 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving Multilingual Long Reasoning via Translation-Reasoning Integrated Training
Feb 05, 2026Long reasoning models often struggle in multilingual settings: they tend to reason in English for non-English questions; when constrained to reasoning in the question language, accuracies drop substantially. The struggle is caused by the limited abilities for both multilingual question understanding and multilingual reasoning. To address both problems, we propose TRIT (Translation-Reasoning Integrated Training), a self-improving framework that integrates the training of translation into multilingual reasoning. Without external feedback or additional multilingual data, our method jointly enhances multilingual question understanding and response generation. On MMATH, our method outperforms multiple baselines by an average of 7 percentage points, improving both answer correctness and language consistency. Further analysis reveals that integrating translation training improves cross-lingual question alignment by over 10 percentage points and enhances translation quality for both mathematical questions and general-domain text, with gains up to 8.4 COMET points on FLORES-200.
NoWag: A Unified Framework for Shape Preserving Compression of Large Language Models
Apr 20, 2025Large language models (LLMs) exhibit remarkable performance across various natural language processing tasks but suffer from immense computational and memory demands, limiting their deployment in resource-constrained environments. To address this challenge, we propose NoWag: (Normalized Weight and Activation Guided Compression), a unified framework for zero-shot shape preserving compression algorithms. We compressed Llama-2 7B/13B/70B and Llama-3 8/70BB models, using two popular forms of shape-preserving compression, vector quantization NoWag-VQ (NoWag for Vector Quantization), and unstructured/semi-structured pruning NoWag-P (NoWag for Pruning). We found that NoWag-VQ significantly outperforms state-of-the-art zero shot VQ, and that NoWag-P performs competitively against state-of-the-art methods. These results suggest commonalities between these compression paradigms that could inspire future work. Our code is available at https://github.com/LawrenceRLiu/NoWag
Finding Fantastic Experts in MoEs: A Unified Study for Expert Dropping Strategies and Observations
Apr 10, 2025Sparsely activated Mixture-of-Experts (SMoE) has shown promise in scaling up the learning capacity of neural networks. However, vanilla SMoEs have issues such as expert redundancy and heavy memory requirements, making them inefficient and non-scalable, especially for resource-constrained scenarios. Expert-level sparsification of SMoEs involves pruning the least important experts to address these limitations. In this work, we aim to address three questions: (1) What is the best recipe to identify the least knowledgeable subset of experts that can be dropped with minimal impact on performance? (2) How should we perform expert dropping (one-shot or iterative), and what correction measures can we undertake to minimize its drastic impact on SMoE subnetwork capabilities? (3) What capabilities of full-SMoEs are severely impacted by the removal of the least dominant experts, and how can we recover them? Firstly, we propose MoE Experts Compression Suite (MC-Suite), which is a collection of some previously explored and multiple novel recipes to provide a comprehensive benchmark for estimating expert importance from diverse perspectives, as well as unveil numerous valuable insights for SMoE experts. Secondly, unlike prior works with a one-shot expert pruning approach, we explore the benefits of iterative pruning with the re-estimation of the MC-Suite criterion. Moreover, we introduce the benefits of task-agnostic fine-tuning as a correction mechanism during iterative expert dropping, which we term MoE Lottery Subnetworks. Lastly, we present an experimentally validated conjecture that, during expert dropping, SMoEs' instruction-following capabilities are predominantly hurt, which can be restored to a robust level subject to external augmentation of instruction-following capabilities using k-shot examples and supervised fine-tuning.
IDEA Prune: An Integrated Enlarge-and-Prune Pipeline in Generative Language Model Pretraining
Mar 07, 2025Recent advancements in large language models have intensified the need for efficient and deployable models within limited inference budgets. Structured pruning pipelines have shown promise in token efficiency compared to training target-size models from scratch. In this paper, we advocate incorporating enlarged model pretraining, which is often ignored in previous works, into pruning. We study the enlarge-and-prune pipeline as an integrated system to address two critical questions: whether it is worth pretraining an enlarged model even when the model is never deployed, and how to optimize the entire pipeline for better pruned models. We propose an integrated enlarge-and-prune pipeline, which combines enlarge model training, pruning, and recovery under a single cosine annealing learning rate schedule. This approach is further complemented by a novel iterative structured pruning method for gradual parameter removal. The proposed method helps to mitigate the knowledge loss caused by the rising learning rate in naive enlarge-and-prune pipelines and enable effective redistribution of model capacity among surviving neurons, facilitating smooth compression and enhanced performance. We conduct comprehensive experiments on compressing 2.8B models to 1.3B with up to 2T tokens in pretraining. It demonstrates the integrated approach not only provides insights into the token efficiency of enlarged model pretraining but also achieves superior performance of pruned models.
TINQ: Temporal Inconsistency Guided Blind Video Quality Assessment
Dec 25, 2024Blind video quality assessment (BVQA) has been actively researched for user-generated content (UGC) videos. Recently, super-resolution (SR) techniques have been widely applied in UGC. Therefore, an effective BVQA method for both UGC and SR scenarios is essential. Temporal inconsistency, referring to irregularities between consecutive frames, is relevant to video quality. Current BVQA approaches typically model temporal relationships in UGC videos using statistics of motion information, but inconsistencies remain unexplored. Additionally, different from temporal inconsistency in UGC videos, such inconsistency in SR videos is amplified due to upscaling algorithms. In this paper, we introduce the Temporal Inconsistency Guided Blind Video Quality Assessment (TINQ) metric, demonstrating that exploring temporal inconsistency is crucial for effective BVQA. Since temporal inconsistencies vary between UGC and SR videos, they are calculated in different ways. Based on this, a spatial module highlights inconsistent areas across consecutive frames at coarse and fine granularities. In addition, a temporal module aggregates features over time in two stages. The first stage employs a visual memory capacity block to adaptively segment the time dimension based on estimated complexity, while the second stage focuses on selecting key features. The stages work together through Consistency-aware Fusion Units to regress cross-time-scale video quality. Extensive experiments on UGC and SR video quality datasets show that our method outperforms existing state-of-the-art BVQA methods. Code is available at https://github.com/Lighting-YXLI/TINQ.
Adaptive Preference Scaling for Reinforcement Learning with Human Feedback
Jun 04, 2024Reinforcement learning from human feedback (RLHF) is a prevalent approach to align AI systems with human values by learning rewards from human preference data. Due to various reasons, however, such data typically takes the form of rankings over pairs of trajectory segments, which fails to capture the varying strengths of preferences across different pairs. In this paper, we propose a novel adaptive preference loss, underpinned by distributionally robust optimization (DRO), designed to address this uncertainty in preference strength. By incorporating an adaptive scaling parameter into the loss for each pair, our method increases the flexibility of the reward function. Specifically, it assigns small scaling parameters to pairs with ambiguous preferences, leading to more comparable rewards, and large scaling parameters to those with clear preferences for more distinct rewards. Computationally, our proposed loss function is strictly convex and univariate with respect to each scaling parameter, enabling its efficient optimization through a simple second-order algorithm. Our method is versatile and can be readily adapted to various preference optimization frameworks, including direct preference optimization (DPO). Our experiments with robotic control and natural language generation with large language models (LLMs) show that our method not only improves policy performance but also aligns reward function selection more closely with policy optimization, simplifying the hyperparameter tuning process.
DBPF: A Framework for Efficient and Robust Dynamic Bin-Picking
Mar 25, 2024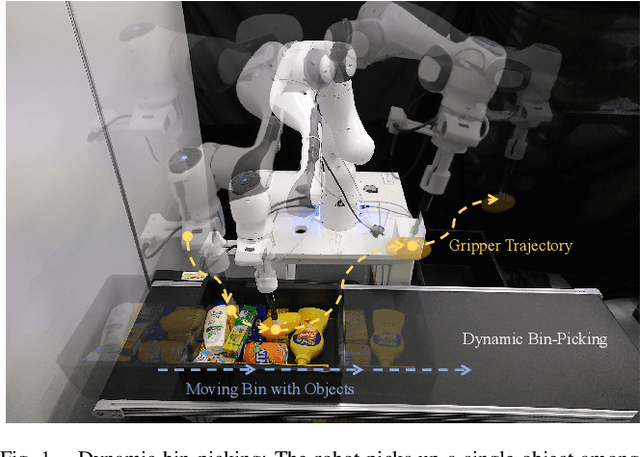
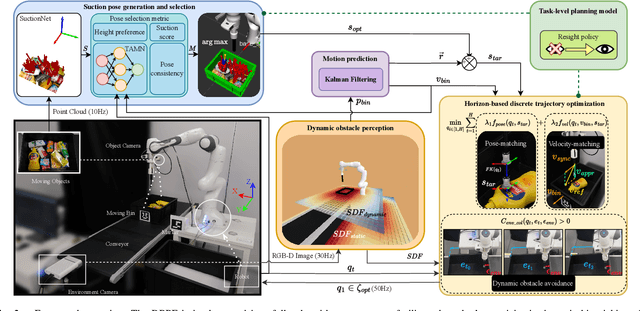
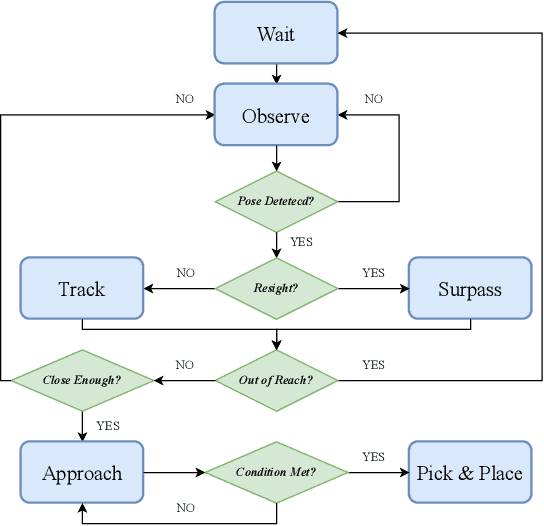

Efficiency and reliability are critical in robotic bin-picking as they directly impact the productivity of automated industrial processes. However, traditional approaches, demanding static objects and fixed collisions, lead to deployment limitations, operational inefficiencies, and process unreliability. This paper introduces a Dynamic Bin-Picking Framework (DBPF) that challenges traditional static assumptions. The DBPF endows the robot with the reactivity to pick multiple moving arbitrary objects while avoiding dynamic obstacles, such as the moving bin. Combined with scene-level pose generation, the proposed pose selection metric leverages the Tendency-Aware Manipulability Network optimizing suction pose determination. Heuristic task-specific designs like velocity-matching, dynamic obstacle avoidance, and the resight policy, enhance the picking success rate and reliability. Empirical experiments demonstrate the importance of these components. Our method achieves an average 84% success rate, surpassing the 60% of the most comparable baseline, crucially, with zero collisions. Further evaluations under diverse dynamic scenarios showcase DBPF's robust performance in dynamic bin-picking. Results suggest that our framework offers a promising solution for efficient and reliable robotic bin-picking under dynamics.
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models
Oct 23, 2023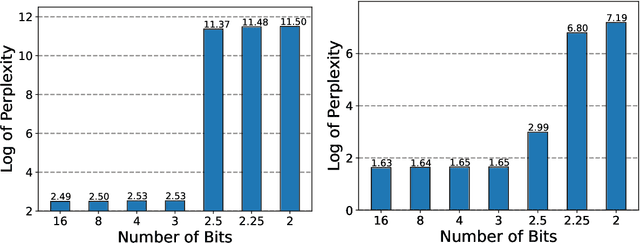
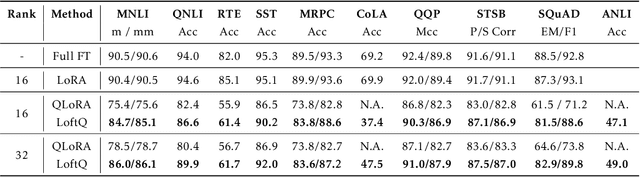
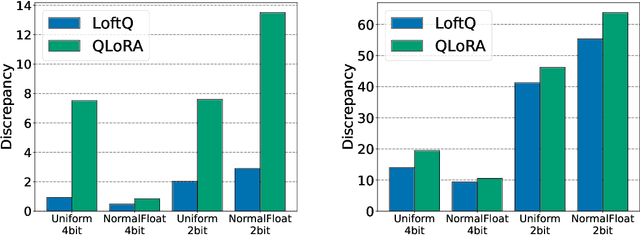
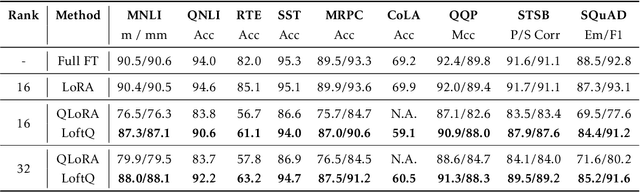
Quantization is an indispensable technique for serving Large Language Models (LLMs) and has recently found its way into LoRA fine-tuning. In this work we focus on the scenario where quantization and LoRA fine-tuning are applied together on a pre-trained model. In such cases it is common to observe a consistent gap in the performance on downstream tasks between full fine-tuning and quantization plus LoRA fine-tuning approach. In response, we propose LoftQ (LoRA-Fine-Tuning-aware Quantization), a novel quantization framework that simultaneously quantizes an LLM and finds a proper low-rank initialization for LoRA fine-tuning. Such an initialization alleviates the discrepancy between the quantized and full-precision model and significantly improves the generalization in downstream tasks. We evaluate our method on natural language understanding, question answering, summarization, and natural language generation tasks. Experiments show that our method is highly effective and outperforms existing quantization methods, especially in the challenging 2-bit and 2/4-bit mixed precision regimes. We will release our code.
Deep Reinforcement Learning from Hierarchical Weak Preference Feedback
Sep 06, 2023Reward design is a fundamental, yet challenging aspect of practical reinforcement learning (RL). For simple tasks, researchers typically handcraft the reward function, e.g., using a linear combination of several reward factors. However, such reward engineering is subject to approximation bias, incurs large tuning cost, and often cannot provide the granularity required for complex tasks. To avoid these difficulties, researchers have turned to reinforcement learning from human feedback (RLHF), which learns a reward function from human preferences between pairs of trajectory sequences. By leveraging preference-based reward modeling, RLHF learns complex rewards that are well aligned with human preferences, allowing RL to tackle increasingly difficult problems. Unfortunately, the applicability of RLHF is limited due to the high cost and difficulty of obtaining human preference data. In light of this cost, we investigate learning reward functions for complex tasks with less human effort; simply by ranking the importance of the reward factors. More specifically, we propose a new RL framework -- HERON, which compares trajectories using a hierarchical decision tree induced by the given ranking. These comparisons are used to train a preference-based reward model, which is then used for policy learning. We find that our framework can not only train high performing agents on a variety of difficult tasks, but also provide additional benefits such as improved sample efficiency and robustness. Our code is available at https://github.com/abukharin3/HERON.
LoSparse: Structured Compression of Large Language Models based on Low-Rank and Sparse Approximation
Jun 26, 2023Transformer models have achieved remarkable results in various natural language tasks, but they are often prohibitively large, requiring massive memories and computational resources. To reduce the size and complexity of these models, we propose LoSparse (Low-Rank and Sparse approximation), a novel model compression technique that approximates a weight matrix by the sum of a low-rank matrix and a sparse matrix. Our method combines the advantages of both low-rank approximations and pruning, while avoiding their limitations. Low-rank approximation compresses the coherent and expressive parts in neurons, while pruning removes the incoherent and non-expressive parts in neurons. Pruning enhances the diversity of low-rank approximations, and low-rank approximation prevents pruning from losing too many expressive neurons. We evaluate our method on natural language understanding, question answering, and natural language generation tasks. We show that it significantly outperforms existing compression methods.