 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Disentanglement for Full-Reference Image Quality Assessment
Apr 23, 2026Existing deep network-based full-reference image quality assessment (FR-IQA) models typically work by performing pairwise comparisons of deep features from the reference and distorted images. In this paper, we approach this problem from a different perspective and propose a novel FR-IQA paradigm based on causal inference and decoupled representation learning. Unlike typical feature comparison-based FR-IQA models, our approach formulates degradation estimation as a causal disentanglement process guided by intervention on latent representations. We first decouple degradation and content representations by exploiting the content invariance between the reference and distorted images. Second, inspired by the human visual masking effect, we design a masking module to model the causal relationship between image content and degradation features, thereby extracting content-influenced degradation features from distorted images. Finally, quality scores are predicted from these degradation features using either supervised regression or label-free dimensionality reduction. Extensive experiments demonstrate that our method achieves highly competitive performance on standard IQA benchmarks across fully supervised, few-label, and label-free settings. Furthermore, we evaluate the approach on diverse non-standard natural image domains with scarce data, including underwater, radiographic, medical, neutron, and screen-content images. Benefiting from its ability to perform scenario-specific training and prediction without labeled IQA data, our method exhibits superior cross-domain generalization compared to existing training-free FR-IQA models.
Atlas-Assisted Segment Anything Model for Fetal Brain MRI (FeTal-SAM)
Jan 22, 2026This paper presents FeTal-SAM, a novel adaptation of the Segment Anything Model (SAM) tailored for fetal brain MRI segmentation. Traditional deep learning methods often require large annotated datasets for a fixed set of labels, making them inflexible when clinical or research needs change. By integrating atlas-based prompts and foundation-model principles, FeTal-SAM addresses two key limitations in fetal brain MRI segmentation: (1) the need to retrain models for varying label definitions, and (2) the lack of insight into whether segmentations are driven by genuine image contrast or by learned spatial priors. We leverage multi-atlas registration to generate spatially aligned label templates that serve as dense prompts, alongside a bounding-box prompt, for SAM's segmentation decoder. This strategy enables binary segmentation on a per-structure basis, which is subsequently fused to reconstruct the full 3D segmentation volumes. Evaluations on two datasets, the dHCP dataset and an in-house dataset demonstrate FeTal-SAM's robust performance across gestational ages. Notably, it achieves Dice scores comparable to state-of-the-art baselines which were trained for each dataset and label definition for well-contrasted structures like cortical plate and cerebellum, while maintaining the flexibility to segment any user-specified anatomy. Although slightly lower accuracy is observed for subtle, low-contrast structures (e.g., hippocampus, amygdala), our results highlight FeTal-SAM's potential to serve as a general-purpose segmentation model without exhaustive retraining. This method thus constitutes a promising step toward clinically adaptable fetal brain MRI analysis tools.
PathoSyn: Imaging-Pathology MRI Synthesis via Disentangled Deviation Diffusion
Dec 29, 2025We present PathoSyn, a unified generative framework for Magnetic Resonance Imaging (MRI) image synthesis that reformulates imaging-pathology as a disentangled additive deviation on a stable anatomical manifold. Current generative models typically operate in the global pixel domain or rely on binary masks, these paradigms often suffer from feature entanglement, leading to corrupted anatomical substrates or structural discontinuities. PathoSyn addresses these limitations by decomposing the synthesis task into deterministic anatomical reconstruction and stochastic deviation modeling. Central to our framework is a Deviation-Space Diffusion Model designed to learn the conditional distribution of pathological residuals, thereby capturing localized intensity variations while preserving global structural integrity by construction. To ensure spatial coherence, the diffusion process is coupled with a seam-aware fusion strategy and an inference-time stabilization module, which collectively suppress boundary artifacts and produce high-fidelity internal lesion heterogeneity. PathoSyn provides a mathematically principled pipeline for generating high-fidelity patient-specific synthetic datasets, facilitating the development of robust diagnostic algorithms in low-data regimes. By allowing interpretable counterfactual disease progression modeling, the framework supports precision intervention planning and provides a controlled environment for benchmarking clinical decision-support systems. Quantitative and qualitative evaluations on tumor imaging benchmarks demonstrate that PathoSyn significantly outperforms holistic diffusion and mask-conditioned baselines in both perceptual realism and anatomical fidelity. The source code of this work will be made publicly available.
Integrating SAM Supervision for 3D Weakly Supervised Point Cloud Segmentation
Aug 27, 2025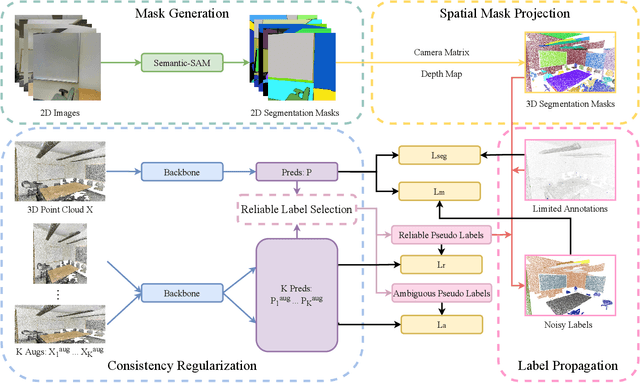
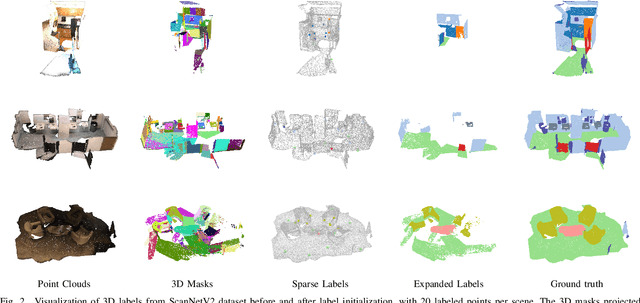


Current methods for 3D semantic segmentation propose training models with limited annotations to address the difficulty of annotating large, irregular, and unordered 3D point cloud data. They usually focus on the 3D domain only, without leveraging the complementary nature of 2D and 3D data. Besides, some methods extend original labels or generate pseudo labels to guide the training, but they often fail to fully use these labels or address the noise within them. Meanwhile, the emergence of comprehensive and adaptable foundation models has offered effective solutions for segmenting 2D data. Leveraging this advancement, we present a novel approach that maximizes the utility of sparsely available 3D annotations by incorporating segmentation masks generated by 2D foundation models. We further propagate the 2D segmentation masks into the 3D space by establishing geometric correspondences between 3D scenes and 2D views. We extend the highly sparse annotations to encompass the areas delineated by 3D masks, thereby substantially augmenting the pool of available labels. Furthermore, we apply confidence- and uncertainty-based consistency regularization on augmentations of the 3D point cloud and select the reliable pseudo labels, which are further spread on the 3D masks to generate more labels. This innovative strategy bridges the gap between limited 3D annotations and the powerful capabilities of 2D foundation models, ultimately improving the performance of 3D weakly supervised segmentation.
Modality-Aware Feature Matching: A Comprehensive Review of Single- and Cross-Modality Techniques
Jul 30, 2025



Feature matching is a cornerstone task in computer vision, essential for applications such as image retrieval, stereo matching, 3D reconstruction, and SLAM. This survey comprehensively reviews modality-based feature matching, exploring traditional handcrafted methods and emphasizing contemporary deep learning approaches across various modalities, including RGB images, depth images, 3D point clouds, LiDAR scans, medical images, and vision-language interactions. Traditional methods, leveraging detectors like Harris corners and descriptors such as SIFT and ORB, demonstrate robustness under moderate intra-modality variations but struggle with significant modality gaps. Contemporary deep learning-based methods, exemplified by detector-free strategies like CNN-based SuperPoint and transformer-based LoFTR, substantially improve robustness and adaptability across modalities. We highlight modality-aware advancements, such as geometric and depth-specific descriptors for depth images, sparse and dense learning methods for 3D point clouds, attention-enhanced neural networks for LiDAR scans, and specialized solutions like the MIND descriptor for complex medical image matching. Cross-modal applications, particularly in medical image registration and vision-language tasks, underscore the evolution of feature matching to handle increasingly diverse data interactions.
Attribute-formed Class-specific Concept Space: Endowing Language Bottleneck Model with Better Interpretability and Scalability
Mar 26, 2025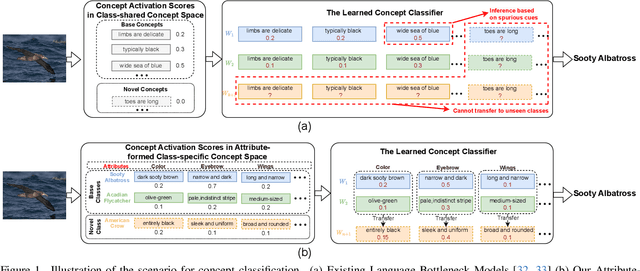

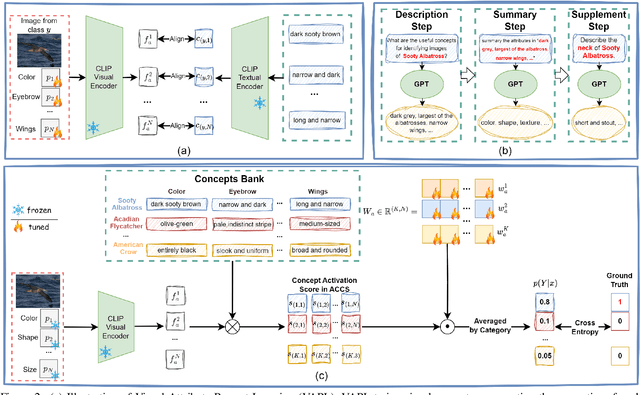

Language Bottleneck Models (LBMs) are proposed to achieve interpretable image recognition by classifying images based on textual concept bottlenecks. However, current LBMs simply list all concepts together as the bottleneck layer, leading to the spurious cue inference problem and cannot generalized to unseen classes. To address these limitations, we propose the Attribute-formed Language Bottleneck Model (ALBM). ALBM organizes concepts in the attribute-formed class-specific space, where concepts are descriptions of specific attributes for specific classes. In this way, ALBM can avoid the spurious cue inference problem by classifying solely based on the essential concepts of each class. In addition, the cross-class unified attribute set also ensures that the concept spaces of different classes have strong correlations, as a result, the learned concept classifier can be easily generalized to unseen classes. Moreover, to further improve interpretability, we propose Visual Attribute Prompt Learning (VAPL) to extract visual features on fine-grained attributes. Furthermore, to avoid labor-intensive concept annotation, we propose the Description, Summary, and Supplement (DSS) strategy to automatically generate high-quality concept sets with a complete and precise attribute. Extensive experiments on 9 widely used few-shot benchmarks demonstrate the interpretability, transferability, and performance of our approach. The code and collected concept sets are available at https://github.com/tiggers23/ALBM.
Diffusion-based Facial Aesthetics Enhancement with 3D Structure Guidance
Mar 18, 2025Facial Aesthetics Enhancement (FAE) aims to improve facial attractiveness by adjusting the structure and appearance of a facial image while preserving its identity as much as possible. Most existing methods adopted deep feature-based or score-based guidance for generation models to conduct FAE. Although these methods achieved promising results, they potentially produced excessively beautified results with lower identity consistency or insufficiently improved facial attractiveness. To enhance facial aesthetics with less loss of identity, we propose the Nearest Neighbor Structure Guidance based on Diffusion (NNSG-Diffusion), a diffusion-based FAE method that beautifies a 2D facial image with 3D structure guidance. Specifically, we propose to extract FAE guidance from a nearest neighbor reference face. To allow for less change of facial structures in the FAE process, a 3D face model is recovered by referring to both the matched 2D reference face and the 2D input face, so that the depth and contour guidance can be extracted from the 3D face model. Then the depth and contour clues can provide effective guidance to Stable Diffusion with ControlNet for FAE. Extensive experiments demonstrate that our method is superior to previous relevant methods in enhancing facial aesthetics while preserving facial identity.
Multitask Auxiliary Network for Perceptual Quality Assessment of Non-Uniformly Distorted Omnidirectional Images
Jan 20, 2025Omnidirectional image quality assessment (OIQA) has been widely investigated in the past few years and achieved much success. However, most of existing studies are dedicated to solve the uniform distortion problem in OIQA, which has a natural gap with the non-uniform distortion problem, and their ability in capturing non-uniform distortion is far from satisfactory. To narrow this gap, in this paper, we propose a multitask auxiliary network for non-uniformly distorted omnidirectional images, where the parameters are optimized by jointly training the main task and other auxiliary tasks. The proposed network mainly consists of three parts: a backbone for extracting multiscale features from the viewport sequence, a multitask feature selection module for dynamically allocating specific features to different tasks, and auxiliary sub-networks for guiding the proposed model to capture local distortion and global quality change. Extensive experiments conducted on two large-scale OIQA databases demonstrate that the proposed model outperforms other state-of-the-art OIQA metrics, and these auxiliary sub-networks contribute to improve the performance of the proposed model. The source code is available at https://github.com/RJL2000/MTAOIQA.
Video Quality Assessment for Online Processing: From Spatial to Temporal Sampling
Jan 13, 2025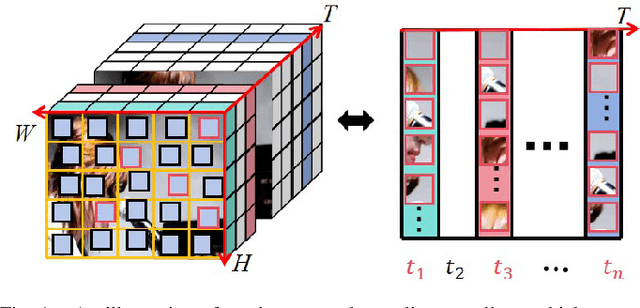
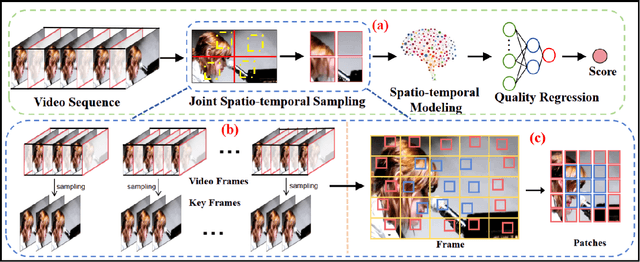
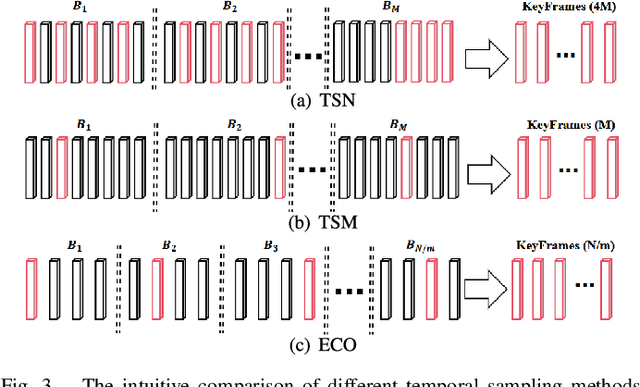
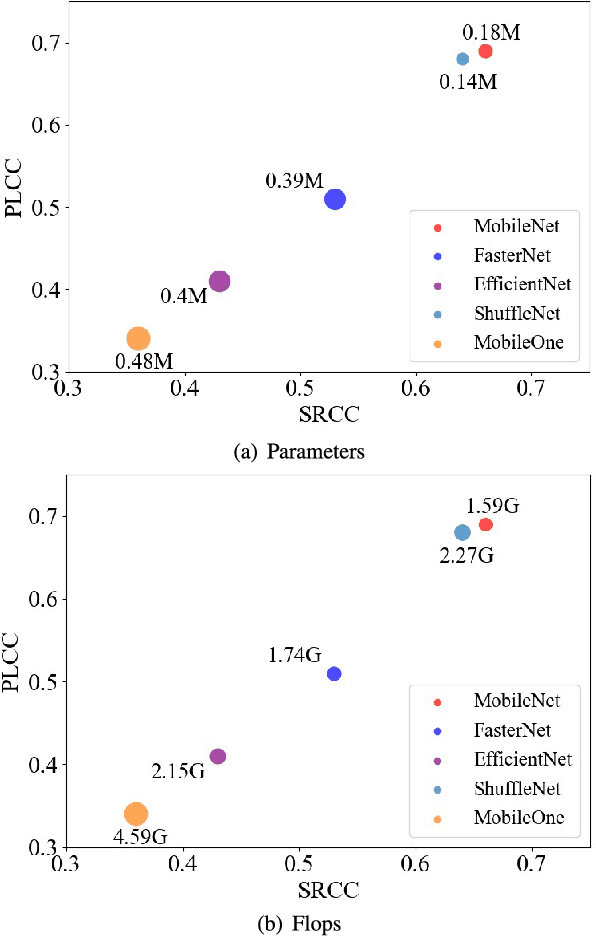
With the rapid development of multimedia processing and deep learning technologies, especially in the field of video understanding, video quality assessment (VQA) has achieved significant progress. Although researchers have moved from designing efficient video quality mapping models to various research directions, in-depth exploration of the effectiveness-efficiency trade-offs of spatio-temporal modeling in VQA models is still less sufficient. Considering the fact that videos have highly redundant information, this paper investigates this problem from the perspective of joint spatial and temporal sampling, aiming to seek the answer to how little information we should keep at least when feeding videos into the VQA models while with acceptable performance sacrifice. To this end, we drastically sample the video's information from both spatial and temporal dimensions, and the heavily squeezed video is then fed into a stable VQA model. Comprehensive experiments regarding joint spatial and temporal sampling are conducted on six public video quality databases, and the results demonstrate the acceptable performance of the VQA model when throwing away most of the video information. Furthermore, with the proposed joint spatial and temporal sampling strategy, we make an initial attempt to design an online VQA model, which is instantiated by as simple as possible a spatial feature extractor, a temporal feature fusion module, and a global quality regression module. Through quantitative and qualitative experiments, we verify the feasibility of online VQA model by simplifying itself and reducing input.
TINQ: Temporal Inconsistency Guided Blind Video Quality Assessment
Dec 25, 2024Blind video quality assessment (BVQA) has been actively researched for user-generated content (UGC) videos. Recently, super-resolution (SR) techniques have been widely applied in UGC. Therefore, an effective BVQA method for both UGC and SR scenarios is essential. Temporal inconsistency, referring to irregularities between consecutive frames, is relevant to video quality. Current BVQA approaches typically model temporal relationships in UGC videos using statistics of motion information, but inconsistencies remain unexplored. Additionally, different from temporal inconsistency in UGC videos, such inconsistency in SR videos is amplified due to upscaling algorithms. In this paper, we introduce the Temporal Inconsistency Guided Blind Video Quality Assessment (TINQ) metric, demonstrating that exploring temporal inconsistency is crucial for effective BVQA. Since temporal inconsistencies vary between UGC and SR videos, they are calculated in different ways. Based on this, a spatial module highlights inconsistent areas across consecutive frames at coarse and fine granularities. In addition, a temporal module aggregates features over time in two stages. The first stage employs a visual memory capacity block to adaptively segment the time dimension based on estimated complexity, while the second stage focuses on selecting key features. The stages work together through Consistency-aware Fusion Units to regress cross-time-scale video quality. Extensive experiments on UGC and SR video quality datasets show that our method outperforms existing state-of-the-art BVQA methods. Code is available at https://github.com/Lighting-YXLI/TINQ.