 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Sampling: A Critical and Comprehensive Theoretical Guide
Jun 16, 2026The nested sampling (NS) technique has gained widespread attention, particularly in cosmology and astronomy, due to its ability to efficiently explore high-likelihood regions - a feature akin to an implicit likelihood optimization that underlies its success. While the full theoretical derivation of NS is complex and involves several approximations, the central challenge lies in sampling from the likelihood-constrained priors, which is crucial for its performance. This work provides a comprehensive and detailed exposition of NS derivation, clarifying both its theoretical foundations and practical challenges. We provide a thorough description of the NS procedure, emphasizing both its strengths and potential limitations. In doing so, this work seeks to deepen understanding of the method and to foster the development of future enhancements, novel variants, and more efficient implementations across a wide range of scientific applications. Thus, the main contribution of this work is twofold: it serves both as a tutorial for newcomers to the field and as a critical review for experienced practitioners.
A unifying view of contrastive learning, importance sampling, and bridge sampling for energy-based models
Apr 09, 2026In the last decades, energy-based models (EBMs) have become an important class of probabilistic models in which a component of the likelihood is intractable and therefore cannot be evaluated explicitly. Consequently, parameter estimation in EBMs is challenging for conventional inference methods. In this work, we provide a unified framework that connects noise contrastive estimation (NCE), reverse logistic regression (RLR), multiple importance sampling (MIS), and bridge sampling within the context of EBMs. We further show that these methods are equivalent under specific conditions. This unified perspective clarifies relationships among existing methods and enables the development of new estimators, with the potential to improve statistical and computational efficiency. Furthermore, this study helps elucidate the success of NCE in terms of its flexibility and robustness, while also identifying scenarios in which its performance can be further improved. Hence, rather than being a purely descriptive review, this work offers a unifying perspective and additional methodological contributions. The MATLAB code used in the numerical experiments is also made freely available to support the reproducibility of the results.
An index of effective number of variables for uncertainty and reliability analysis in model selection problems
Feb 24, 2026An index of an effective number of variables (ENV) is introduced for model selection in nested models. This is the case, for instance, when we have to decide the order of a polynomial function or the number of bases in a nonlinear regression, choose the number of clusters in a clustering problem, or the number of features in a variable selection application (to name few examples). It is inspired by the idea of the maximum area under the curve (AUC). The interpretation of the ENV index is identical to the effective sample size (ESS) indices concerning a set of samples. The ENV index improves {drawbacks of} the elbow detectors described in the literature and introduces different confidence measures of the proposed solution. These novel measures can be also employed jointly with the use of different information criteria, such as the well-known AIC and BIC, or any other model selection procedures. Comparisons with classical and recent schemes are provided in different experiments involving real datasets. Related Matlab code is given.
Enhancing Graphical Lasso: A Robust Scheme for Non-Stationary Mean Data
Mar 25, 2025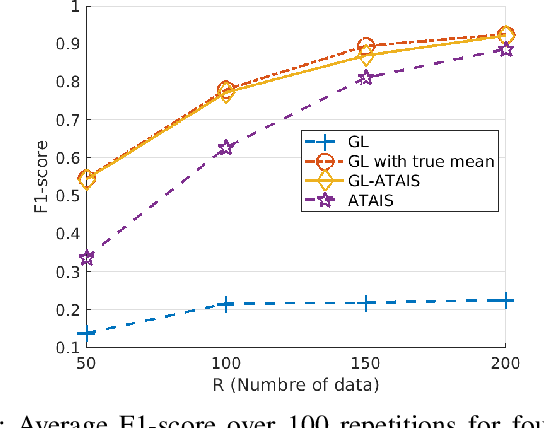
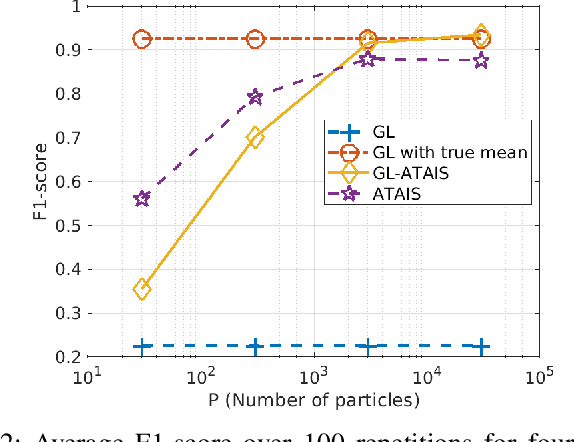
This work addresses the problem of graph learning from data following a Gaussian Graphical Model (GGM) with a time-varying mean. Graphical Lasso (GL), the standard method for estimating sparse precision matrices, assumes that the observed data follows a zero-mean Gaussian distribution. However, this assumption is often violated in real-world scenarios where the mean evolves over time due to external influences, trends, or regime shifts. When the mean is not properly accounted for, applying GL directly can lead to estimating a biased precision matrix, hence hindering the graph learning task. To overcome this limitation, we propose Graphical Lasso with Adaptive Targeted Adaptive Importance Sampling (GL-ATAIS), an iterative method that jointly estimates the time-varying mean and the precision matrix. Our approach integrates Bayesian inference with frequentist estimation, leveraging importance sampling to obtain an estimate of the mean while using a regularized maximum likelihood estimator to infer the precision matrix. By iteratively refining both estimates, GL-ATAIS mitigates the bias introduced by time-varying means, leading to more accurate graph recovery. Our numerical evaluation demonstrates the impact of properly accounting for time-dependent means and highlights the advantages of GL-ATAIS over standard GL in recovering the true graph structure.
Optimality in importance sampling: a gentle survey
Feb 11, 2025
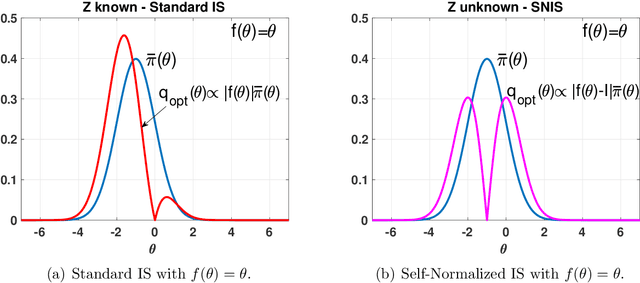

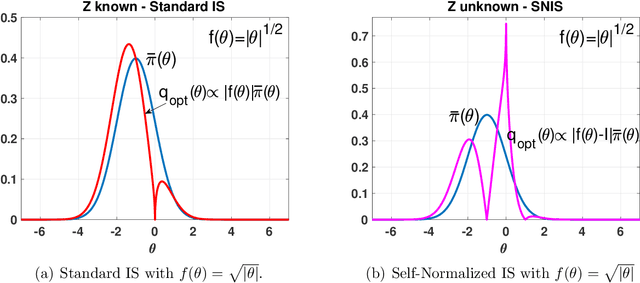
The performance of the Monte Carlo sampling methods relies on the crucial choice of a proposal density. The notion of optimality is fundamental to design suitable adaptive procedures of the proposal density within Monte Carlo schemes. This work is an exhaustive review around the concept of optimality in importance sampling. Several frameworks are described and analyzed, such as the marginal likelihood approximation for model selection, the use of multiple proposal densities, a sequence of tempered posteriors, and noisy scenarios including the applications to approximate Bayesian computation (ABC) and reinforcement learning, to name a few. Some theoretical and empirical comparisons are also provided.
CAMEO: Curiosity Augmented Metropolis for Exploratory Optimal Policies
May 19, 2022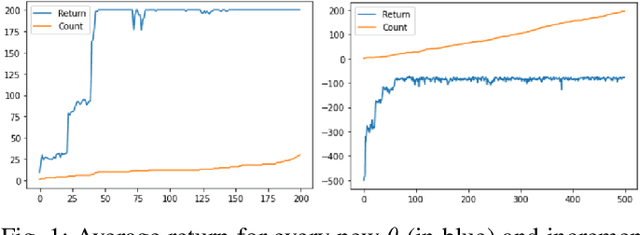
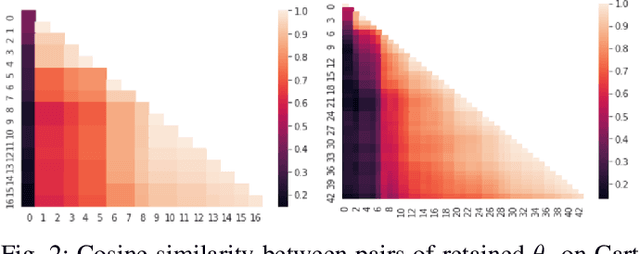
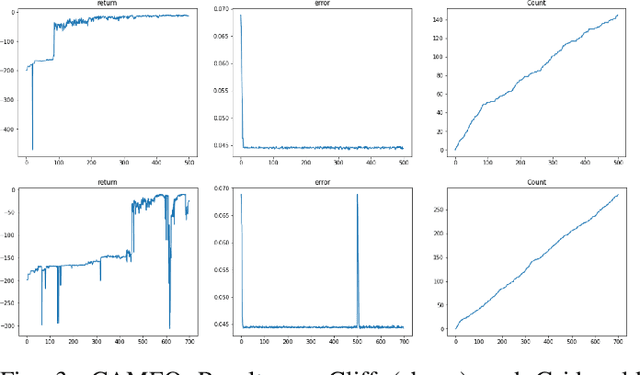
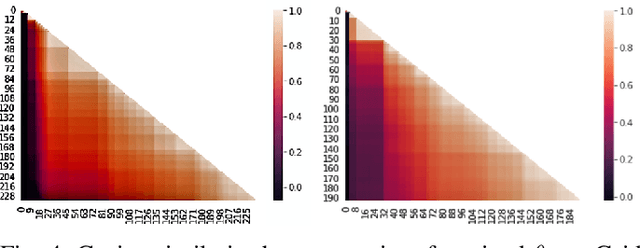
Reinforcement Learning has drawn huge interest as a tool for solving optimal control problems. Solving a given problem (task or environment) involves converging towards an optimal policy. However, there might exist multiple optimal policies that can dramatically differ in their behaviour; for example, some may be faster than the others but at the expense of greater risk. We consider and study a distribution of optimal policies. We design a curiosity-augmented Metropolis algorithm (CAMEO), such that we can sample optimal policies, and such that these policies effectively adopt diverse behaviours, since this implies greater coverage of the different possible optimal policies. In experimental simulations we show that CAMEO indeed obtains policies that all solve classic control problems, and even in the challenging case of environments that provide sparse rewards. We further show that the different policies we sample present different risk profiles, corresponding to interesting practical applications in interpretability, and represents a first step towards learning the distribution of optimal policies itself.
Inference over radiative transfer models using variational and expectation maximization methods
Apr 07, 2022

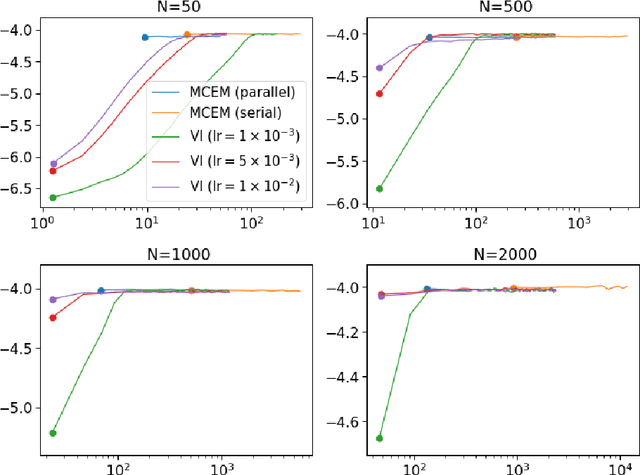

Earth observation from satellites offers the possibility to monitor our planet with unprecedented accuracy. Radiative transfer models (RTMs) encode the energy transfer through the atmosphere, and are used to model and understand the Earth system, as well as to estimate the parameters that describe the status of the Earth from satellite observations by inverse modeling. However, performing inference over such simulators is a challenging problem. RTMs are nonlinear, non-differentiable and computationally costly codes, which adds a high level of difficulty in inference. In this paper, we introduce two computational techniques to infer not only point estimates of biophysical parameters but also their joint distribution. One of them is based on a variational autoencoder approach and the second one is based on a Monte Carlo Expectation Maximization (MCEM) scheme. We compare and discuss benefits and drawbacks of each approach. We also provide numerical comparisons in synthetic simulations and the real PROSAIL model, a popular RTM that combines land vegetation leaf and canopy modeling. We analyze the performance of the two approaches for modeling and inferring the distribution of three key biophysical parameters for quantifying the terrestrial biosphere.
Optimality in Noisy Importance Sampling
Jan 07, 2022
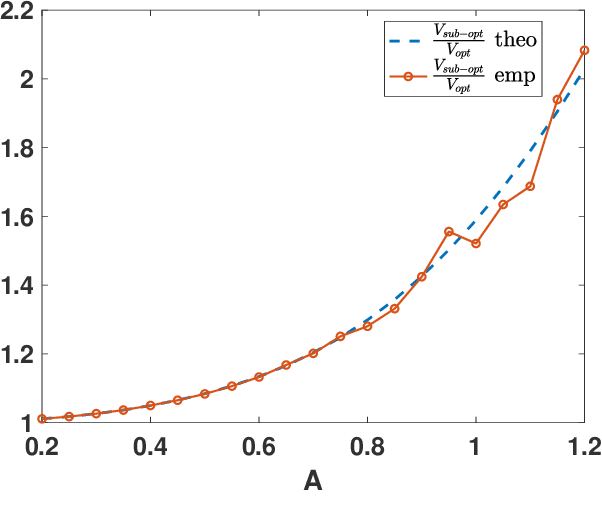
In this work, we analyze the noisy importance sampling (IS), i.e., IS working with noisy evaluations of the target density. We present the general framework and derive optimal proposal densities for noisy IS estimators. The optimal proposals incorporate the information of the variance of the noisy realizations, proposing points in regions where the noise power is higher. We also compare the use of the optimal proposals with previous optimality approaches considered in a noisy IS framework.
Compressed particle methods for expensive models with application in Astronomy and Remote Sensing
Jul 18, 2021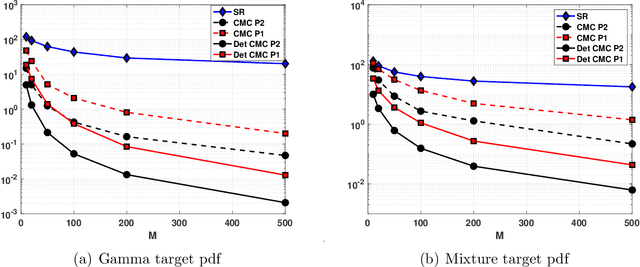

In many inference problems, the evaluation of complex and costly models is often required. In this context, Bayesian methods have become very popular in several fields over the last years, in order to obtain parameter inversion, model selection or uncertainty quantification. Bayesian inference requires the approximation of complicated integrals involving (often costly) posterior distributions. Generally, this approximation is obtained by means of Monte Carlo (MC) methods. In order to reduce the computational cost of the corresponding technique, surrogate models (also called emulators) are often employed. Another alternative approach is the so-called Approximate Bayesian Computation (ABC) scheme. ABC does not require the evaluation of the costly model but the ability to simulate artificial data according to that model. Moreover, in ABC, the choice of a suitable distance between real and artificial data is also required. In this work, we introduce a novel approach where the expensive model is evaluated only in some well-chosen samples. The selection of these nodes is based on the so-called compressed Monte Carlo (CMC) scheme. We provide theoretical results supporting the novel algorithms and give empirical evidence of the performance of the proposed method in several numerical experiments. Two of them are real-world applications in astronomy and satellite remote sensing.
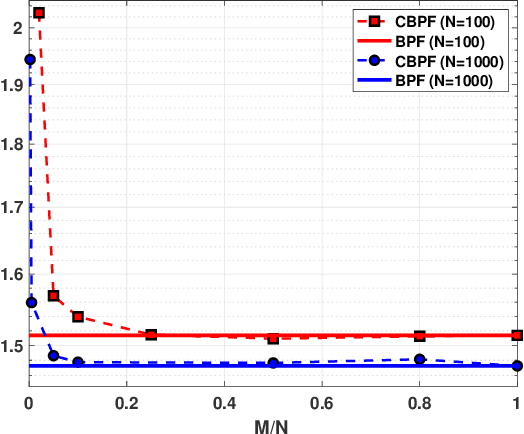
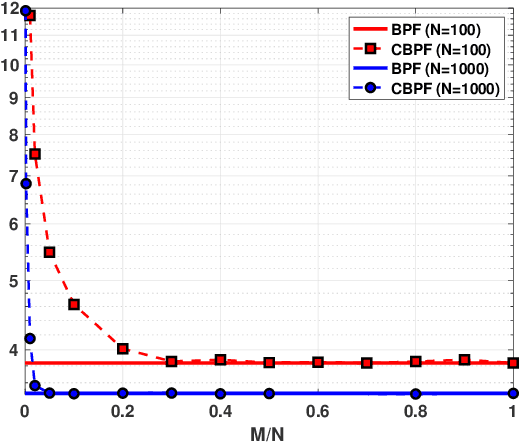
Compressed Monte Carlo with application in particle filtering
Jul 18, 2021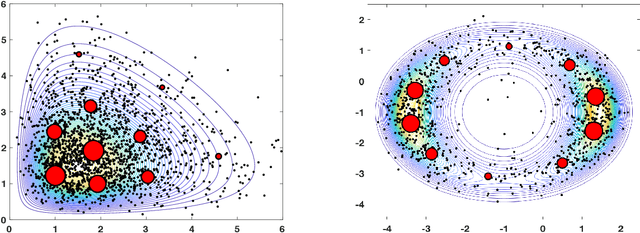
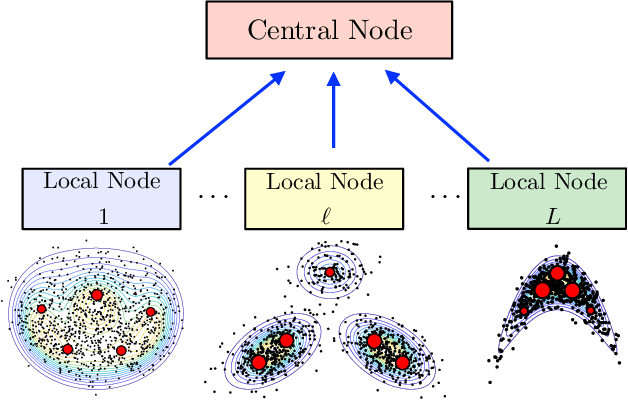
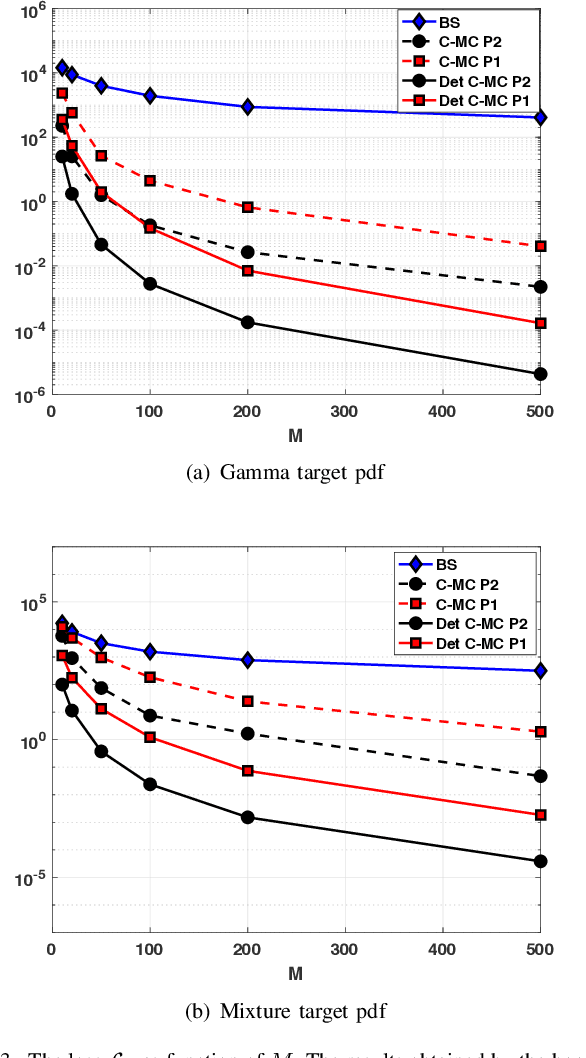
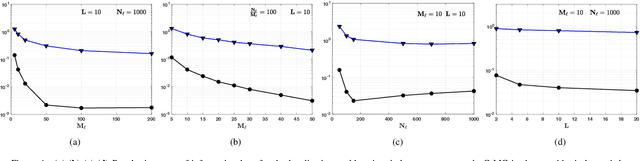
Bayesian models have become very popular over the last years in several fields such as signal processing, statistics, and machine learning. Bayesian inference requires the approximation of complicated integrals involving posterior distributions. For this purpose, Monte Carlo (MC) methods, such as Markov Chain Monte Carlo and importance sampling algorithms, are often employed. In this work, we introduce the theory and practice of a Compressed MC (C-MC) scheme to compress the statistical information contained in a set of random samples. In its basic version, C-MC is strictly related to the stratification technique, a well-known method used for variance reduction purposes. Deterministic C-MC schemes are also presented, which provide very good performance. The compression problem is strictly related to the moment matching approach applied in different filtering techniques, usually called as Gaussian quadrature rules or sigma-point methods. C-MC can be employed in a distributed Bayesian inference framework when cheap and fast communications with a central processor are required. Furthermore, C-MC is useful within particle filtering and adaptive IS algorithms, as shown by three novel schemes introduced in this work. Six numerical results confirm the benefits of the introduced schemes, outperforming the corresponding benchmark methods. A related code is also provided.