 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Panoramic Geometry Estimation via Multi-View Foundation Models
May 27, 2026Geometry estimation from perspective images has greatly advanced, maturing to the point where off-the-shelf foundation models are able to reconstruct 3D scene structure not only from multi-view imagery, but even from a single view. A natural extension is 3D reconstruction from panoramas, with the exciting prospect of recovering a full 360-degree scene from a single panoramic image. In this work, we introduce PaGeR (Panoramic Geometry Reconstruction), a framework to lift powerful 3D foundation models designed for perspective imagery to the panorama domain. Our strategy is to start from a pre-trained transformer for 3D reconstruction and turn it into a unified high-performance model that predicts scale-invariant depth, metric depth, surface normals, and sky masks from both perspective and omnidirectional images, in a single forward pass. By keeping architectural changes to a minimum and mixing perspective and panoramic images during training, PaGeR retains the rich 3D prior of the underlying foundation model while learning to also estimate geometrically consistent 360-degree scenes from single panoramas. We extensively test our method in both indoor and outdoor environments and find that it delivers state-of-the-art performance and excellent zero-shot performance across a wide range of scenes. Code, data and models are available $\href{https://github.com/prs-eth/PaGeR}{\text{here}}$.
Stitched Value Model for Diffusion Alignment
May 19, 2026For practical use, diffusion- or flow-based generative models must be aligned with task-specific rewards, such as prompt fidelity or aesthetic preference. That alignment is challenging because the reward is defined for clean output images, but the alignment procedure requires value function estimates at noisy intermediate latents. Existing methods resort to Tweedie-style or Monte Carlo approximations, trading off estimator bias against computational cost: Tweedie estimates are efficient but biased, while Monte Carlo estimates are more accurate but require expensive rollouts. A natural alternative would be a learned value function, but it remains an open question how to effectively train a strong and general value model specifically for noisy latents. Here, we propose StitchVM, a model stitching framework that efficiently transfers reward models pretrained for clean images to the noisy latent regime. StitchVM starts from an existing, truncated pixel-space reward model and attaches a frozen diffusion backbone to it as its head. From the pixel-space model, the resulting hybrid retains a carefully pretrained, robust reward capability; from the diffusion backbone, it inherits its native ability to handle noisy latents. The stitching procedure is exceptionally lightweight, e.g., stitching and finetuning CLIP ViT-L and SD 3.5 Medium takes only 10 GPU-hours. By lifting powerful pixel-space reward models to latent space, StitchVM opens up a new style of diffusion alignment: instead of rough, yet costly per-sample approximation of the value function, the correct function for the actual, noisy latents is constructed once and then amortized over many samples and iterations. We show that this approach yields improvements across a broad range of downstream steering and post-training methods: DPS becomes $3.2\times$ faster while halving peak GPU memory, and DiffusionNFT becomes $2.3\times$ faster.
Repurposing Protein Language Models for Latent Flow-Based Fitness Optimization
Feb 02, 2026Protein fitness optimization is challenged by a vast combinatorial landscape where high-fitness variants are extremely sparse. Many current methods either underperform or require computationally expensive gradient-based sampling. We present CHASE, a framework that repurposes the evolutionary knowledge of pretrained protein language models by compressing their embeddings into a compact latent space. By training a conditional flow-matching model with classifier-free guidance, we enable the direct generation of high-fitness variants without predictor-based guidance during the ODE sampling steps. CHASE achieves state-of-the-art performance on AAV and GFP protein design benchmarks. Finally, we show that bootstrapping with synthetic data can further enhance performance in data-constrained settings.
A Variational Perspective on Generative Protein Fitness Optimization
Jan 31, 2025



The goal of protein fitness optimization is to discover new protein variants with enhanced fitness for a given use. The vast search space and the sparsely populated fitness landscape, along with the discrete nature of protein sequences, pose significant challenges when trying to determine the gradient towards configurations with higher fitness. We introduce Variational Latent Generative Protein Optimization (VLGPO), a variational perspective on fitness optimization. Our method embeds protein sequences in a continuous latent space to enable efficient sampling from the fitness distribution and combines a (learned) flow matching prior over sequence mutations with a fitness predictor to guide optimization towards sequences with high fitness. VLGPO achieves state-of-the-art results on two different protein benchmarks of varying complexity. Moreover, the variational design with explicit prior and likelihood functions offers a flexible plug-and-play framework that can be easily customized to suit various protein design tasks.
Video Depth without Video Models
Nov 28, 2024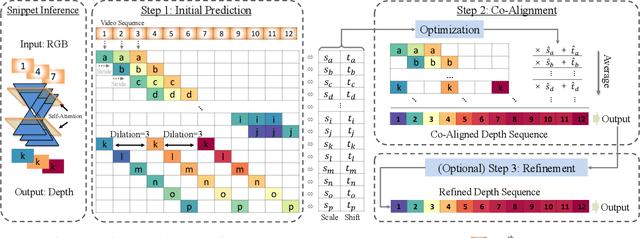
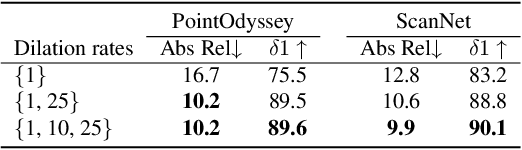
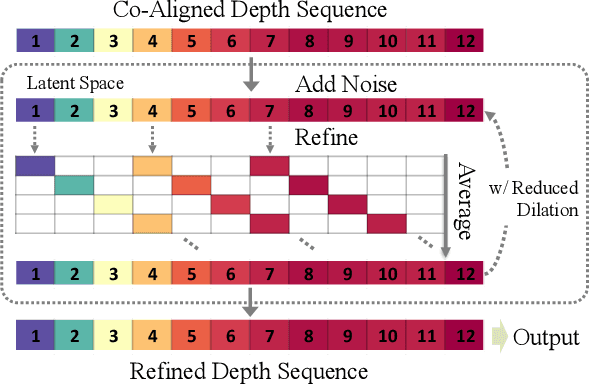
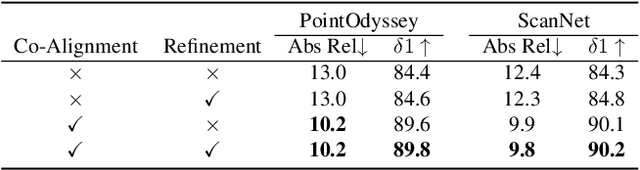
Video depth estimation lifts monocular video clips to 3D by inferring dense depth at every frame. Recent advances in single-image depth estimation, brought about by the rise of large foundation models and the use of synthetic training data, have fueled a renewed interest in video depth. However, naively applying a single-image depth estimator to every frame of a video disregards temporal continuity, which not only leads to flickering but may also break when camera motion causes sudden changes in depth range. An obvious and principled solution would be to build on top of video foundation models, but these come with their own limitations; including expensive training and inference, imperfect 3D consistency, and stitching routines for the fixed-length (short) outputs. We take a step back and demonstrate how to turn a single-image latent diffusion model (LDM) into a state-of-the-art video depth estimator. Our model, which we call RollingDepth, has two main ingredients: (i) a multi-frame depth estimator that is derived from a single-image LDM and maps very short video snippets (typically frame triplets) to depth snippets. (ii) a robust, optimization-based registration algorithm that optimally assembles depth snippets sampled at various different frame rates back into a consistent video. RollingDepth is able to efficiently handle long videos with hundreds of frames and delivers more accurate depth videos than both dedicated video depth estimators and high-performing single-frame models. Project page: rollingdepth.github.io.
FlowSDF: Flow Matching for Medical Image Segmentation Using Distance Transforms
May 28, 2024



Medical image segmentation is a crucial task that relies on the ability to accurately identify and isolate regions of interest in medical images. Thereby, generative approaches allow to capture the statistical properties of segmentation masks that are dependent on the respective structures. In this work we propose FlowSDF, an image-guided conditional flow matching framework to represent the signed distance function (SDF) leading to an implicit distribution of segmentation masks. The advantage of leveraging the SDF is a more natural distortion when compared to that of binary masks. By learning a vector field that is directly related to the probability path of a conditional distribution of SDFs, we can accurately sample from the distribution of segmentation masks, allowing for the evaluation of statistical quantities. Thus, this probabilistic representation allows for the generation of uncertainty maps represented by the variance, which can aid in further analysis and enhance the predictive robustness. We qualitatively and quantitatively illustrate competitive performance of the proposed method on a public nuclei and gland segmentation data set, highlighting its utility in medical image segmentation applications.
LoRA-Ensemble: Efficient Uncertainty Modelling for Self-attention Networks
May 23, 2024Numerous crucial tasks in real-world decision-making rely on machine learning algorithms with calibrated uncertainty estimates. However, modern methods often yield overconfident and uncalibrated predictions. Various approaches involve training an ensemble of separate models to quantify the uncertainty related to the model itself, known as epistemic uncertainty. In an explicit implementation, the ensemble approach has high computational cost and high memory requirements. This particular challenge is evident in state-of-the-art neural networks such as transformers, where even a single network is already demanding in terms of compute and memory. Consequently, efforts are made to emulate the ensemble model without actually instantiating separate ensemble members, referred to as implicit ensembling. We introduce LoRA-Ensemble, a parameter-efficient deep ensemble method for self-attention networks, which is based on Low-Rank Adaptation (LoRA). Initially developed for efficient LLM fine-tuning, we extend LoRA to an implicit ensembling approach. By employing a single pre-trained self-attention network with weights shared across all members, we train member-specific low-rank matrices for the attention projections. Our method exhibits superior calibration compared to explicit ensembles and achieves similar or better accuracy across various prediction tasks and datasets.
MULDE: Multiscale Log-Density Estimation via Denoising Score Matching for Video Anomaly Detection
Mar 21, 2024



We propose a novel approach to video anomaly detection: we treat feature vectors extracted from videos as realizations of a random variable with a fixed distribution and model this distribution with a neural network. This lets us estimate the likelihood of test videos and detect video anomalies by thresholding the likelihood estimates. We train our video anomaly detector using a modification of denoising score matching, a method that injects training data with noise to facilitate modeling its distribution. To eliminate hyperparameter selection, we model the distribution of noisy video features across a range of noise levels and introduce a regularizer that tends to align the models for different levels of noise. At test time, we combine anomaly indications at multiple noise scales with a Gaussian mixture model. Running our video anomaly detector induces minimal delays as inference requires merely extracting the features and forward-propagating them through a shallow neural network and a Gaussian mixture model. Our experiments on five popular video anomaly detection benchmarks demonstrate state-of-the-art performance, both in the object-centric and in the frame-centric setup.
Majorization-Minimization for sparse SVMs
Aug 31, 2023Several decades ago, Support Vector Machines (SVMs) were introduced for performing binary classification tasks, under a supervised framework. Nowadays, they often outperform other supervised methods and remain one of the most popular approaches in the machine learning arena. In this work, we investigate the training of SVMs through a smooth sparse-promoting-regularized squared hinge loss minimization. This choice paves the way to the application of quick training methods built on majorization-minimization approaches, benefiting from the Lipschitz differentiabililty of the loss function. Moreover, the proposed approach allows us to handle sparsity-preserving regularizers promoting the selection of the most significant features, so enhancing the performance. Numerical tests and comparisons conducted on three different datasets demonstrate the good performance of the proposed methodology in terms of qualitative metrics (accuracy, precision, recall, and F 1 score) as well as computational cost.
Score-Based Generative Models for Medical Image Segmentation using Signed Distance Functions
Mar 10, 2023



Medical image segmentation is a crucial task that relies on the ability to accurately identify and isolate regions of interest in images. Thereby, generative approaches allow to capture the statistical properties of segmentation masks that are dependent on the respective medical images. In this work we propose a conditional score-based generative modeling framework that leverages the signed distance function to represent an implicit and smoother distribution of segmentation masks. The score function of the conditional distribution of segmentation masks is learned in a conditional denoising process, which can be effectively used to generate accurate segmentation masks. Moreover, uncertainty maps can be generated, which can aid in further analysis and thus enhance the predictive robustness. We qualitatively and quantitatively illustrate competitive performance of the proposed method on a public nuclei and gland segmentation data set, highlighting its potential utility in medical image segmentation applications.