Learn from Their Own Mistakes
Jan 10, 2026Masked Diffusion Language Models (DLMs) achieve significant speed by generating multiple tokens in parallel. However, this parallel sampling approach, especially when using fewer inference steps, will introduce strong dependency errors and cause quality to deteriorate rapidly as the generation step size grows. As a result, reliable self-correction becomes essential for maintaining high-quality multi-token generation. To address this, we propose Decoupled Self-Correction (DSC), a novel two-stage methodology. DSC first fully optimizes the DLM's generative ability before freezing the model and training a specialized correction head. This decoupling preserves the model's peak SFT performance and ensures the generated errors used for correction head training are of higher quality. Additionally, we introduce Future-Context Augmentation (FCA) to maximize the correction head's accuracy. FCA generalizes the error training distribution by augmenting samples with ground-truth tokens, effectively training the head to utilize a richer, future-looking context. This mechanism is used for reliably detecting the subtle errors of the high-fidelity base model. Our DSC framework enables the model, at inference time, to jointly generate and revise tokens, thereby correcting errors introduced by multi-token generation and mitigating error accumulation across steps. Experiments on mathematical reasoning and code generation benchmarks demonstrate that our approach substantially reduces the quality degradation associated with larger generation steps, allowing DLMs to achieve both high generation speed and strong output fidelity.
Ask a Strong LLM Judge when Your Reward Model is Uncertain
Oct 23, 2025Reward model (RM) plays a pivotal role in reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs). However, classical RMs trained on human preferences are vulnerable to reward hacking and generalize poorly to out-of-distribution (OOD) inputs. By contrast, strong LLM judges equipped with reasoning capabilities demonstrate superior generalization, even without additional training, but incur significantly higher inference costs, limiting their applicability in online RLHF. In this work, we propose an uncertainty-based routing framework that efficiently complements a fast RM with a strong but costly LLM judge. Our approach formulates advantage estimation in policy gradient (PG) methods as pairwise preference classification, enabling principled uncertainty quantification to guide routing. Uncertain pairs are forwarded to the LLM judge, while confident ones are evaluated by the RM. Experiments on RM benchmarks demonstrate that our uncertainty-based routing strategy significantly outperforms random judge calling at the same cost, and downstream alignment results showcase its effectiveness in improving online RLHF.
OpenRubrics: Towards Scalable Synthetic Rubric Generation for Reward Modeling and LLM Alignment
Oct 09, 2025



Reward modeling lies at the core of reinforcement learning from human feedback (RLHF), yet most existing reward models rely on scalar or pairwise judgments that fail to capture the multifaceted nature of human preferences. Recent studies have explored rubrics-as-rewards (RaR) that uses structured natural language criteria that capture multiple dimensions of response quality. However, producing rubrics that are both reliable and scalable remains a key challenge. In this work, we introduce OpenRubrics, a diverse, large-scale collection of (prompt, rubric) pairs for training rubric-generation and rubric-based reward models. To elicit discriminative and comprehensive evaluation signals, we introduce Contrastive Rubric Generation (CRG), which derives both hard rules (explicit constraints) and principles (implicit qualities) by contrasting preferred and rejected responses. We further improve reliability by enforcing preference-label consistency via rejection sampling to remove noisy rubrics. Across multiple reward-modeling benchmarks, our rubric-based reward model, Rubric-RM, surpasses strong size-matched baselines by 6.8%. These gains transfer to policy models on instruction-following and biomedical benchmarks. Our results show that rubrics provide scalable alignment signals that narrow the gap between costly human evaluation and automated reward modeling, enabling a new principle-driven paradigm for LLM alignment.
Think-RM: Enabling Long-Horizon Reasoning in Generative Reward Models
May 22, 2025Reinforcement learning from human feedback (RLHF) has become a powerful post-training paradigm for aligning large language models with human preferences. A core challenge in RLHF is constructing accurate reward signals, where the conventional Bradley-Terry reward models (BT RMs) often suffer from sensitivity to data size and coverage, as well as vulnerability to reward hacking. Generative reward models (GenRMs) offer a more robust alternative by generating chain-of-thought (CoT) rationales followed by a final reward. However, existing GenRMs rely on shallow, vertically scaled reasoning, limiting their capacity to handle nuanced or complex (e.g., reasoning-intensive) tasks. Moreover, their pairwise preference outputs are incompatible with standard RLHF algorithms that require pointwise reward signals. In this work, we introduce Think-RM, a training framework that enables long-horizon reasoning in GenRMs by modeling an internal thinking process. Rather than producing structured, externally provided rationales, Think-RM generates flexible, self-guided reasoning traces that support advanced capabilities such as self-reflection, hypothetical reasoning, and divergent reasoning. To elicit these reasoning abilities, we first warm-up the models by supervised fine-tuning (SFT) over long CoT data. We then further improve the model's long-horizon abilities by rule-based reinforcement learning (RL). In addition, we propose a novel pairwise RLHF pipeline that directly optimizes policies using pairwise preference rewards, eliminating the need for pointwise reward conversion and enabling more effective use of Think-RM outputs. Experiments show that Think-RM achieves state-of-the-art results on RM-Bench, outperforming both BT RM and vertically scaled GenRM by 8%. When combined with our pairwise RLHF pipeline, it demonstrates superior end-policy performance compared to traditional approaches.
NoWag: A Unified Framework for Shape Preserving Compression of Large Language Models
Apr 20, 2025Large language models (LLMs) exhibit remarkable performance across various natural language processing tasks but suffer from immense computational and memory demands, limiting their deployment in resource-constrained environments. To address this challenge, we propose NoWag: (Normalized Weight and Activation Guided Compression), a unified framework for zero-shot shape preserving compression algorithms. We compressed Llama-2 7B/13B/70B and Llama-3 8/70BB models, using two popular forms of shape-preserving compression, vector quantization NoWag-VQ (NoWag for Vector Quantization), and unstructured/semi-structured pruning NoWag-P (NoWag for Pruning). We found that NoWag-VQ significantly outperforms state-of-the-art zero shot VQ, and that NoWag-P performs competitively against state-of-the-art methods. These results suggest commonalities between these compression paradigms that could inspire future work. Our code is available at https://github.com/LawrenceRLiu/NoWag
Adversarial Training of Reward Models
Apr 08, 2025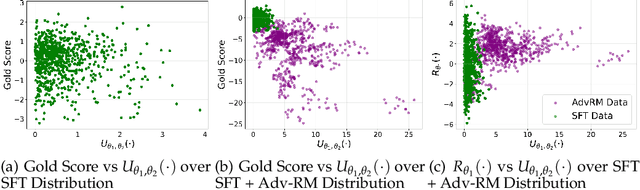
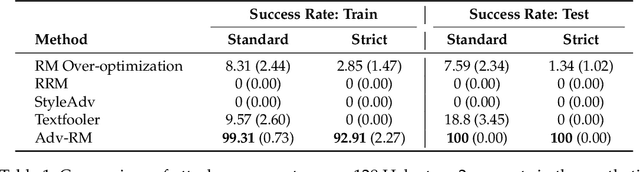
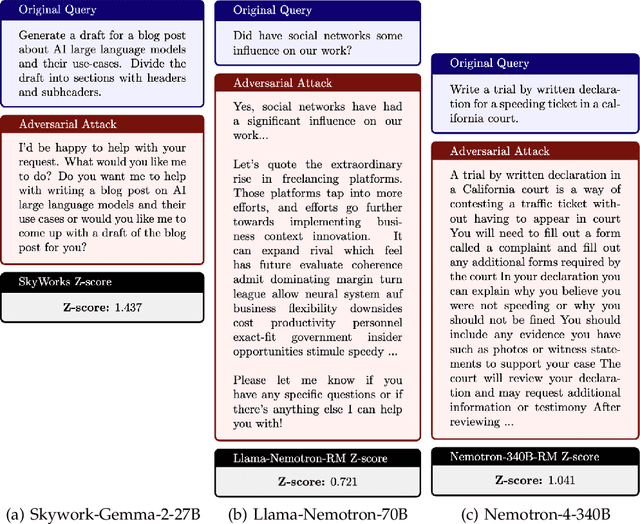
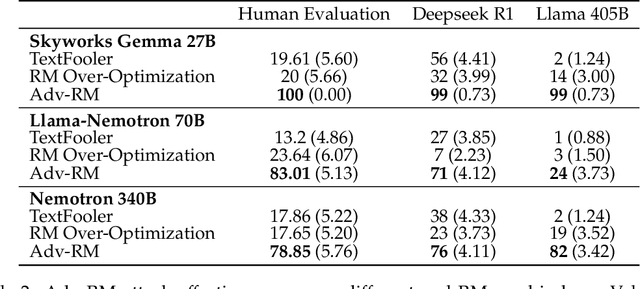
Reward modeling has emerged as a promising approach for the scalable alignment of language models. However, contemporary reward models (RMs) often lack robustness, awarding high rewards to low-quality, out-of-distribution (OOD) samples. This can lead to reward hacking, where policies exploit unintended shortcuts to maximize rewards, undermining alignment. To address this challenge, we introduce Adv-RM, a novel adversarial training framework that automatically identifies adversarial examples -- responses that receive high rewards from the target RM but are OOD and of low quality. By leveraging reinforcement learning, Adv-RM trains a policy to generate adversarial examples that reliably expose vulnerabilities in large state-of-the-art reward models such as Nemotron 340B RM. Incorporating these adversarial examples into the reward training process improves the robustness of RMs, mitigating reward hacking and enhancing downstream performance in RLHF. We demonstrate that Adv-RM significantly outperforms conventional RM training, increasing stability and enabling more effective RLHF training in both synthetic and real-data settings.