 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncated Neural Likelihood Estimation for Simulation-Based Inference in State-Space Models
May 20, 2026State-space models (SSMs) are powerful probabilistic tools for modeling time-varying systems with latent dynamics. Inference in SSMs involves the estimation of latent states and parameters. In this work, we focus on parameter inference, which for SSMs is in general a very challenging problem due to the intractability of the likelihood. Recently, neural estimation methods, such as sequential neural likelihood (SNL), have shown promising results in Bayesian inference problems. In this paper, we show that SNL, when applied to the SSM setting, suffers important limitations, such as requiring a large amount of simulated samples to achieve a moderate performance, scaling poorly with sequence length, while not being amortized. We then introduce a novel inference algorithm called truncated-SNL (T-SNL), which addresses the limitations of SNL. Our algorithm is more accurate, more stable and robust during training, more scalable to longer temporal sequences, and can be amortized when new observations become available. Our experiments show that T-SNL is sample-efficient, robust, and flexible algorithm which outperforms other approaches.
Signature-Kernel Based Evaluation Metrics for Robust Probabilistic and Tail-Event Forecasting
Feb 10, 2026Probabilistic forecasting is increasingly critical across high-stakes domains, from finance and epidemiology to climate science. However, current evaluation frameworks lack a consensus metric and suffer from two critical flaws: they often assume independence across time steps or variables, and they demonstrably lack sensitivity to tail events, the very occurrences that are most pivotal in real-world decision-making. To address these limitations, we propose two kernel-based metrics: the signature maximum mean discrepancy (Sig-MMD) and our novel censored Sig-MMD (CSig-MMD). By leveraging the signature kernel, these metrics capture complex inter-variate and inter-temporal dependencies and remain robust to missing data. Furthermore, CSig-MMD introduces a censoring scheme that prioritizes a forecaster's capability to predict tail events while strictly maintaining properness, a vital property for a good scoring rule. These metrics enable a more reliable evaluation of direct multi-step forecasting, facilitating the development of more robust probabilistic algorithms.
Discrete diffusion samplers and bridges: Off-policy algorithms and applications in latent spaces
Feb 05, 2026Sampling from a distribution $p(x) \propto e^{-\mathcal{E}(x)}$ known up to a normalising constant is an important and challenging problem in statistics. Recent years have seen the rise of a new family of amortised sampling algorithms, commonly referred to as diffusion samplers, that enable fast and efficient sampling from an unnormalised density. Such algorithms have been widely studied for continuous-space sampling tasks; however, their application to problems in discrete space remains largely unexplored. Although some progress has been made in this area, discrete diffusion samplers do not take full advantage of ideas commonly used for continuous-space sampling. In this paper, we propose to bridge this gap by introducing off-policy training techniques for discrete diffusion samplers. We show that these techniques improve the performance of discrete samplers on both established and new synthetic benchmarks. Next, we generalise discrete diffusion samplers to the task of bridging between two arbitrary distributions, introducing data-to-energy Schrödinger bridge training for the discrete domain for the first time. Lastly, we showcase the application of the proposed diffusion samplers to data-free posterior sampling in the discrete latent spaces of image generative models.
Scalable Expectation Estimation with Subtractive Mixture Models
Mar 27, 2025Many Monte Carlo (MC) and importance sampling (IS) methods use mixture models (MMs) for their simplicity and ability to capture multimodal distributions. Recently, subtractive mixture models (SMMs), i.e. MMs with negative coefficients, have shown greater expressiveness and success in generative modeling. However, their negative parameters complicate sampling, requiring costly auto-regressive techniques or accept-reject algorithms that do not scale in high dimensions. In this work, we use the difference representation of SMMs to construct an unbiased IS estimator ($\Delta\text{Ex}$) that removes the need to sample from the SMM, enabling high-dimensional expectation estimation with SMMs. In our experiments, we show that $\Delta\text{Ex}$ can achieve comparable estimation quality to auto-regressive sampling while being considerably faster in MC estimation. Moreover, we conduct initial experiments with $\Delta\text{Ex}$ using hand-crafted proposals, gaining first insights into how to construct safe proposals for $\Delta\text{Ex}$.
Differentiable Interacting Multiple Model Particle Filtering
Oct 01, 2024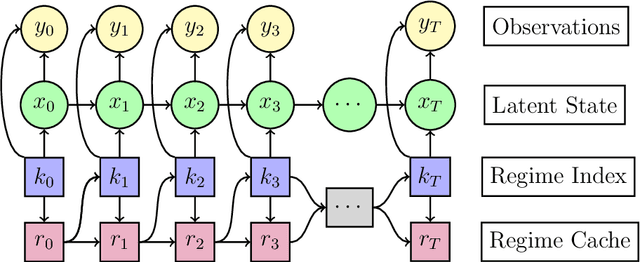
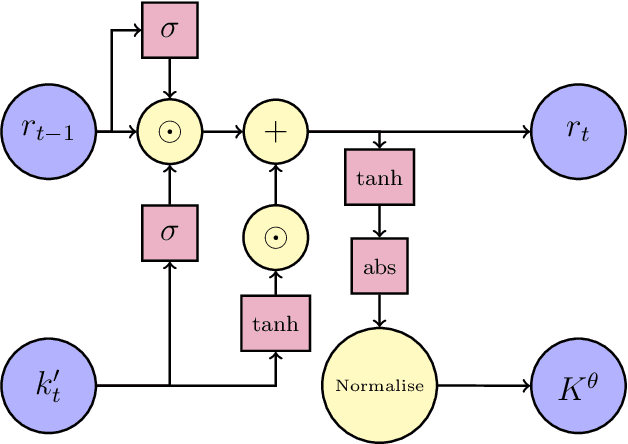
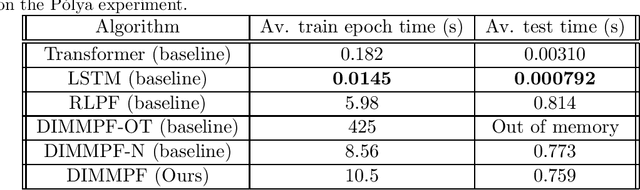
We propose a sequential Monte Carlo algorithm for parameter learning when the studied model exhibits random discontinuous jumps in behaviour. To facilitate the learning of high dimensional parameter sets, such as those associated to neural networks, we adopt the emerging framework of differentiable particle filtering, wherein parameters are trained by gradient descent. We design a new differentiable interacting multiple model particle filter to be capable of learning the individual behavioural regimes and the model which controls the jumping simultaneously. In contrast to previous approaches, our algorithm allows control of the computational effort assigned per regime whilst using the probability of being in a given regime to guide sampling. Furthermore, we develop a new gradient estimator that has a lower variance than established approaches and remains fast to compute, for which we prove consistency. We establish new theoretical results of the presented algorithms and demonstrate superior numerical performance compared to the previous state-of-the-art algorithms.
Efficient Mixture Learning in Black-Box Variational Inference
Jun 11, 2024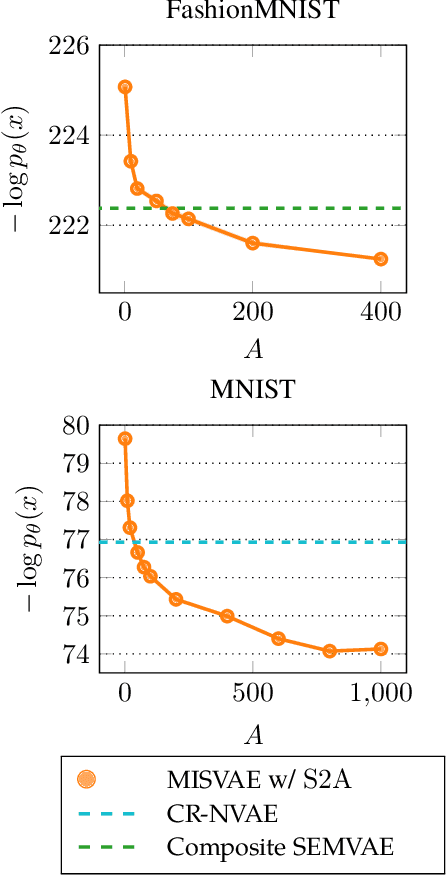
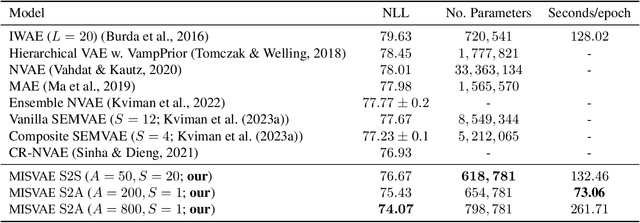


Mixture variational distributions in black box variational inference (BBVI) have demonstrated impressive results in challenging density estimation tasks. However, currently scaling the number of mixture components can lead to a linear increase in the number of learnable parameters and a quadratic increase in inference time due to the evaluation of the evidence lower bound (ELBO). Our two key contributions address these limitations. First, we introduce the novel Multiple Importance Sampling Variational Autoencoder (MISVAE), which amortizes the mapping from input to mixture-parameter space using one-hot encodings. Fortunately, with MISVAE, each additional mixture component incurs a negligible increase in network parameters. Second, we construct two new estimators of the ELBO for mixtures in BBVI, enabling a tremendous reduction in inference time with marginal or even improved impact on performance. Collectively, our contributions enable scalability to hundreds of mixture components and provide superior estimation performance in shorter time, with fewer network parameters compared to previous Mixture VAEs. Experimenting with MISVAE, we achieve astonishing, SOTA results on MNIST. Furthermore, we empirically validate our estimators in other BBVI settings, including Bayesian phylogenetic inference, where we improve inference times for the SOTA mixture model on eight data sets.
Adaptive importance sampling for heavy-tailed distributions via $α$-divergence minimization
Oct 25, 2023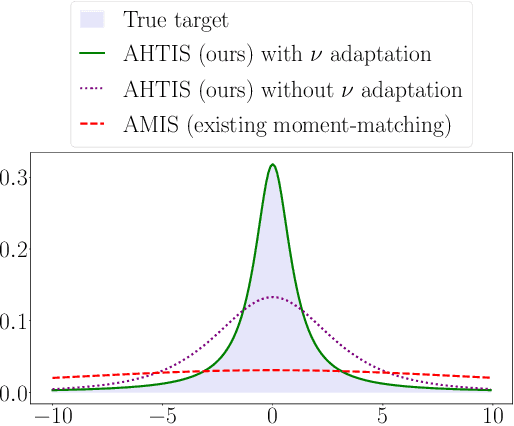
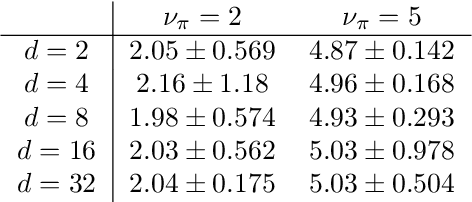
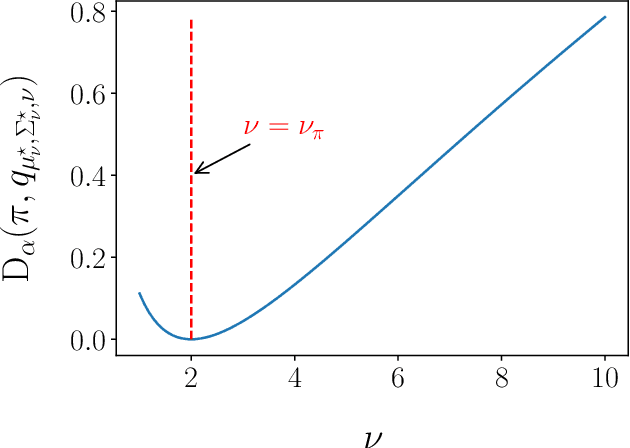
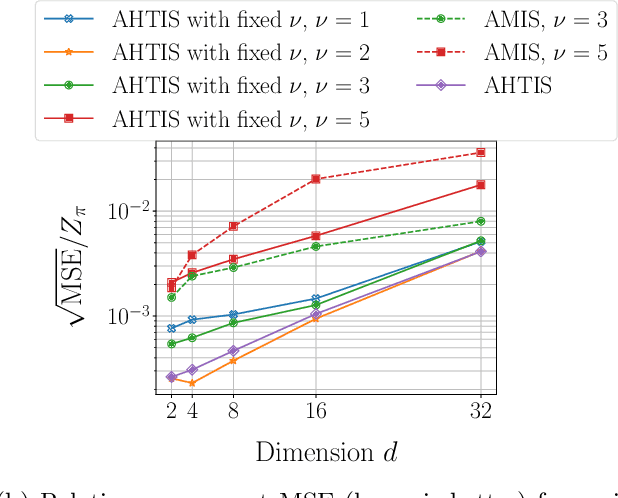
Adaptive importance sampling (AIS) algorithms are widely used to approximate expectations with respect to complicated target probability distributions. When the target has heavy tails, existing AIS algorithms can provide inconsistent estimators or exhibit slow convergence, as they often neglect the target's tail behaviour. To avoid this pitfall, we propose an AIS algorithm that approximates the target by Student-t proposal distributions. We adapt location and scale parameters by matching the escort moments - which are defined even for heavy-tailed distributions - of the target and the proposal. These updates minimize the $\alpha$-divergence between the target and the proposal, thereby connecting with variational inference. We then show that the $\alpha$-divergence can be approximated by a generalized notion of effective sample size and leverage this new perspective to adapt the tail parameter with Bayesian optimization. We demonstrate the efficacy of our approach through applications to synthetic targets and a Bayesian Student-t regression task on a real example with clinical trial data.
Graphs in State-Space Models for Granger Causality in Climate Science
Jul 20, 2023
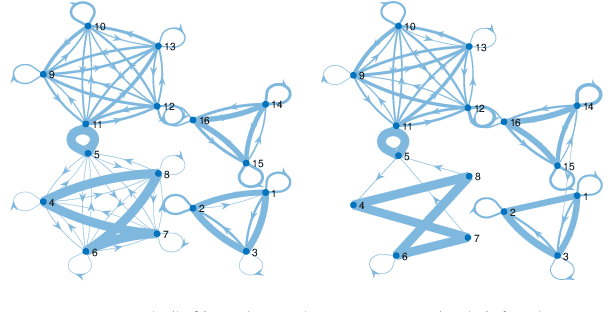
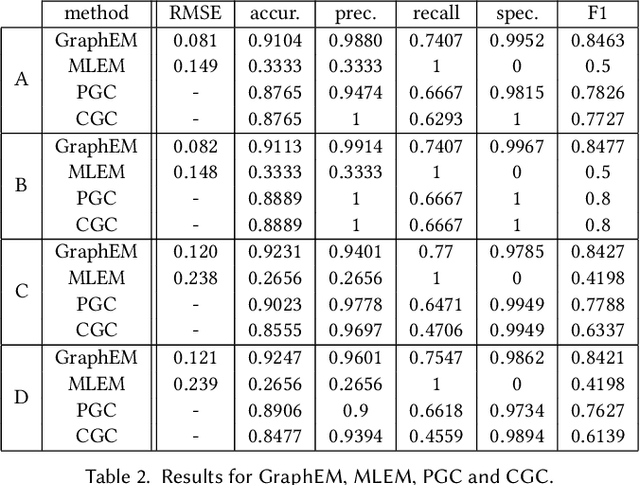

Granger causality (GC) is often considered not an actual form of causality. Still, it is arguably the most widely used method to assess the predictability of a time series from another one. Granger causality has been widely used in many applied disciplines, from neuroscience and econometrics to Earth sciences. We revisit GC under a graphical perspective of state-space models. For that, we use GraphEM, a recently presented expectation-maximisation algorithm for estimating the linear matrix operator in the state equation of a linear-Gaussian state-space model. Lasso regularisation is included in the M-step, which is solved using a proximal splitting Douglas-Rachford algorithm. Experiments in toy examples and challenging climate problems illustrate the benefits of the proposed model and inference technique over standard Granger causality methods.
Differentiable Bootstrap Particle Filters for Regime-Switching Models
Feb 20, 2023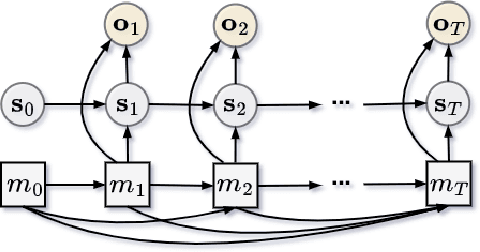
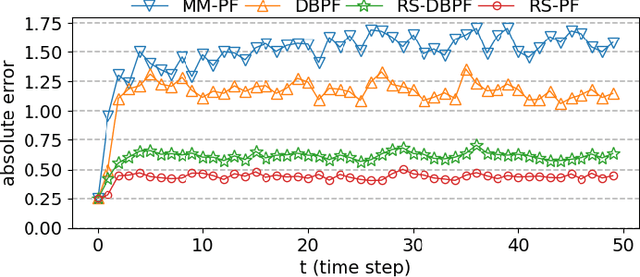
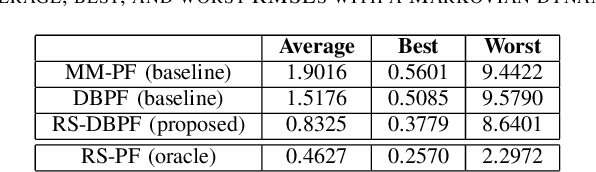
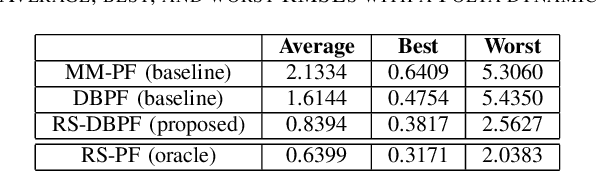
Differentiable particle filters are an emerging class of particle filtering methods that use neural networks to construct and learn parametric state-space models. In real-world applications, both the state dynamics and measurements can switch between a set of candidate models. For instance, in target tracking, vehicles can idle, move through traffic, or cruise on motorways, and measurements are collected in different geographical or weather conditions. This paper proposes a new differentiable particle filter for regime-switching state-space models. The method can learn a set of unknown candidate dynamic and measurement models and track the state posteriors. We evaluate the performance of the novel algorithm in relevant models, showing its great performance compared to other competitive algorithms.
Learning with MISELBO: The Mixture Cookbook
Sep 30, 2022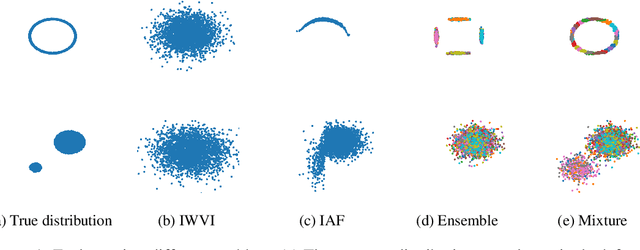
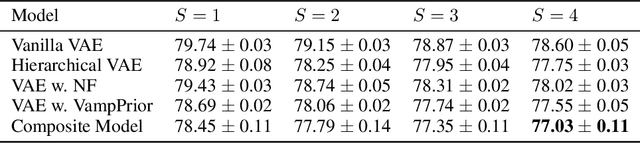

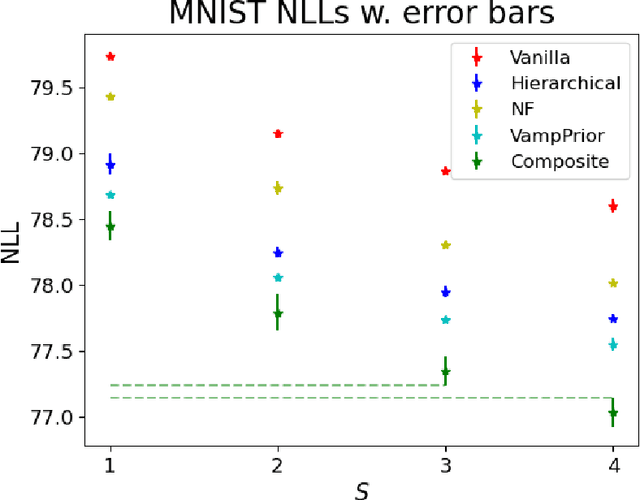
Mixture models in variational inference (VI) is an active field of research. Recent works have established their connection to multiple importance sampling (MIS) through the MISELBO and advanced the use of ensemble approximations for large-scale problems. However, as we show here, an independent learning of the ensemble components can lead to suboptimal diversity. Hence, we study the effect of instead using MISELBO as an objective function for learning mixtures, and we propose the first ever mixture of variational approximations for a normalizing flow-based hierarchical variational autoencoder (VAE) with VampPrior and a PixelCNN decoder network. Two major insights led to the construction of this novel composite model. First, mixture models have potential to be off-the-shelf tools for practitioners to obtain more flexible posterior approximations in VAEs. Therefore, we make them more accessible by demonstrating how to apply them to four popular architectures. Second, the mixture components cooperate in order to cover the target distribution while trying to maximize their diversity when MISELBO is the objective function. We explain this cooperative behavior by drawing a novel connection between VI and adaptive importance sampling. Finally, we demonstrate the superiority of the Mixture VAEs' learned feature representations on both image and single-cell transcriptome data, and obtain state-of-the-art results among VAE architectures in terms of negative log-likelihood on the MNIST and FashionMNIST datasets. Code available here: \url{https://github.com/Lagergren-Lab/MixtureVAEs}.