 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMajorization-Minimization for sparse SVMs
Aug 31, 2023Several decades ago, Support Vector Machines (SVMs) were introduced for performing binary classification tasks, under a supervised framework. Nowadays, they often outperform other supervised methods and remain one of the most popular approaches in the machine learning arena. In this work, we investigate the training of SVMs through a smooth sparse-promoting-regularized squared hinge loss minimization. This choice paves the way to the application of quick training methods built on majorization-minimization approaches, benefiting from the Lipschitz differentiabililty of the loss function. Moreover, the proposed approach allows us to handle sparsity-preserving regularizers promoting the selection of the most significant features, so enhancing the performance. Numerical tests and comparisons conducted on three different datasets demonstrate the good performance of the proposed methodology in terms of qualitative metrics (accuracy, precision, recall, and F 1 score) as well as computational cost.
Uncovering the Background-Induced bias in RGB based 6-DoF Object Pose Estimation
Apr 17, 2023In recent years, there has been a growing trend of using data-driven methods in industrial settings. These kinds of methods often process video images or parts, therefore the integrity of such images is crucial. Sometimes datasets, e.g. consisting of images, can be sophisticated for various reasons. It becomes critical to understand how the manipulation of video and images can impact the effectiveness of a machine learning method. Our case study aims precisely to analyze the Linemod dataset, considered the state of the art in 6D pose estimation context. That dataset presents images accompanied by ArUco markers; it is evident that such markers will not be available in real-world contexts. We analyze how the presence of the markers affects the pose estimation accuracy, and how this bias may be mitigated through data augmentation and other methods. Our work aims to show how the presence of these markers goes to modify, in the testing phase, the effectiveness of the deep learning method used. In particular, we will demonstrate, through the tool of saliency maps, how the focus of the neural network is captured in part by these ArUco markers. Finally, a new dataset, obtained by applying geometric tools to Linemod, will be proposed in order to demonstrate our hypothesis and uncovering the bias. Our results demonstrate the potential for bias in 6DOF pose estimation networks, and suggest methods for reducing this bias when training with markers.
Model-Based Underwater 6D Pose Estimation from RGB
Feb 14, 2023



Object pose estimation underwater allows an autonomous system to perform tracking and intervention tasks. Nonetheless, underwater target pose estimation is remarkably challenging due to, among many factors, limited visibility, light scattering, cluttered environments, and constantly varying water conditions. An approach is to employ sonar or laser sensing to acquire 3D data, but besides being costly, the resulting data is normally noisy. For this reason, the community has focused on extracting pose estimates from RGB input. However, the literature is scarce and exhibits low detection accuracy. In this work, we propose an approach consisting of a 2D object detection and a 6D pose estimation that reliably obtains object poses in different underwater scenarios. To test our pipeline, we collect and make available a dataset of 4 objects in 10 different real scenes with annotations for object detection and pose estimation. We test our proposal in real and synthetic settings and compare its performance with similar end-to-end methodologies for 6D object pose estimation. Our dataset contains some challenging objects with symmetrical shapes and poor texture. Regardless of such object characteristics, our proposed method outperforms stat-of-the-art pose accuracy by ~8%. We finally demonstrate the reliability of our pose estimation pipeline by doing experiments with an underwater manipulation in a reaching task.
Explainable bilevel optimization: an application to the Helsinki deblur challenge
Oct 18, 2022



In this paper we present a bilevel optimization scheme for the solution of a general image deblurring problem, in which a parametric variational-like approach is encapsulated within a machine learning scheme to provide a high quality reconstructed image with automatically learned parameters. The ingredients of the variational lower level and the machine learning upper one are specifically chosen for the Helsinki Deblur Challenge 2021, in which sequences of letters are asked to be recovered from out-of-focus photographs with increasing levels of blur. Our proposed procedure for the reconstructed image consists in a fixed number of FISTA iterations applied to the minimization of an edge preserving and binarization enforcing regularized least-squares functional. The parameters defining the variational model and the optimization steps, which, unlike most deep learning approaches, all have a precise and interpretable meaning, are learned via either a similarity index or a support vector machine strategy. Numerical experiments on the test images provided by the challenge authors show significant gains with respect to a standard variational approach and performances comparable with those of some of the proposed deep learning based algorithms which require the optimization of millions of parameters.
CERBERUS: Simple and Effective All-In-One Automotive Perception Model with Multi Task Learning
Oct 03, 2022

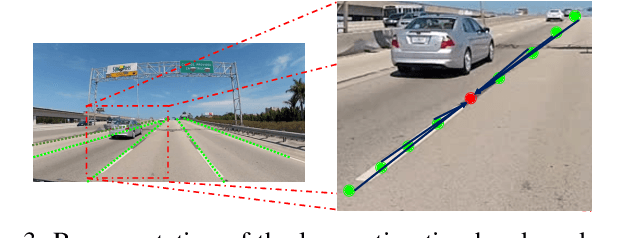

Perceiving the surrounding environment is essential for enabling autonomous or assisted driving functionalities. Common tasks in this domain include detecting road users, as well as determining lane boundaries and classifying driving conditions. Over the last few years, a large variety of powerful Deep Learning models have been proposed to address individual tasks of camera-based automotive perception with astonishing performances. However, the limited capabilities of in-vehicle embedded computing platforms cannot cope with the computational effort required to run a heavy model for each individual task. In this work, we present CERBERUS (CEnteR Based End-to-end peRception Using a Single model), a lightweight model that leverages a multitask-learning approach to enable the execution of multiple perception tasks at the cost of a single inference. The code will be made publicly available at https://github.com/cscribano/CERBERUS
DCT-Former: Efficient Self-Attention with Discrete Cosine Transform
Mar 03, 2022
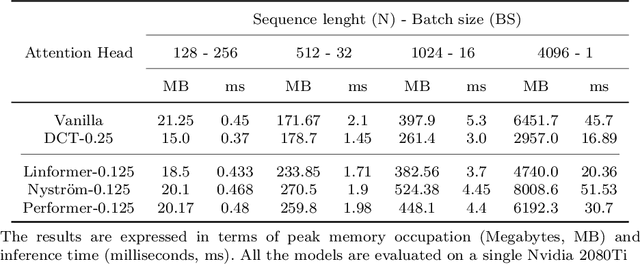
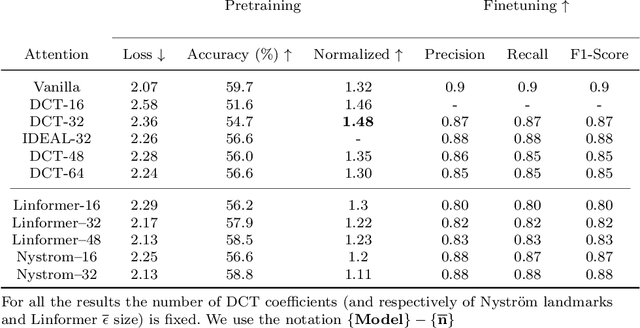
Since their introduction the Trasformer architectures emerged as the dominating architectures for both natural language processing and, more recently, computer vision applications. An intrinsic limitation of this family of "fully-attentive" architectures arises from the computation of the dot-product attention, which grows both in memory consumption and number of operations as $O(n^2)$ where $n$ stands for the input sequence length, thus limiting the applications that require modeling very long sequences. Several approaches have been proposed so far in the literature to mitigate this issue, with varying degrees of success. Our idea takes inspiration from the world of lossy data compression (such as the JPEG algorithm) to derive an approximation of the attention module by leveraging the properties of the Discrete Cosine Transform. An extensive section of experiments shows that our method takes up less memory for the same performance, while also drastically reducing inference time. This makes it particularly suitable in real-time contexts on embedded platforms. Moreover, we assume that the results of our research might serve as a starting point for a broader family of deep neural models with reduced memory footprint. The implementation will be made publicly available at https://github.com/cscribano/DCT-Former-Public
All You Can Embed: Natural Language based Vehicle Retrieval with Spatio-Temporal Transformers
Jun 18, 2021
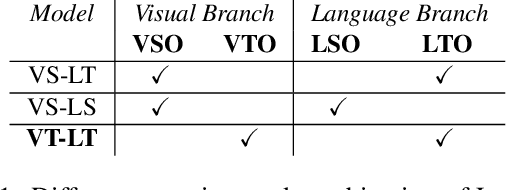
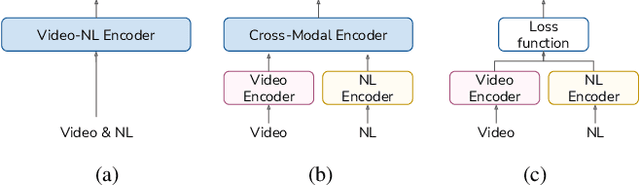
Combining Natural Language with Vision represents a unique and interesting challenge in the domain of Artificial Intelligence. The AI City Challenge Track 5 for Natural Language-Based Vehicle Retrieval focuses on the problem of combining visual and textual information, applied to a smart-city use case. In this paper, we present All You Can Embed (AYCE), a modular solution to correlate single-vehicle tracking sequences with natural language. The main building blocks of the proposed architecture are (i) BERT to provide an embedding of the textual descriptions, (ii) a convolutional backbone along with a Transformer model to embed the visual information. For the training of the retrieval model, a variation of the Triplet Margin Loss is proposed to learn a distance measure between the visual and language embeddings. The code is publicly available at https://github.com/cscribano/AYCE_2021.
Mise en abyme with artificial intelligence: how to predict the accuracy of NN, applied to hyper-parameter tuning
Jun 28, 2019
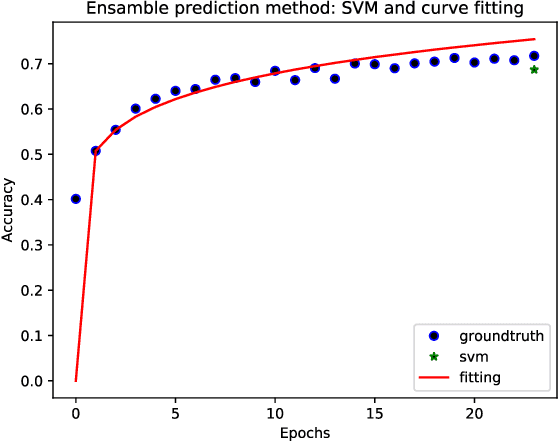
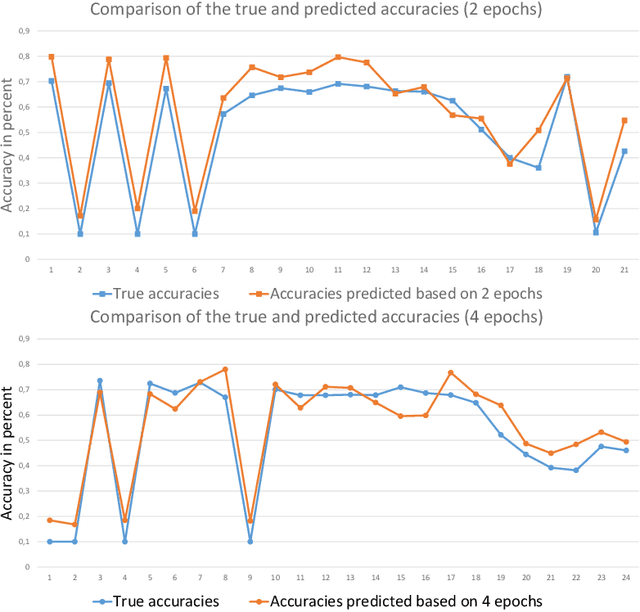
In the context of deep learning, the costliest phase from a computational point of view is the full training of the learning algorithm. However, this process is to be used a significant number of times during the design of a new artificial neural network, leading therefore to extremely expensive operations. Here, we propose a low-cost strategy to predict the accuracy of the algorithm, based only on its initial behaviour. To do so, we train the network of interest up to convergence several times, modifying its characteristics at each training. The initial and final accuracies observed during this beforehand process are stored in a database. We then make use of both curve fitting and Support Vector Machines techniques, the latter being trained on the created database, to predict the accuracy of the network, given its accuracy on the primary iterations of its learning. This approach can be of particular interest when the space of the characteristics of the network is notably large or when its full training is highly time-consuming. The results we obtained are promising and encouraged us to apply this strategy to a topical issue: hyper-parameter optimisation (HO). In particular, we focused on the HO of a convolutional neural network for the classification of the databases MNIST and CIFAR-10. By using our method of prediction, and an algorithm implemented by us for a probabilistic exploration of the hyper-parameter space, we were able to find the hyper-parameter settings corresponding to the optimal accuracies already known in literature, at a quite low-cost.
* The research leading to these results has received funding from the European Union's Horizon 2020 Programme under the CLASS Project (https://class-project.eu/), grant agreement n 780622