 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint introduction to Gaussian Processes and Relevance Vector Machines with Connections to Kalman filtering and other Kernel Smoothers
Paper and Code
Sep 22, 2020
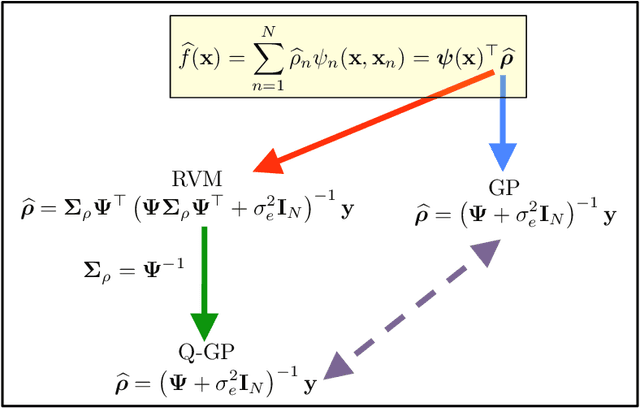
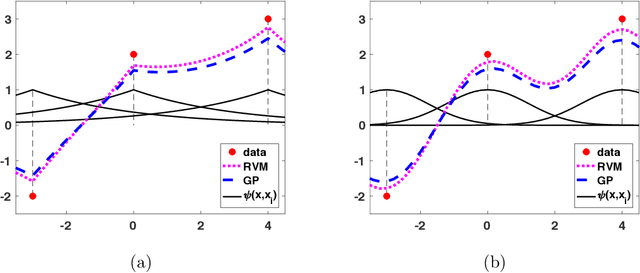

The expressive power of Bayesian kernel-based methods has led them to become an important tool across many different facets of artificial intelligence, and useful to a plethora of modern application domains, providing both power and interpretability via uncertainty analysis. This article introduces and discusses two methods which straddle the areas of probabilistic Bayesian schemes and kernel methods for regression: Gaussian Processes and Relevance Vector Machines. Our focus is on developing a common framework with which to view these methods, via intermediate methods a probabilistic version of the well-known kernel ridge regression, and drawing connections among them, via dual formulations, and discussion of their application in the context of major tasks: regression, smoothing, interpolation, and filtering. Overall, we provide understanding of the mathematical concepts behind these models, and we summarize and discuss in depth different interpretations and highlight the relationship to other methods, such as linear kernel smoothers, Kalman filtering and Fourier approximations. Throughout, we provide numerous figures to promote understanding, and we make numerous recommendations to practitioners. Benefits and drawbacks of the different techniques are highlighted. To our knowledge, this is the most in-depth study of its kind to date focused on these two methods, and will be relevant to theoretical understanding and practitioners throughout the domains of data-science, signal processing, machine learning, and artificial intelligence in general.