 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAblateCell: A Reproduce-then-Ablate Agent for Virtual Cell Repositories
Apr 21, 2026Systematic ablations are essential to attribute performance gains in AI Virtual Cells, yet they are rarely performed because biological repositories are under-standardized and tightly coupled to domain-specific data and formats. While recent coding agents can translate ideas into implementations, they typically stop at producing code and lack a verifier that can reproduce strong baselines and rigorously test which components truly matter. We introduce AblateCell, a reproduce-then-ablate agent for virtual cell repositories that closes this verification gap. AblateCell first reproduces reported baselines end-to-end by auto-configuring environments, resolving dependency and data issues, and rerunning official evaluations while emitting verifiable artifacts. It then conducts closed-loop ablation by generating a graph of isolated repository mutations and adaptively selecting experiments under a reward that trades off performance impact and execution cost. Evaluated on three single-cell perturbation prediction repositories (CPA, GEARS, BioLORD), AblateCell achieves 88.9% (+29.9% to human expert) end-to-end workflow success and 93.3% (+53.3% to heuristic) accuracy in recovering ground-truth critical components. These results enable scalable, repository-grounded verification and attribution directly on biological codebases.
HarmonyCell: Automating Single-Cell Perturbation Modeling under Semantic and Distribution Shifts
Mar 02, 2026Single-cell perturbation studies face dual heterogeneity bottlenecks: (i) semantic heterogeneity--identical biological concepts encoded under incompatible metadata schemas across datasets; and (ii) statistical heterogeneity--distribution shifts from biological variation demanding dataset-specific inductive biases. We propose HarmonyCell, an end-to-end agent framework resolving each challenge through a dedicated mechanism: an LLM-driven Semantic Unifier autonomously maps disparate metadata into a canonical interface without manual intervention; and an adaptive Monte Carlo Tree Search engine operates over a hierarchical action space to synthesize architectures with optimal statistical inductive biases for distribution shifts. Evaluated across diverse perturbation tasks under both semantic and distribution shifts, HarmonyCell achieves a 95% valid execution rate on heterogeneous input datasets (versus 0% for general agents) while matching or even exceeding expert-designed baselines in rigorous out-of-distribution evaluations. This dual-track orchestration enables scalable automatic virtual cell modeling without dataset-specific engineering.
MapSAM2: Adapting SAM2 for Automatic Segmentation of Historical Map Images and Time Series
Oct 31, 2025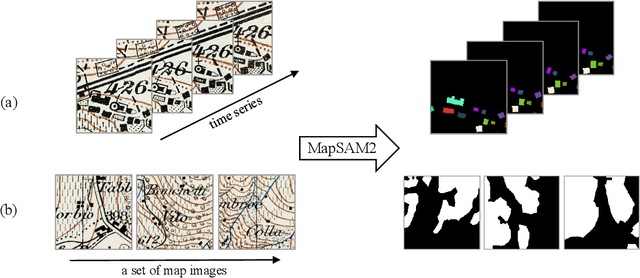
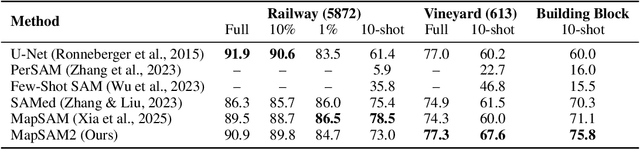
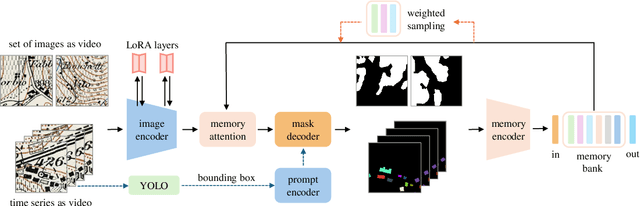
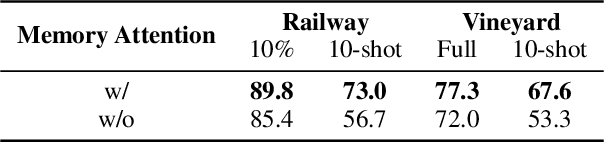
Historical maps are unique and valuable archives that document geographic features across different time periods. However, automated analysis of historical map images remains a significant challenge due to their wide stylistic variability and the scarcity of annotated training data. Constructing linked spatio-temporal datasets from historical map time series is even more time-consuming and labor-intensive, as it requires synthesizing information from multiple maps. Such datasets are essential for applications such as dating buildings, analyzing the development of road networks and settlements, studying environmental changes etc. We present MapSAM2, a unified framework for automatically segmenting both historical map images and time series. Built on a visual foundation model, MapSAM2 adapts to diverse segmentation tasks with few-shot fine-tuning. Our key innovation is to treat both historical map images and time series as videos. For images, we process a set of tiles as a video, enabling the memory attention mechanism to incorporate contextual cues from similar tiles, leading to improved geometric accuracy, particularly for areal features. For time series, we introduce the annotated Siegfried Building Time Series Dataset and, to reduce annotation costs, propose generating pseudo time series from single-year maps by simulating common temporal transformations. Experimental results show that MapSAM2 learns temporal associations effectively and can accurately segment and link buildings in time series under limited supervision or using pseudo videos. We will release both our dataset and code to support future research.
Can LLMs Generate High-Quality Test Cases for Algorithm Problems? TestCase-Eval: A Systematic Evaluation of Fault Coverage and Exposure
Jun 13, 2025We introduce TestCase-Eval, a new benchmark for systematic evaluation of LLMs in test-case generation. TestCase-Eval includes 500 algorithm problems and 100,000 human-crafted solutions from the Codeforces platform. It focuses on two pivotal tasks: (1) Fault Coverage, which measures how well LLM-generated test sets probe diverse input scenarios and cover a wide range of potential failure modes. (2) Fault Exposure, which evaluates whether LLMs can craft a tailored test input that reveals a specific incorrect code implementation. We provide a comprehensive assessment of 19 state-of-the-art open-source and proprietary LLMs on TestCase-Eval, offering insights into their strengths and limitations in generating effective test cases for algorithm problems.
Video Quality Assessment for Online Processing: From Spatial to Temporal Sampling
Jan 13, 2025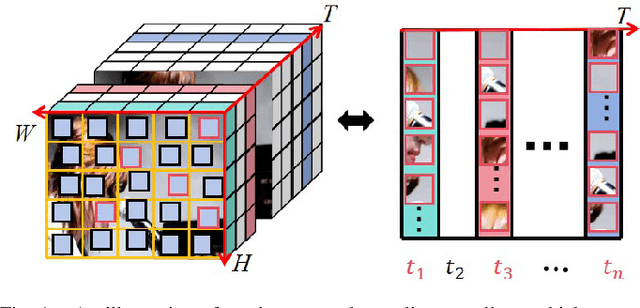
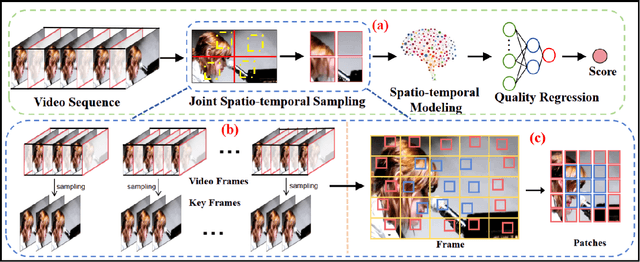
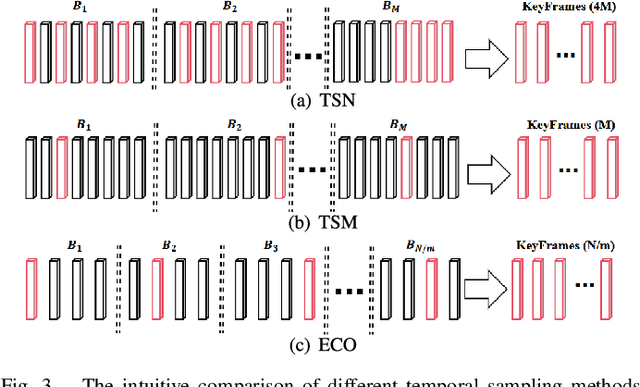
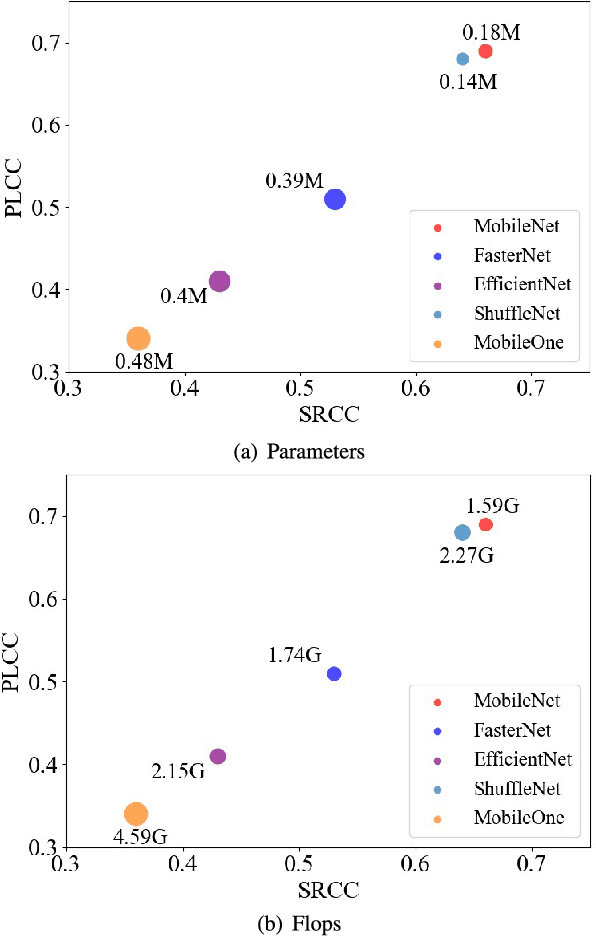
With the rapid development of multimedia processing and deep learning technologies, especially in the field of video understanding, video quality assessment (VQA) has achieved significant progress. Although researchers have moved from designing efficient video quality mapping models to various research directions, in-depth exploration of the effectiveness-efficiency trade-offs of spatio-temporal modeling in VQA models is still less sufficient. Considering the fact that videos have highly redundant information, this paper investigates this problem from the perspective of joint spatial and temporal sampling, aiming to seek the answer to how little information we should keep at least when feeding videos into the VQA models while with acceptable performance sacrifice. To this end, we drastically sample the video's information from both spatial and temporal dimensions, and the heavily squeezed video is then fed into a stable VQA model. Comprehensive experiments regarding joint spatial and temporal sampling are conducted on six public video quality databases, and the results demonstrate the acceptable performance of the VQA model when throwing away most of the video information. Furthermore, with the proposed joint spatial and temporal sampling strategy, we make an initial attempt to design an online VQA model, which is instantiated by as simple as possible a spatial feature extractor, a temporal feature fusion module, and a global quality regression module. Through quantitative and qualitative experiments, we verify the feasibility of online VQA model by simplifying itself and reducing input.
Self-supervised Video Instance Segmentation Can Boost Geographic Entity Alignment in Historical Maps
Nov 26, 2024



Tracking geographic entities from historical maps, such as buildings, offers valuable insights into cultural heritage, urbanization patterns, environmental changes, and various historical research endeavors. However, linking these entities across diverse maps remains a persistent challenge for researchers. Traditionally, this has been addressed through a two-step process: detecting entities within individual maps and then associating them via a heuristic-based post-processing step. In this paper, we propose a novel approach that combines segmentation and association of geographic entities in historical maps using video instance segmentation (VIS). This method significantly streamlines geographic entity alignment and enhances automation. However, acquiring high-quality, video-format training data for VIS models is prohibitively expensive, especially for historical maps that often contain hundreds or thousands of geographic entities. To mitigate this challenge, we explore self-supervised learning (SSL) techniques to enhance VIS performance on historical maps. We evaluate the performance of VIS models under different pretraining configurations and introduce a novel method for generating synthetic videos from unlabeled historical map images for pretraining. Our proposed self-supervised VIS method substantially reduces the need for manual annotation. Experimental results demonstrate the superiority of the proposed self-supervised VIS approach, achieving a 24.9\% improvement in AP and a 0.23 increase in F1 score compared to the model trained from scratch.
MapSAM: Adapting Segment Anything Model for Automated Feature Detection in Historical Maps
Nov 11, 2024
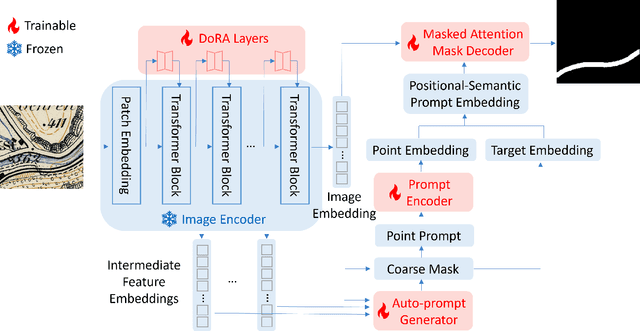
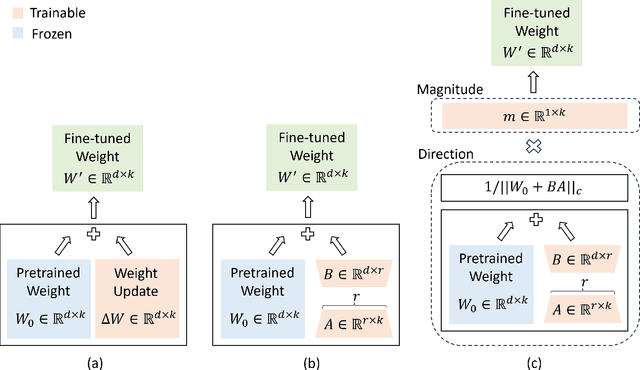

Automated feature detection in historical maps can significantly accelerate the reconstruction of the geospatial past. However, this process is often constrained by the time-consuming task of manually digitizing sufficient high-quality training data. The emergence of visual foundation models, such as the Segment Anything Model (SAM), offers a promising solution due to their remarkable generalization capabilities and rapid adaptation to new data distributions. Despite this, directly applying SAM in a zero-shot manner to historical map segmentation poses significant challenges, including poor recognition of certain geospatial features and a reliance on input prompts, which limits its ability to be fully automated. To address these challenges, we introduce MapSAM, a parameter-efficient fine-tuning strategy that adapts SAM into a prompt-free and versatile solution for various downstream historical map segmentation tasks. Specifically, we employ Weight-Decomposed Low-Rank Adaptation (DoRA) to integrate domain-specific knowledge into the image encoder. Additionally, we develop an automatic prompt generation process, eliminating the need for manual input. We further enhance the positional prompt in SAM, transforming it into a higher-level positional-semantic prompt, and modify the cross-attention mechanism in the mask decoder with masked attention for more effective feature aggregation. The proposed MapSAM framework demonstrates promising performance across two distinct historical map segmentation tasks: one focused on linear features and the other on areal features. Experimental results show that it adapts well to various features, even when fine-tuned with extremely limited data (e.g. 10 shots).
Probabilistic road classification in historical maps using synthetic data and deep learning
Oct 03, 2024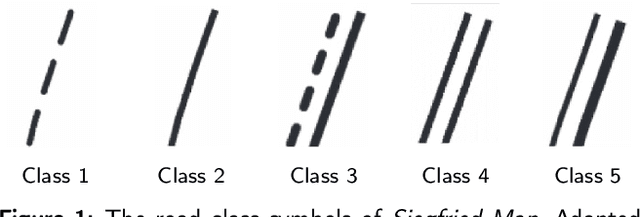

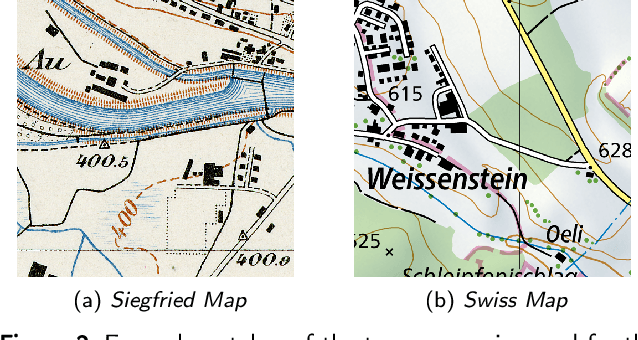

Historical maps are invaluable for analyzing long-term changes in transportation and spatial development, offering a rich source of data for evolutionary studies. However, digitizing and classifying road networks from these maps is often expensive and time-consuming, limiting their widespread use. Recent advancements in deep learning have made automatic road extraction from historical maps feasible, yet these methods typically require large amounts of labeled training data. To address this challenge, we introduce a novel framework that integrates deep learning with geoinformation, computer-based painting, and image processing methodologies. This framework enables the extraction and classification of roads from historical maps using only road geometries without needing road class labels for training. The process begins with training of a binary segmentation model to extract road geometries, followed by morphological operations, skeletonization, vectorization, and filtering algorithms. Synthetic training data is then generated by a painting function that artificially re-paints road segments using predefined symbology for road classes. Using this synthetic data, a deep ensemble is trained to generate pixel-wise probabilities for road classes to mitigate distribution shift. These predictions are then discretized along the extracted road geometries. Subsequently, further processing is employed to classify entire roads, enabling the identification of potential changes in road classes and resulting in a labeled road class dataset. Our method achieved completeness and correctness scores of over 94% and 92%, respectively, for road class 2, the most prevalent class in the two Siegfried Map sheets from Switzerland used for testing. This research offers a powerful tool for urban planning and transportation decision-making by efficiently extracting and classifying roads from historical maps.
Lesion-aware network for diabetic retinopathy diagnosis
Aug 14, 2024Deep learning brought boosts to auto diabetic retinopathy (DR) diagnosis, thus, greatly helping ophthalmologists for early disease detection, which contributes to preventing disease deterioration that may eventually lead to blindness. It has been proved that convolutional neural network (CNN)-aided lesion identifying or segmentation benefits auto DR screening. The key to fine-grained lesion tasks mainly lies in: (1) extracting features being both sensitive to tiny lesions and robust against DR-irrelevant interference, and (2) exploiting and re-using encoded information to restore lesion locations under extremely imbalanced data distribution. To this end, we propose a CNN-based DR diagnosis network with attention mechanism involved, termed lesion-aware network, to better capture lesion information from imbalanced data. Specifically, we design the lesion-aware module (LAM) to capture noise-like lesion areas across deeper layers, and the feature-preserve module (FPM) to assist shallow-to-deep feature fusion. Afterward, the proposed lesion-aware network (LANet) is constructed by embedding the LAM and FPM into the CNN decoders for DR-related information utilization. The proposed LANet is then further extended to a DR screening network by adding a classification layer. Through experiments on three public fundus datasets with pixel-level annotations, our method outperforms the mainstream methods with an area under curve of 0.967 in DR screening, and increases the overall average precision by 7.6%, 2.1%, and 1.2% in lesion segmentation on three datasets. Besides, the ablation study validates the effectiveness of the proposed sub-modules.
TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest
May 31, 2023Sequential models that encode user activity for next action prediction have become a popular design choice for building web-scale personalized recommendation systems. Traditional methods of sequential recommendation either utilize end-to-end learning on realtime user actions, or learn user representations separately in an offline batch-generated manner. This paper (1) presents Pinterest's ranking architecture for Homefeed, our personalized recommendation product and the largest engagement surface; (2) proposes TransAct, a sequential model that extracts users' short-term preferences from their realtime activities; (3) describes our hybrid approach to ranking, which combines end-to-end sequential modeling via TransAct with batch-generated user embeddings. The hybrid approach allows us to combine the advantages of responsiveness from learning directly on realtime user activity with the cost-effectiveness of batch user representations learned over a longer time period. We describe the results of ablation studies, the challenges we faced during productionization, and the outcome of an online A/B experiment, which validates the effectiveness of our hybrid ranking model. We further demonstrate the effectiveness of TransAct on other surfaces such as contextual recommendations and search. Our model has been deployed to production in Homefeed, Related Pins, Notifications, and Search at Pinterest.