 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-range UAV Thermal Geo-localization with Satellite Imagery
Jun 06, 2023Onboard sensors, such as cameras and thermal sensors, have emerged as effective alternatives to Global Positioning System (GPS) for geo-localization in Unmanned Aerial Vehicle (UAV) navigation. Since GPS can suffer from signal loss and spoofing problems, researchers have explored camera-based techniques such as Visual Geo-localization (VG) using satellite imagery. Additionally, thermal geo-localization (TG) has become crucial for long-range UAV flights in low-illumination environments. This paper proposes a novel thermal geo-localization framework using satellite imagery, which includes multiple domain adaptation methods to address the limited availability of paired thermal and satellite images. The experimental results demonstrate the effectiveness of the proposed approach in achieving reliable thermal geo-localization performance, even in thermal images with indistinct self-similar features. We evaluate our approach on real data collected onboard a UAV. We also release the code and \textit{Boson-nighttime}, a dataset of paired satellite-thermal and unpaired satellite images for thermal geo-localization with satellite imagery. To the best of our knowledge, this work is the first to propose a thermal geo-localization method using satellite imagery in long-range flights.
Model-Based Underwater 6D Pose Estimation from RGB
Feb 14, 2023



Object pose estimation underwater allows an autonomous system to perform tracking and intervention tasks. Nonetheless, underwater target pose estimation is remarkably challenging due to, among many factors, limited visibility, light scattering, cluttered environments, and constantly varying water conditions. An approach is to employ sonar or laser sensing to acquire 3D data, but besides being costly, the resulting data is normally noisy. For this reason, the community has focused on extracting pose estimates from RGB input. However, the literature is scarce and exhibits low detection accuracy. In this work, we propose an approach consisting of a 2D object detection and a 6D pose estimation that reliably obtains object poses in different underwater scenarios. To test our pipeline, we collect and make available a dataset of 4 objects in 10 different real scenes with annotations for object detection and pose estimation. We test our proposal in real and synthetic settings and compare its performance with similar end-to-end methodologies for 6D object pose estimation. Our dataset contains some challenging objects with symmetrical shapes and poor texture. Regardless of such object characteristics, our proposed method outperforms stat-of-the-art pose accuracy by ~8%. We finally demonstrate the reliability of our pose estimation pipeline by doing experiments with an underwater manipulation in a reaching task.
Underwater Object Classification and Detection: first results and open challenges
Jan 04, 2022

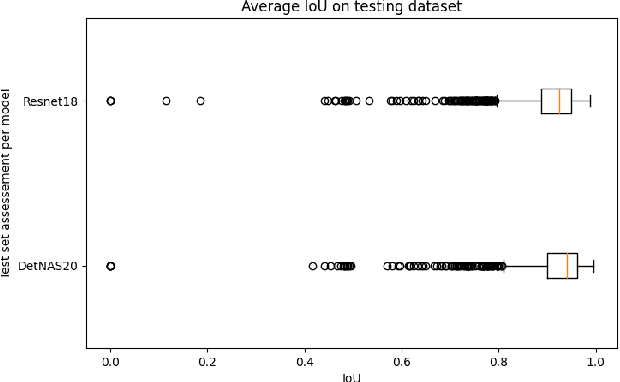
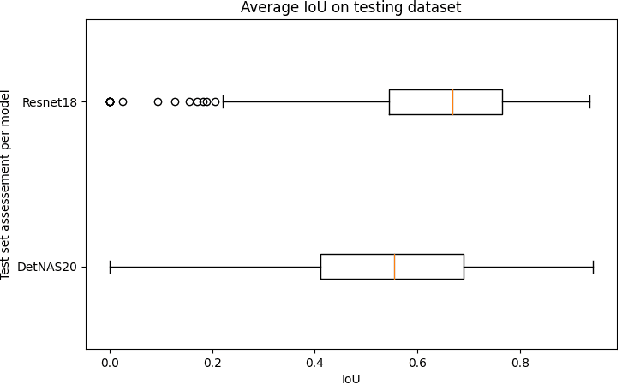
This work reviews the problem of object detection in underwater environments. We analyse and quantify the shortcomings of conventional state-of-the-art (SOTA) algorithms in the computer vision community when applied to this challenging environment, as well as providing insights and general guidelines for future research efforts. First, we assessed if pretraining with the conventional ImageNet is beneficial when the object detector needs to be applied to environments that may be characterised by a different feature distribution. We then investigate whether two-stage detectors yields to better performance with respect to single-stage detectors, in terms of accuracy, intersection of union (IoU), floating operation per second (FLOPS), and inference time. Finally, we assessed the generalisation capability of each model to a lower quality dataset to simulate performance on a real scenario, in which harsher conditions ought to be expected. Our experimental results provide evidence that underwater object detection requires searching for "ad-hoc" architectures than merely training SOTA architectures on new data, and that pretraining is not beneficial.
Improving automated multiple sclerosis lesion segmentation with a cascaded 3D convolutional neural network approach
Feb 16, 2017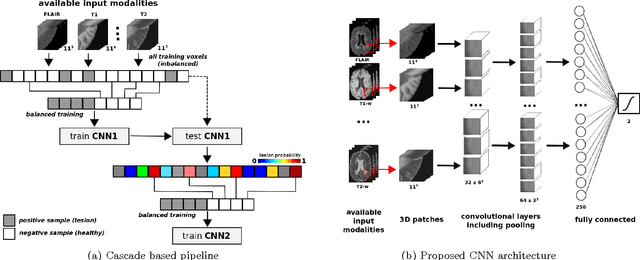

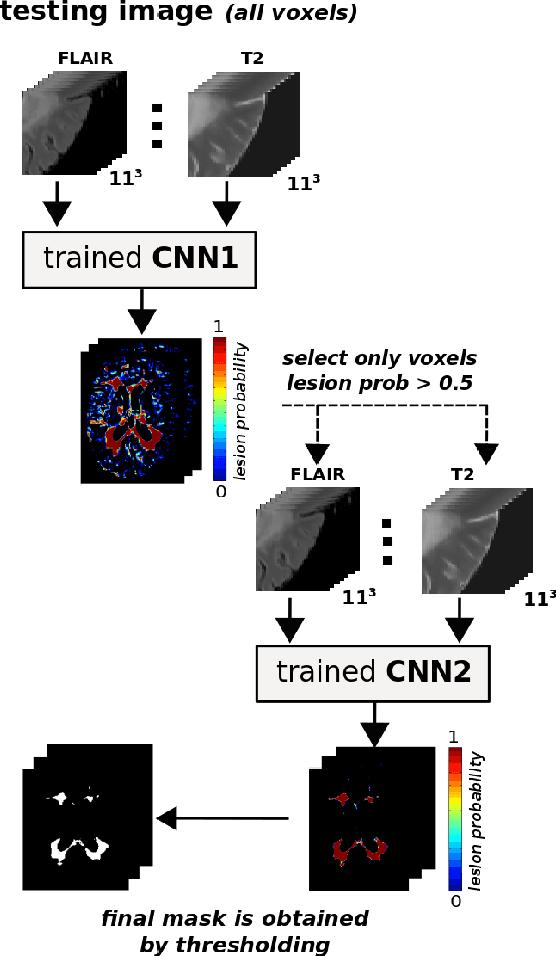
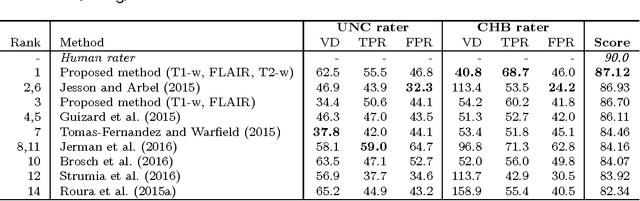
In this paper, we present a novel automated method for White Matter (WM) lesion segmentation of Multiple Sclerosis (MS) patient images. Our approach is based on a cascade of two 3D patch-wise convolutional neural networks (CNN). The first network is trained to be more sensitive revealing possible candidate lesion voxels while the second network is trained to reduce the number of misclassified voxels coming from the first network. This cascaded CNN architecture tends to learn well from small sets of training data, which can be very interesting in practice, given the difficulty to obtain manual label annotations and the large amount of available unlabeled Magnetic Resonance Imaging (MRI) data. We evaluate the accuracy of the proposed method on the public MS lesion segmentation challenge MICCAI2008 dataset, comparing it with respect to other state-of-the-art MS lesion segmentation tools. Furthermore, the proposed method is also evaluated on two private MS clinical datasets, where the performance of our method is also compared with different recent public available state-of-the-art MS lesion segmentation methods. At the time of writing this paper, our method is the best ranked approach on the MICCAI2008 challenge, outperforming the rest of 60 participant methods when using all the available input modalities (T1-w, T2-w and FLAIR), while still in the top-rank (3rd position) when using only T1-w and FLAIR modalities. On clinical MS data, our approach exhibits a significant increase in the accuracy segmenting of WM lesions when compared with the rest of evaluated methods, highly correlating ($r \ge 0.97$) also with the expected lesion volume.