 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Foundation Models Probabilistic via Singular Value Ensembles
Jan 29, 2026Foundation models have become a dominant paradigm in machine learning, achieving remarkable performance across diverse tasks through large-scale pretraining. However, these models often yield overconfident, uncalibrated predictions. The standard approach to quantifying epistemic uncertainty, training an ensemble of independent models, incurs prohibitive computational costs that scale linearly with ensemble size, making it impractical for large foundation models. We propose Singular Value Ensemble (SVE), a parameter-efficient implicit ensemble method that builds on a simple, but powerful core assumption: namely, that the singular vectors of the weight matrices constitute meaningful subspaces of the model's knowledge. Pretrained foundation models encode rich, transferable information in their weight matrices. If the singular vectors are indeed meaningful (orthogonal) "knowledge directions". To obtain a model ensemble, we modulate only how strongly each direction contributes to the output. Rather than learning entirely new parameters, we freeze the singular vectors and only train per-member singular values that rescale the contribution of each direction in that shared knowledge basis. Ensemble diversity emerges naturally as stochastic initialization and random sampling of mini-batches during joint training cause different members to converge to different combinations of the same underlying knowledge. SVE achieves uncertainty quantification comparable to explicit deep ensembles while increasing the parameter count of the base model by less than 1%, making principled uncertainty estimation accessible in resource-constrained settings. We validate SVE on NLP and vision tasks with various different backbones and show that it improves calibration while maintaining predictive accuracy.
Probabilistic road classification in historical maps using synthetic data and deep learning
Oct 03, 2024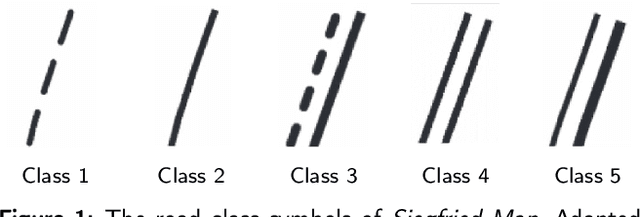

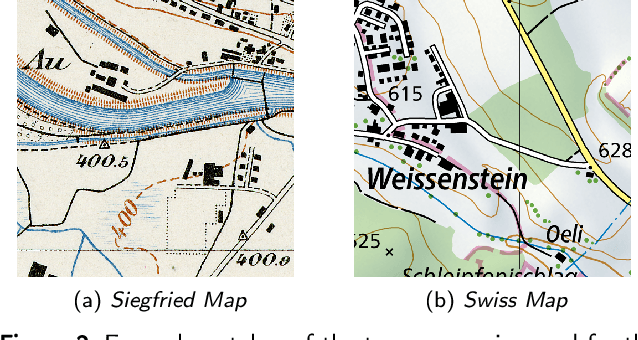

Historical maps are invaluable for analyzing long-term changes in transportation and spatial development, offering a rich source of data for evolutionary studies. However, digitizing and classifying road networks from these maps is often expensive and time-consuming, limiting their widespread use. Recent advancements in deep learning have made automatic road extraction from historical maps feasible, yet these methods typically require large amounts of labeled training data. To address this challenge, we introduce a novel framework that integrates deep learning with geoinformation, computer-based painting, and image processing methodologies. This framework enables the extraction and classification of roads from historical maps using only road geometries without needing road class labels for training. The process begins with training of a binary segmentation model to extract road geometries, followed by morphological operations, skeletonization, vectorization, and filtering algorithms. Synthetic training data is then generated by a painting function that artificially re-paints road segments using predefined symbology for road classes. Using this synthetic data, a deep ensemble is trained to generate pixel-wise probabilities for road classes to mitigate distribution shift. These predictions are then discretized along the extracted road geometries. Subsequently, further processing is employed to classify entire roads, enabling the identification of potential changes in road classes and resulting in a labeled road class dataset. Our method achieved completeness and correctness scores of over 94% and 92%, respectively, for road class 2, the most prevalent class in the two Siegfried Map sheets from Switzerland used for testing. This research offers a powerful tool for urban planning and transportation decision-making by efficiently extracting and classifying roads from historical maps.
LoRA-Ensemble: Efficient Uncertainty Modelling for Self-attention Networks
May 23, 2024Numerous crucial tasks in real-world decision-making rely on machine learning algorithms with calibrated uncertainty estimates. However, modern methods often yield overconfident and uncalibrated predictions. Various approaches involve training an ensemble of separate models to quantify the uncertainty related to the model itself, known as epistemic uncertainty. In an explicit implementation, the ensemble approach has high computational cost and high memory requirements. This particular challenge is evident in state-of-the-art neural networks such as transformers, where even a single network is already demanding in terms of compute and memory. Consequently, efforts are made to emulate the ensemble model without actually instantiating separate ensemble members, referred to as implicit ensembling. We introduce LoRA-Ensemble, a parameter-efficient deep ensemble method for self-attention networks, which is based on Low-Rank Adaptation (LoRA). Initially developed for efficient LLM fine-tuning, we extend LoRA to an implicit ensembling approach. By employing a single pre-trained self-attention network with weights shared across all members, we train member-specific low-rank matrices for the attention projections. Our method exhibits superior calibration compared to explicit ensembles and achieves similar or better accuracy across various prediction tasks and datasets.
Spatially-Aware Car-Sharing Demand Prediction
Mar 25, 2023In recent years, car-sharing services have emerged as viable alternatives to private individual mobility, promising more sustainable and resource-efficient, but still comfortable transportation. Research on short-term prediction and optimization methods has improved operations and fleet control of car-sharing services; however, long-term projections and spatial analysis are sparse in the literature. We propose to analyze the average monthly demand in a station-based car-sharing service with spatially-aware learning algorithms that offer high predictive performance as well as interpretability. In particular, we compare the spatially-implicit Random Forest model with spatially-aware methods for predicting average monthly per-station demand. The study utilizes a rich set of socio-demographic, location-based (e.g., POIs), and car-sharing-specific features as input, extracted from a large proprietary car-sharing dataset and publicly available datasets. We show that the global Random Forest model with geo-coordinates as an input feature achieves the highest predictive performance with an R-squared score of 0.87, while local methods such as Geographically Weighted Regression perform almost on par and additionally yield exciting insights into the heterogeneous spatial distributions of factors influencing car-sharing behaviour. Additionally, our study offers effective as well as highly interpretable methods for diagnosing and planning the placement of car-sharing stations.