 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability Bounds for the Unfolded Forward-Backward Algorithm
Dec 23, 2024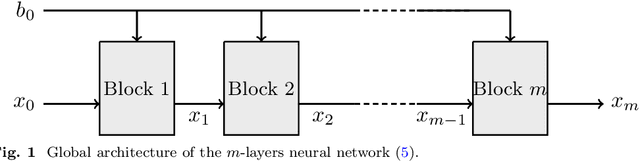
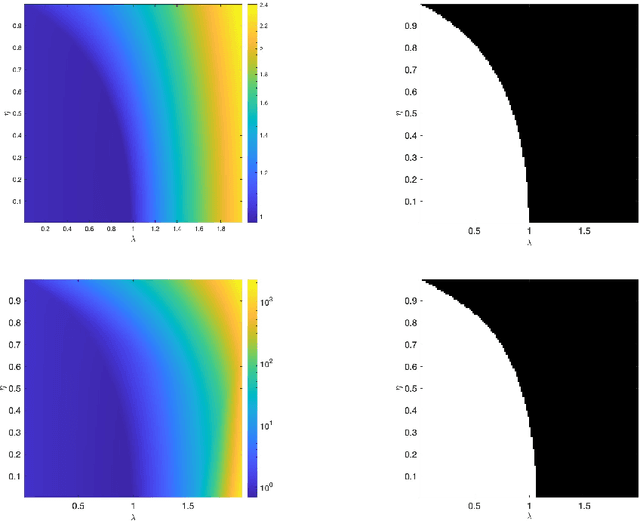
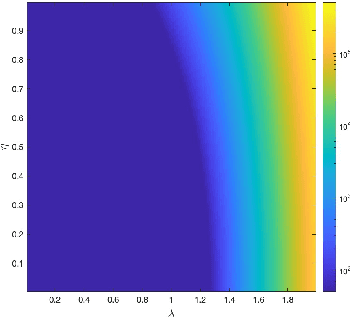
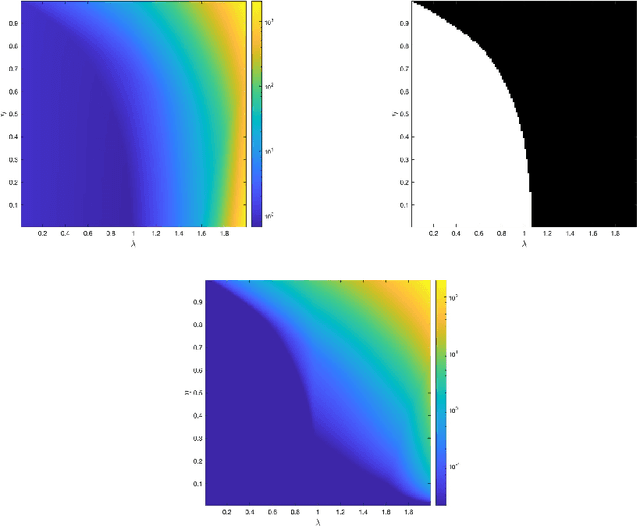
We consider a neural network architecture designed to solve inverse problems where the degradation operator is linear and known. This architecture is constructed by unrolling a forward-backward algorithm derived from the minimization of an objective function that combines a data-fidelity term, a Tikhonov-type regularization term, and a potentially nonsmooth convex penalty. The robustness of this inversion method to input perturbations is analyzed theoretically. Ensuring robustness complies with the principles of inverse problem theory, as it ensures both the continuity of the inversion method and the resilience to small noise - a critical property given the known vulnerability of deep neural networks to adversarial perturbations. A key novelty of our work lies in examining the robustness of the proposed network to perturbations in its bias, which represents the observed data in the inverse problem. Additionally, we provide numerical illustrations of the analytical Lipschitz bounds derived in our analysis.
A Novel Variational Approach for Multiphoton Microscopy Image Restoration: from PSF Estimation to 3D Deconvolution
Nov 30, 2023In multi-photon microscopy (MPM), a recent in-vivo fluorescence microscopy system, the task of image restoration can be decomposed into two interlinked inverse problems: firstly, the characterization of the Point Spread Function (PSF) and subsequently, the deconvolution (i.e., deblurring) to remove the PSF effect, and reduce noise. The acquired MPM image quality is critically affected by PSF blurring and intense noise. The PSF in MPM is highly spread in 3D and is not well characterized, presenting high variability with respect to the observed objects. This makes the restoration of MPM images challenging. Common PSF estimation methods in fluorescence microscopy, including MPM, involve capturing images of sub-resolution beads, followed by quantifying the resulting ellipsoidal 3D spot. In this work, we revisit this approach, coping with its inherent limitations in terms of accuracy and practicality. We estimate the PSF from the observation of relatively large beads (approximately 1$\mu$m in diameter). This goes through the formulation and resolution of an original non-convex minimization problem, for which we propose a proximal alternating method along with convergence guarantees. Following the PSF estimation step, we then introduce an innovative strategy to deal with the high level multiplicative noise degrading the acquisitions. We rely on a heteroscedastic noise model for which we estimate the parameters. We then solve a constrained optimization problem to restore the image, accounting for the estimated PSF and noise, while allowing a minimal hyper-parameter tuning. Theoretical guarantees are given for the restoration algorithm. These algorithmic contributions lead to an end-to-end pipeline for 3D image restoration in MPM, that we share as a publicly available Python software. We demonstrate its effectiveness through several experiments on both simulated and real data.
Deep State-Space Model for Predicting Cryptocurrency Price
Nov 21, 2023



Our work presents two fundamental contributions. On the application side, we tackle the challenging problem of predicting day-ahead crypto-currency prices. On the methodological side, a new dynamical modeling approach is proposed. Our approach keeps the probabilistic formulation of the state-space model, which provides uncertainty quantification on the estimates, and the function approximation ability of deep neural networks. We call the proposed approach the deep state-space model. The experiments are carried out on established cryptocurrencies (obtained from Yahoo Finance). The goal of the work has been to predict the price for the next day. Benchmarking has been done with both state-of-the-art and classical dynamical modeling techniques. Results show that the proposed approach yields the best overall results in terms of accuracy.
Adaptive importance sampling for heavy-tailed distributions via $α$-divergence minimization
Oct 25, 2023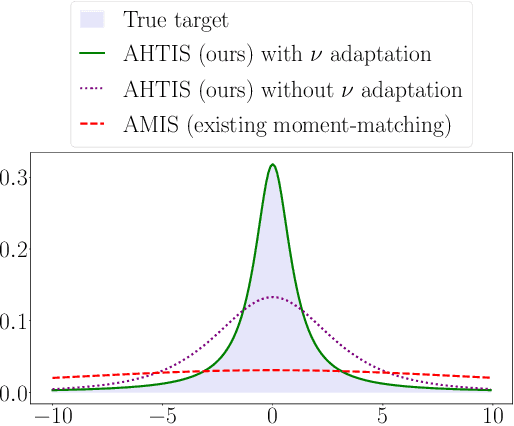
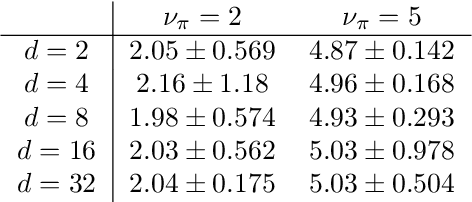
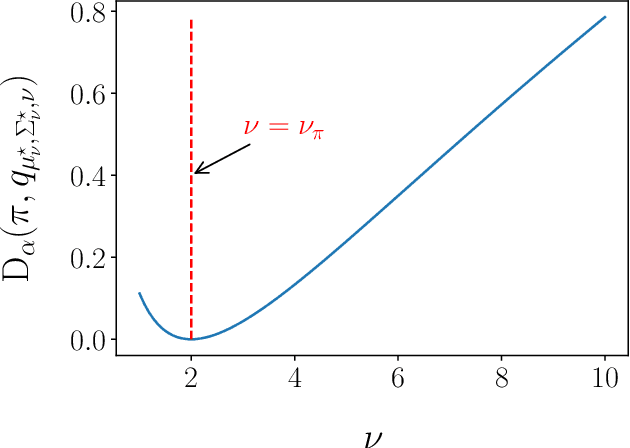
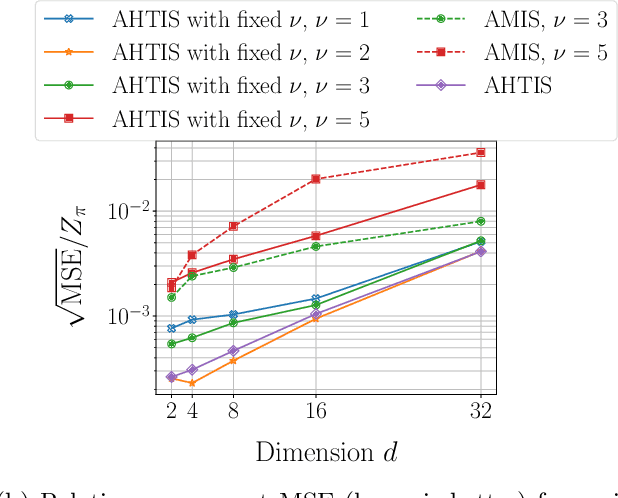
Adaptive importance sampling (AIS) algorithms are widely used to approximate expectations with respect to complicated target probability distributions. When the target has heavy tails, existing AIS algorithms can provide inconsistent estimators or exhibit slow convergence, as they often neglect the target's tail behaviour. To avoid this pitfall, we propose an AIS algorithm that approximates the target by Student-t proposal distributions. We adapt location and scale parameters by matching the escort moments - which are defined even for heavy-tailed distributions - of the target and the proposal. These updates minimize the $\alpha$-divergence between the target and the proposal, thereby connecting with variational inference. We then show that the $\alpha$-divergence can be approximated by a generalized notion of effective sample size and leverage this new perspective to adapt the tail parameter with Bayesian optimization. We demonstrate the efficacy of our approach through applications to synthetic targets and a Bayesian Student-t regression task on a real example with clinical trial data.
Aggregated f-average Neural Network for Interpretable Ensembling
Oct 09, 2023



Ensemble learning leverages multiple models (i.e., weak learners) on a common machine learning task to enhance prediction performance. Basic ensembling approaches average the weak learners outputs, while more sophisticated ones stack a machine learning model in between the weak learners outputs and the final prediction. This work fuses both aforementioned frameworks. We introduce an aggregated f-average (AFA) shallow neural network which models and combines different types of averages to perform an optimal aggregation of the weak learners predictions. We emphasise its interpretable architecture and simple training strategy, and illustrate its good performance on the problem of few-shot class incremental learning.
Majorization-Minimization for sparse SVMs
Aug 31, 2023Several decades ago, Support Vector Machines (SVMs) were introduced for performing binary classification tasks, under a supervised framework. Nowadays, they often outperform other supervised methods and remain one of the most popular approaches in the machine learning arena. In this work, we investigate the training of SVMs through a smooth sparse-promoting-regularized squared hinge loss minimization. This choice paves the way to the application of quick training methods built on majorization-minimization approaches, benefiting from the Lipschitz differentiabililty of the loss function. Moreover, the proposed approach allows us to handle sparsity-preserving regularizers promoting the selection of the most significant features, so enhancing the performance. Numerical tests and comparisons conducted on three different datasets demonstrate the good performance of the proposed methodology in terms of qualitative metrics (accuracy, precision, recall, and F 1 score) as well as computational cost.
Sparse Graphical Linear Dynamical Systems
Jul 06, 2023



Time-series datasets are central in numerous fields of science and engineering, such as biomedicine, Earth observation, and network analysis. Extensive research exists on state-space models (SSMs), which are powerful mathematical tools that allow for probabilistic and interpretable learning on time series. Estimating the model parameters in SSMs is arguably one of the most complicated tasks, and the inclusion of prior knowledge is known to both ease the interpretation but also to complicate the inferential tasks. Very recent works have attempted to incorporate a graphical perspective on some of those model parameters, but they present notable limitations that this work addresses. More generally, existing graphical modeling tools are designed to incorporate either static information, focusing on statistical dependencies among independent random variables (e.g., graphical Lasso approach), or dynamic information, emphasizing causal relationships among time series samples (e.g., graphical Granger approaches). However, there are no joint approaches combining static and dynamic graphical modeling within the context of SSMs. This work proposes a novel approach to fill this gap by introducing a joint graphical modeling framework that bridges the static graphical Lasso model and a causal-based graphical approach for the linear-Gaussian SSM. We present DGLASSO (Dynamic Graphical Lasso), a new inference method within this framework that implements an efficient block alternating majorization-minimization algorithm. The algorithm's convergence is established by departing from modern tools from nonlinear analysis. Experimental validation on synthetic and real weather variability data showcases the effectiveness of the proposed model and inference algorithm.
Démélange, déconvolution et débruitage conjoints d'un modèle convolutif parcimonieux avec dérive instrumentale, par pénalisation de rapports de normes ou quasi-normes lissées (PENDANTSS)
Jul 04, 2023

Denoising, detrending, deconvolution: usual restoration tasks, traditionally decoupled. Coupled formulations entail complex ill-posed inverse problems. We propose PENDANTSS for joint trend removal and blind deconvolution of sparse peak-like signals. It blends a parsimonious prior with the hypothesis that smooth trend and noise can somewhat be separated by low-pass filtering. We combine the generalized pseudo-norm ratio SOOT/SPOQ sparse penalties $\ell_p/\ell_q$ with the BEADS ternary assisted source separation algorithm. This results in a both convergent and efficient tool, with a novel Trust-Region block alternating variable metric forward-backward approach. It outperforms comparable methods, when applied to typically peaked analytical chemistry signals. Reproducible code is provided: https://github.com/paulzhengfr/PENDANTSS.
PENDANTSS: PEnalized Norm-ratios Disentangling Additive Noise, Trend and Sparse Spikes
Jan 04, 2023Denoising, detrending, deconvolution: usual restoration tasks, traditionally decoupled. Coupled formulations entail complex ill-posed inverse problems. We propose PENDANTSS for joint trend removal and blind deconvolution of sparse peak-like signals. It blends a parsimonious prior with the hypothesis that smooth trend and noise can somewhat be separated by low-pass filtering. We combine the generalized quasi-norm ratio SOOT/SPOQ sparse penalties $\ell_p/\ell_q$ with the BEADS ternary assisted source separation algorithm. This results in a both convergent and efficient tool, with a novel Trust-Region block alternating variable metric forward-backward approach. It outperforms comparable methods, when applied to typically peaked analytical chemistry signals. Reproducible code is provided.
Towards Practical Few-Shot Query Sets: Transductive Minimum Description Length Inference
Oct 26, 2022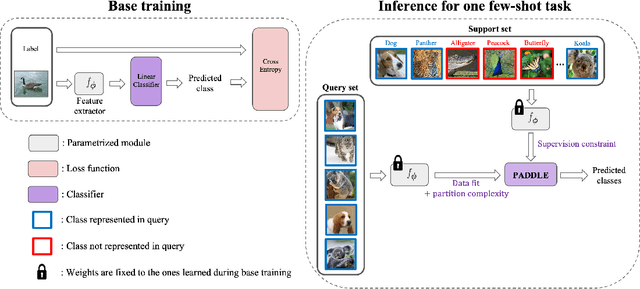
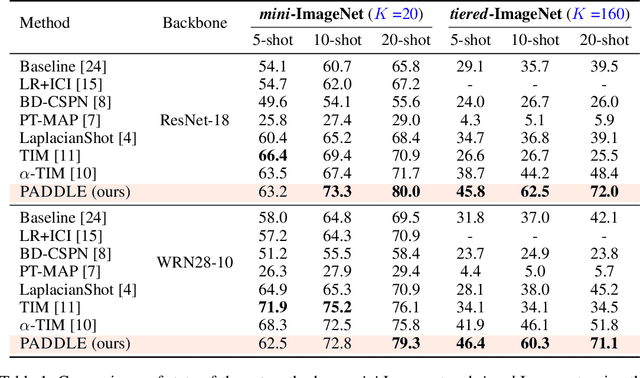
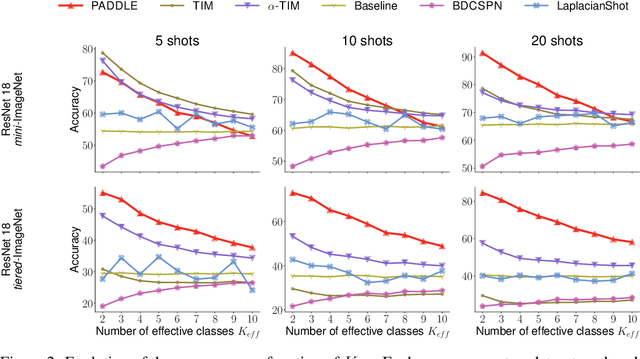
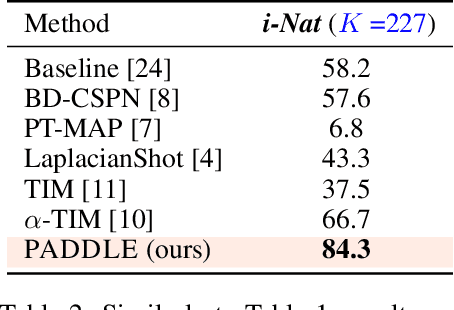
Standard few-shot benchmarks are often built upon simplifying assumptions on the query sets, which may not always hold in practice. In particular, for each task at testing time, the classes effectively present in the unlabeled query set are known a priori, and correspond exactly to the set of classes represented in the labeled support set. We relax these assumptions and extend current benchmarks, so that the query-set classes of a given task are unknown, but just belong to a much larger set of possible classes. Our setting could be viewed as an instance of the challenging yet practical problem of extremely imbalanced K-way classification, K being much larger than the values typically used in standard benchmarks, and with potentially irrelevant supervision from the support set. Expectedly, our setting incurs drops in the performances of state-of-the-art methods. Motivated by these observations, we introduce a PrimAl Dual Minimum Description LEngth (PADDLE) formulation, which balances data-fitting accuracy and model complexity for a given few-shot task, under supervision constraints from the support set. Our constrained MDL-like objective promotes competition among a large set of possible classes, preserving only effective classes that befit better the data of a few-shot task. It is hyperparameter free, and could be applied on top of any base-class training. Furthermore, we derive a fast block coordinate descent algorithm for optimizing our objective, with convergence guarantee, and a linear computational complexity at each iteration. Comprehensive experiments over the standard few-shot datasets and the more realistic and challenging i-Nat dataset show highly competitive performances of our method, more so when the numbers of possible classes in the tasks increase. Our code is publicly available at https://github.com/SegoleneMartin/PADDLE.