 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Quality Assessment for Online Processing: From Spatial to Temporal Sampling
Jan 13, 2025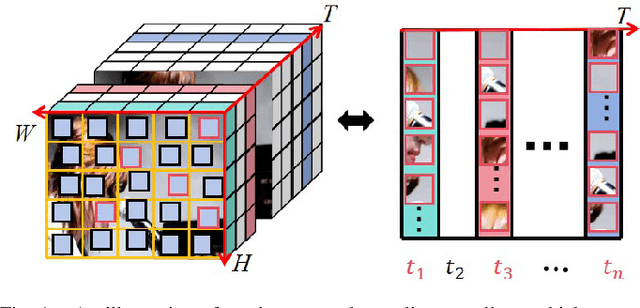
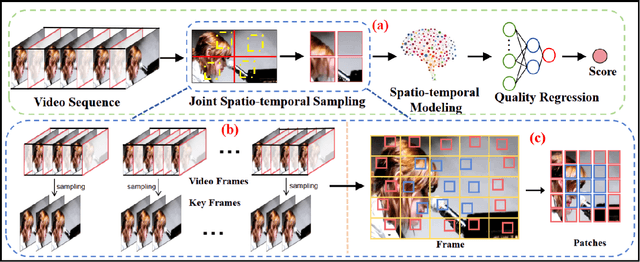
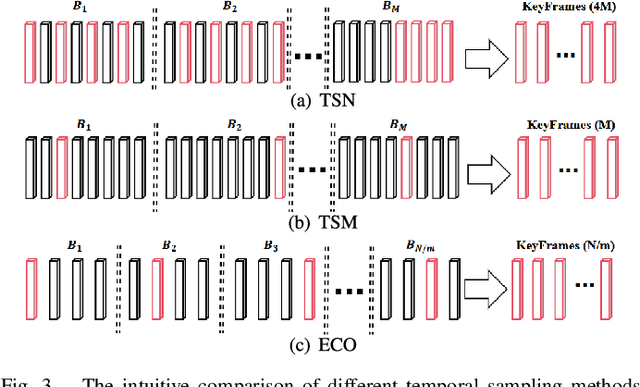
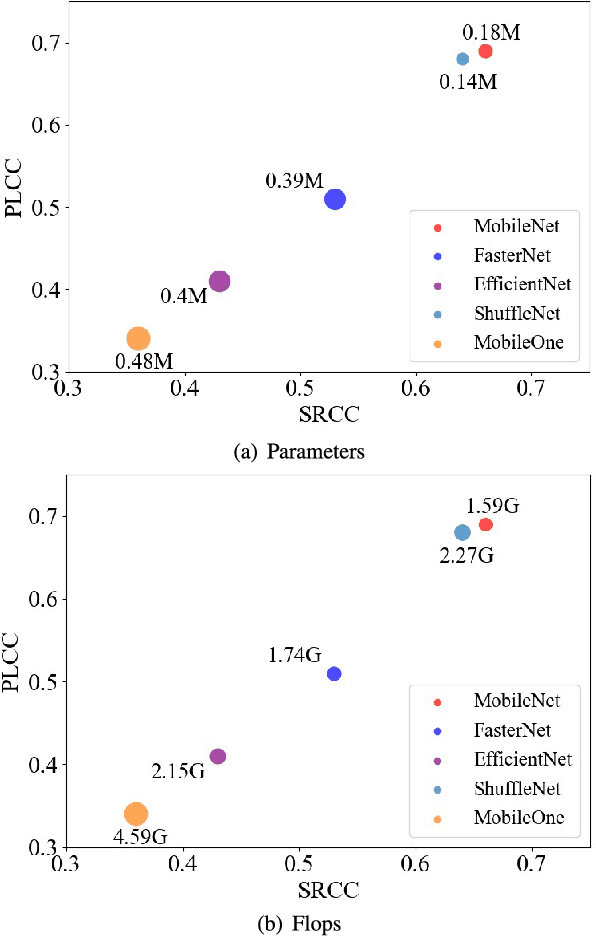
With the rapid development of multimedia processing and deep learning technologies, especially in the field of video understanding, video quality assessment (VQA) has achieved significant progress. Although researchers have moved from designing efficient video quality mapping models to various research directions, in-depth exploration of the effectiveness-efficiency trade-offs of spatio-temporal modeling in VQA models is still less sufficient. Considering the fact that videos have highly redundant information, this paper investigates this problem from the perspective of joint spatial and temporal sampling, aiming to seek the answer to how little information we should keep at least when feeding videos into the VQA models while with acceptable performance sacrifice. To this end, we drastically sample the video's information from both spatial and temporal dimensions, and the heavily squeezed video is then fed into a stable VQA model. Comprehensive experiments regarding joint spatial and temporal sampling are conducted on six public video quality databases, and the results demonstrate the acceptable performance of the VQA model when throwing away most of the video information. Furthermore, with the proposed joint spatial and temporal sampling strategy, we make an initial attempt to design an online VQA model, which is instantiated by as simple as possible a spatial feature extractor, a temporal feature fusion module, and a global quality regression module. Through quantitative and qualitative experiments, we verify the feasibility of online VQA model by simplifying itself and reducing input.
Evaluating Moral Beliefs across LLMs through a Pluralistic Framework
Nov 06, 2024Proper moral beliefs are fundamental for language models, yet assessing these beliefs poses a significant challenge. This study introduces a novel three-module framework to evaluate the moral beliefs of four prominent large language models. Initially, we constructed a dataset containing 472 moral choice scenarios in Chinese, derived from moral words. The decision-making process of the models in these scenarios reveals their moral principle preferences. By ranking these moral choices, we discern the varying moral beliefs held by different language models. Additionally, through moral debates, we investigate the firmness of these models to their moral choices. Our findings indicate that English language models, namely ChatGPT and Gemini, closely mirror moral decisions of the sample of Chinese university students, demonstrating strong adherence to their choices and a preference for individualistic moral beliefs. In contrast, Chinese models such as Ernie and ChatGLM lean towards collectivist moral beliefs, exhibiting ambiguity in their moral choices and debates. This study also uncovers gender bias embedded within the moral beliefs of all examined language models. Our methodology offers an innovative means to assess moral beliefs in both artificial and human intelligence, facilitating a comparison of moral values across different cultures.
FakeBench: Uncover the Achilles' Heels of Fake Images with Large Multimodal Models
Apr 20, 2024



Recently, fake images generated by artificial intelligence (AI) models have become indistinguishable from the real, exerting new challenges for fake image detection models. To this extent, simple binary judgments of real or fake seem less convincing and credible due to the absence of human-understandable explanations. Fortunately, Large Multimodal Models (LMMs) bring possibilities to materialize the judgment process while their performance remains undetermined. Therefore, we propose FakeBench, the first-of-a-kind benchmark towards transparent defake, consisting of fake images with human language descriptions on forgery signs. FakeBench gropes for two open questions of LMMs: (1) can LMMs distinguish fake images generated by AI, and (2) how do LMMs distinguish fake images? In specific, we construct the FakeClass dataset with 6k diverse-sourced fake and real images, each equipped with a Question&Answer pair concerning the authenticity of images, which are utilized to benchmark the detection ability. To examine the reasoning and interpretation abilities of LMMs, we present the FakeClue dataset, consisting of 15k pieces of descriptions on the telltale clues revealing the falsification of fake images. Besides, we construct the FakeQA to measure the LMMs' open-question answering ability on fine-grained authenticity-relevant aspects. Our experimental results discover that current LMMs possess moderate identification ability, preliminary interpretation and reasoning ability, and passable open-question answering ability for image defake. The FakeBench will be made publicly available soon.
2AFC Prompting of Large Multimodal Models for Image Quality Assessment
Feb 02, 2024



While abundant research has been conducted on improving high-level visual understanding and reasoning capabilities of large multimodal models~(LMMs), their visual quality assessment~(IQA) ability has been relatively under-explored. Here we take initial steps towards this goal by employing the two-alternative forced choice~(2AFC) prompting, as 2AFC is widely regarded as the most reliable way of collecting human opinions of visual quality. Subsequently, the global quality score of each image estimated by a particular LMM can be efficiently aggregated using the maximum a posterior estimation. Meanwhile, we introduce three evaluation criteria: consistency, accuracy, and correlation, to provide comprehensive quantifications and deeper insights into the IQA capability of five LMMs. Extensive experiments show that existing LMMs exhibit remarkable IQA ability on coarse-grained quality comparison, but there is room for improvement on fine-grained quality discrimination. The proposed dataset sheds light on the future development of IQA models based on LMMs. The codes will be made publicly available at https://github.com/h4nwei/2AFC-LMMs.
Perceptual Quality Assessment of 360$^\circ$ Images Based on Generative Scanpath Representation
Sep 07, 2023



Despite substantial efforts dedicated to the design of heuristic models for omnidirectional (i.e., 360$^\circ$) image quality assessment (OIQA), a conspicuous gap remains due to the lack of consideration for the diversity of viewing behaviors that leads to the varying perceptual quality of 360$^\circ$ images. Two critical aspects underline this oversight: the neglect of viewing conditions that significantly sway user gaze patterns and the overreliance on a single viewport sequence from the 360$^\circ$ image for quality inference. To address these issues, we introduce a unique generative scanpath representation (GSR) for effective quality inference of 360$^\circ$ images, which aggregates varied perceptual experiences of multi-hypothesis users under a predefined viewing condition. More specifically, given a viewing condition characterized by the starting point of viewing and exploration time, a set of scanpaths consisting of dynamic visual fixations can be produced using an apt scanpath generator. Following this vein, we use the scanpaths to convert the 360$^\circ$ image into the unique GSR, which provides a global overview of gazed-focused contents derived from scanpaths. As such, the quality inference of the 360$^\circ$ image is swiftly transformed to that of GSR. We then propose an efficient OIQA computational framework by learning the quality maps of GSR. Comprehensive experimental results validate that the predictions of the proposed framework are highly consistent with human perception in the spatiotemporal domain, especially in the challenging context of locally distorted 360$^\circ$ images under varied viewing conditions. The code will be released at https://github.com/xiangjieSui/GSR