 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Domain Knowledge in Data-driven Earth Observation with Process Convolutions
Apr 16, 2021
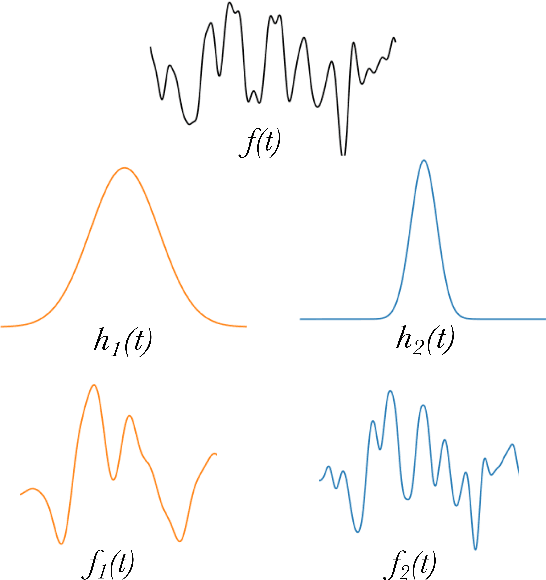
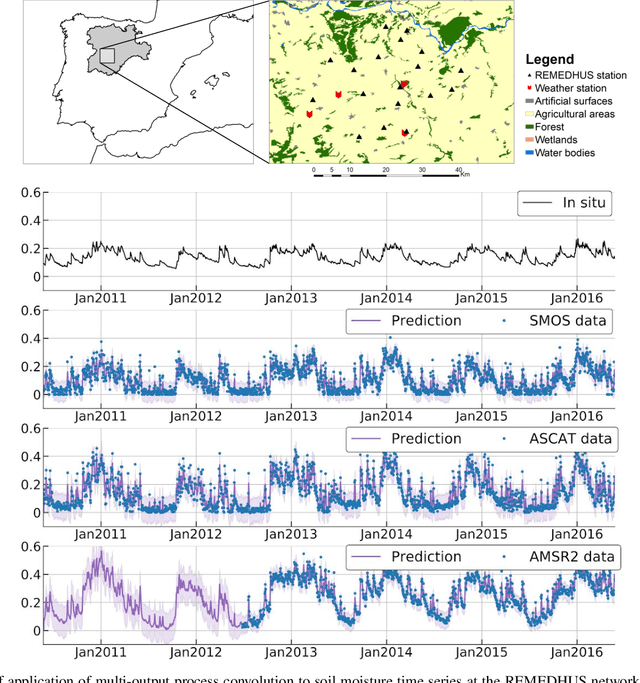
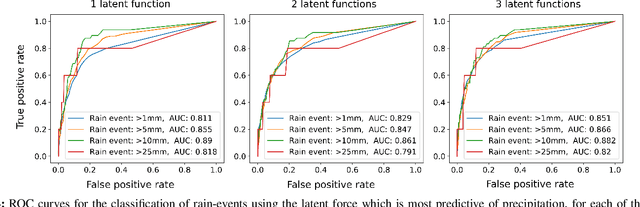
The modelling of Earth observation data is a challenging problem, typically approached by either purely mechanistic or purely data-driven methods. Mechanistic models encode the domain knowledge and physical rules governing the system. Such models, however, need the correct specification of all interactions between variables in the problem and the appropriate parameterization is a challenge in itself. On the other hand, machine learning approaches are flexible data-driven tools, able to approximate arbitrarily complex functions, but lack interpretability and struggle when data is scarce or in extrapolation regimes. In this paper, we argue that hybrid learning schemes that combine both approaches can address all these issues efficiently. We introduce Gaussian process (GP) convolution models for hybrid modelling in Earth observation (EO) problems. We specifically propose the use of a class of GP convolution models called latent force models (LFMs) for EO time series modelling, analysis and understanding. LFMs are hybrid models that incorporate physical knowledge encoded in differential equations into a multioutput GP model. LFMs can transfer information across time-series, cope with missing observations, infer explicit latent functions forcing the system, and learn parameterizations which are very helpful for system analysis and interpretability. We consider time series of soil moisture from active (ASCAT) and passive (SMOS, AMSR2) microwave satellites. We show how assuming a first order differential equation as governing equation, the model automatically estimates the e-folding time or decay rate related to soil moisture persistence and discovers latent forces related to precipitation. The proposed hybrid methodology reconciles the two main approaches in remote sensing parameter estimation by blending statistical learning and mechanistic modeling.
Cloud detection machine learning algorithms for PROBA-V
Dec 09, 2020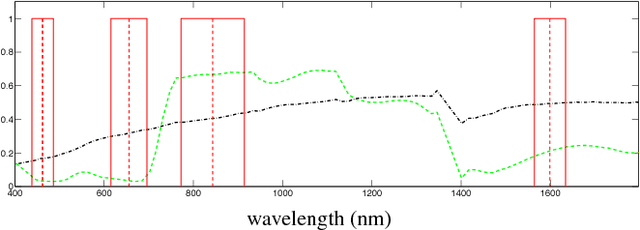
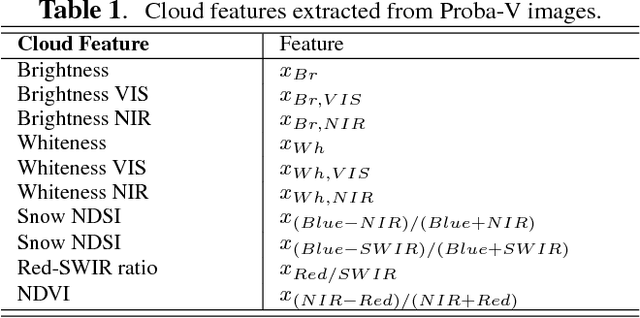

This paper presents the development and implementation of a cloud detection algorithm for Proba-V. Accurate and automatic detection of clouds in satellite scenes is a key issue for a wide range of remote sensing applications. With no accurate cloud masking, undetected clouds are one of the most significant sources of error in both sea and land cover biophysical parameter retrieval. The objective of the algorithms presented in this paper is to detect clouds accurately providing a cloud flag per pixel. For this purpose, the method exploits the information of Proba-V using statistical machine learning techniques to identify the clouds present in Proba-V products. The effectiveness of the proposed method is successfully illustrated using a large number of real Proba-V images.
Warped Gaussian Processes in Remote Sensing Parameter Estimation and Causal Inference
Dec 09, 2020
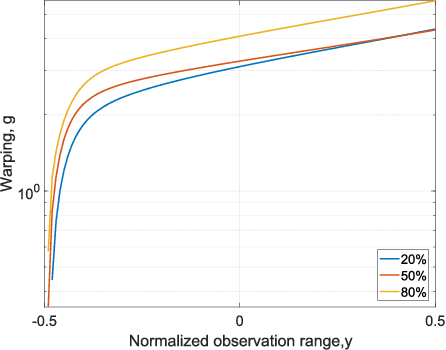
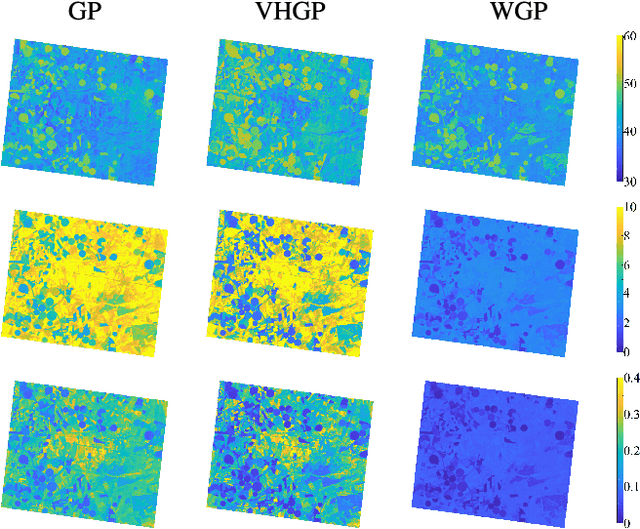
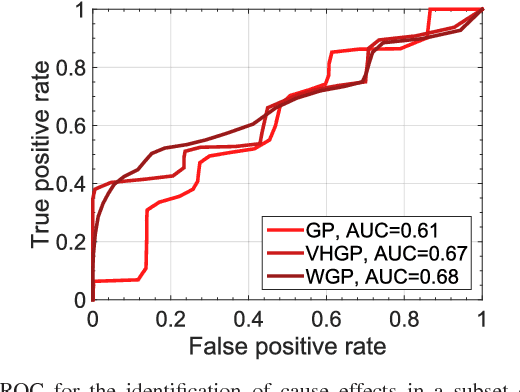
This paper introduces warped Gaussian processes (WGP) regression in remote sensing applications. WGP models output observations as a parametric nonlinear transformation of a GP. The parameters of such prior model are then learned via standard maximum likelihood. We show the good performance of the proposed model for the estimation of oceanic chlorophyll content from multispectral data, vegetation parameters (chlorophyll, leaf area index, and fractional vegetation cover) from hyperspectral data, and in the detection of the causal direction in a collection of 28 bivariate geoscience and remote sensing causal problems. The model consistently performs better than the standard GP and the more advanced heteroscedastic GP model, both in terms of accuracy and more sensible confidence intervals.
Pattern Recognition Scheme for Large-Scale Cloud Detection over Landmarks
Dec 08, 2020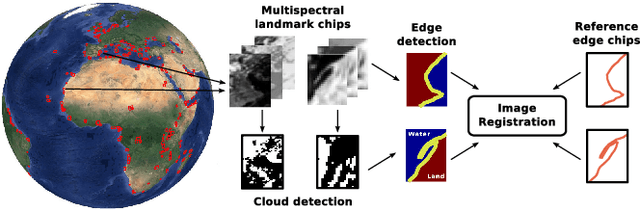

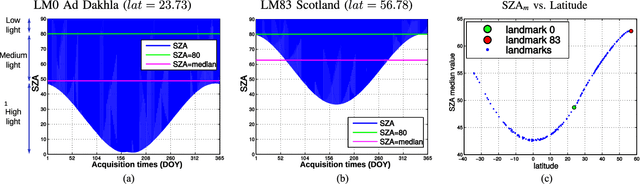

Landmark recognition and matching is a critical step in many Image Navigation and Registration (INR) models for geostationary satellite services, as well as to maintain the geometric quality assessment (GQA) in the instrument data processing chain of Earth observation satellites. Matching the landmark accurately is of paramount relevance, and the process can be strongly impacted by the cloud contamination of a given landmark. This paper introduces a complete pattern recognition methodology able to detect the presence of clouds over landmarks using Meteosat Second Generation (MSG) data. The methodology is based on the ensemble combination of dedicated support vector machines (SVMs) dependent on the particular landmark and illumination conditions. This divide-and-conquer strategy is motivated by the data complexity and follows a physically-based strategy that considers variability both in seasonality and illumination conditions along the day to split observations. In addition, it allows training the classification scheme with millions of samples at an affordable computational costs. The image archive was composed of 200 landmark test sites with near 7 million multispectral images that correspond to MSG acquisitions during 2010. Results are analyzed in terms of cloud detection accuracy and computational cost. We provide illustrative source code and a portion of the huge training data to the community.
Nonlinear Distribution Regression for Remote Sensing Applications
Dec 07, 2020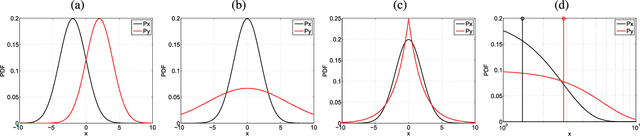
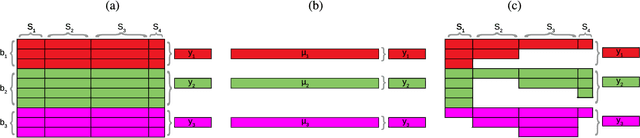
In many remote sensing applications one wants to estimate variables or parameters of interest from observations. When the target variable is available at a resolution that matches the remote sensing observations, standard algorithms such as neural networks, random forests or Gaussian processes are readily available to relate the two. However, we often encounter situations where the target variable is only available at the group level, i.e. collectively associated to a number of remotely sensed observations. This problem setting is known in statistics and machine learning as {\em multiple instance learning} or {\em distribution regression}. This paper introduces a nonlinear (kernel-based) method for distribution regression that solves the previous problems without making any assumption on the statistics of the grouped data. The presented formulation considers distribution embeddings in reproducing kernel Hilbert spaces, and performs standard least squares regression with the empirical means therein. A flexible version to deal with multisource data of different dimensionality and sample sizes is also presented and evaluated. It allows working with the native spatial resolution of each sensor, avoiding the need of match-up procedures. Noting the large computational cost of the approach, we introduce an efficient version via random Fourier features to cope with millions of points and groups.
Randomized kernels for large scale Earth observation applications
Dec 07, 2020Dealing with land cover classification of the new image sources has also turned to be a complex problem requiring large amount of memory and processing time. In order to cope with these problems, statistical learning has greatly helped in the last years to develop statistical retrieval and classification models that can ingest large amounts of Earth observation data. Kernel methods constitute a family of powerful machine learning algorithms, which have found wide use in remote sensing and geosciences. However, kernel methods are still not widely adopted because of the high computational cost when dealing with large scale problems, such as the inversion of radiative transfer models or the classification of high spatial-spectral-temporal resolution data. This paper introduces an efficient kernel method for fast statistical retrieval of bio-geo-physical parameters and image classification problems. The method allows to approximate a kernel matrix with a set of projections on random bases sampled from the Fourier domain. The method is simple, computationally very efficient in both memory and processing costs, and easily parallelizable. We show that kernel regression and classification is now possible for datasets with millions of examples and high dimensionality. Examples on atmospheric parameter retrieval from hyperspectral infrared sounders like IASI/Metop; large scale emulation and inversion of the familiar PROSAIL radiative transfer model on Sentinel-2 data; and the identification of clouds over landmarks in time series of MSG/Seviri images show the efficiency and effectiveness of the proposed technique.
Emulation as an Accurate Alternative to Interpolation in Sampling Radiative Transfer Codes
Dec 07, 2020
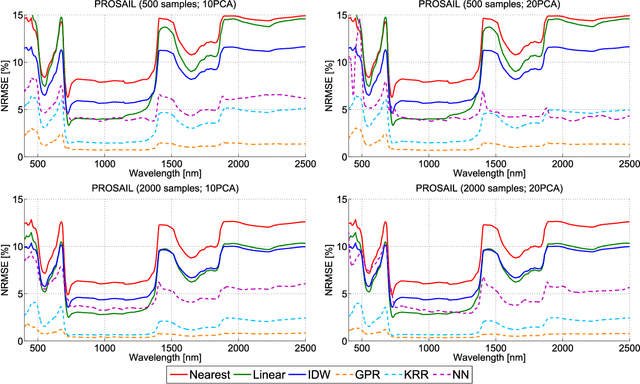

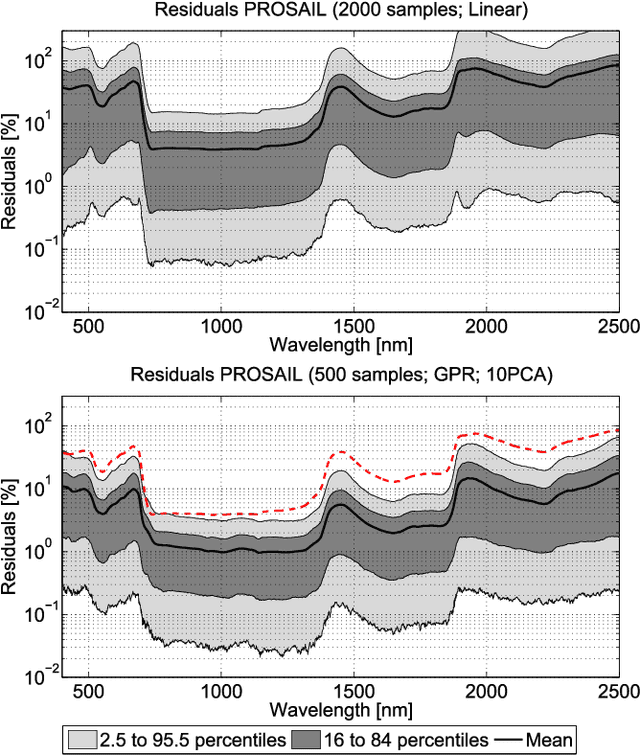
Computationally expensive Radiative Transfer Models (RTMs) are widely used} to realistically reproduce the light interaction with the Earth surface and atmosphere. Because these models take long processing time, the common practice is to first generate a sparse look-up table (LUT) and then make use of interpolation methods to sample the multi-dimensional LUT input variable space. However, the question arise whether common interpolation methods perform most accurate. As an alternative to interpolation, this work proposes to use emulation, i.e., approximating the RTM output by means of statistical learning. Two experiments were conducted to assess the accuracy in delivering spectral outputs using interpolation and emulation: (1) at canopy level, using PROSAIL; and (2) at top-of-atmosphere level, using MODTRAN. Various interpolation (nearest-neighbour, inverse distance weighting, piece-wice linear) and emulation (Gaussian process regression (GPR), kernel ridge regression, neural networks) methods were evaluated against a dense reference LUT. In all experiments, the emulation methods clearly produced more accurate output spectra than classical interpolation methods. GPR emulation performed up to ten times more accurately than the best performing interpolation method, and this with a speed that is competitive with the faster interpolation methods. It is concluded that emulation can function as a fast and more accurate alternative to commonly used interpolation methods for reconstructing RTM spectral data.
Active Learning Methods for Efficient Hybrid Biophysical Variable Retrieval
Dec 07, 2020


Kernel-based machine learning regression algorithms (MLRAs) are potentially powerful methods for being implemented into operational biophysical variable retrieval schemes. However, they face difficulties in coping with large training datasets. With the increasing amount of optical remote sensing data made available for analysis and the possibility of using a large amount of simulated data from radiative transfer models (RTMs) to train kernel MLRAs, efficient data reduction techniques will need to be implemented. Active learning (AL) methods enable to select the most informative samples in a dataset. This letter introduces six AL methods for achieving optimized biophysical variable estimation with a manageable training dataset, and their implementation into a Matlab-based MLRA toolbox for semi-automatic use. The AL methods were analyzed on their efficiency of improving the estimation accuracy of leaf area index and chlorophyll content based on PROSAIL simulations. Each of the implemented methods outperformed random sampling, improving retrieval accuracy with lower sampling rates. Practically, AL methods open opportunities to feed advanced MLRAs with RTM-generated training data for development of operational retrieval models.
Fusing Optical and SAR time series for LAI gap filling with multioutput Gaussian processes
Dec 05, 2020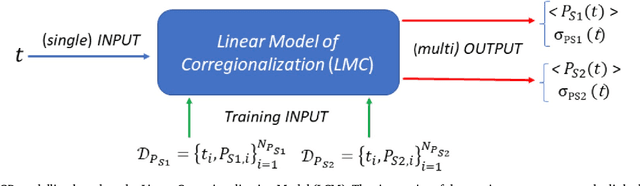
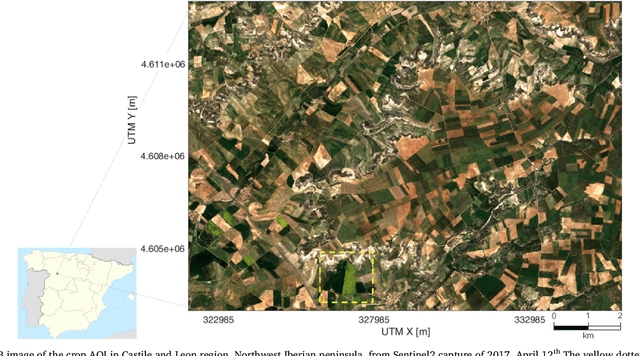

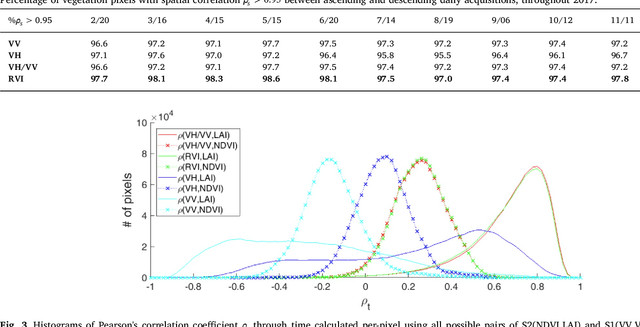
The availability of satellite optical information is often hampered by the natural presence of clouds, which can be problematic for many applications. Persistent clouds over agricultural fields can mask key stages of crop growth, leading to unreliable yield predictions. Synthetic Aperture Radar (SAR) provides all-weather imagery which can potentially overcome this limitation, but given its high and distinct sensitivity to different surface properties, the fusion of SAR and optical data still remains an open challenge. In this work, we propose the use of Multi-Output Gaussian Process (MOGP) regression, a machine learning technique that learns automatically the statistical relationships among multisensor time series, to detect vegetated areas over which the synergy between SAR-optical imageries is profitable. For this purpose, we use the Sentinel-1 Radar Vegetation Index (RVI) and Sentinel-2 Leaf Area Index (LAI) time series over a study area in north west of the Iberian peninsula. Through a physical interpretation of MOGP trained models, we show its ability to provide estimations of LAI even over cloudy periods using the information shared with RVI, which guarantees the solution keeps always tied to real measurements. Results demonstrate the advantage of MOGP especially for long data gaps, where optical-based methods notoriously fail. The leave-one-image-out assessment technique applied to the whole vegetation cover shows MOGP predictions improve standard GP estimations over short-time gaps (R$^2$ of 74\% vs 68\%, RMSE of 0.4 vs 0.44 $[m^2m^{-2}]$) and especially over long-time gaps (R$^2$ of 33\% vs 12\%, RMSE of 0.5 vs 1.09 $[m^2m^{-2}]$).
* 43 pages, 12 figures
Living in the Physics and Machine Learning Interplay for Earth Observation
Oct 18, 2020
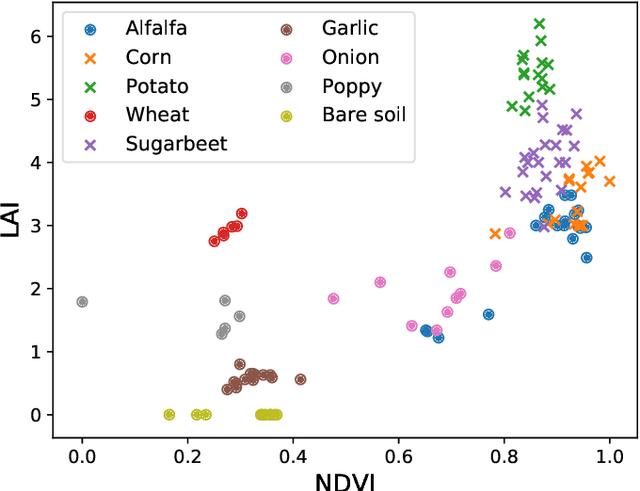

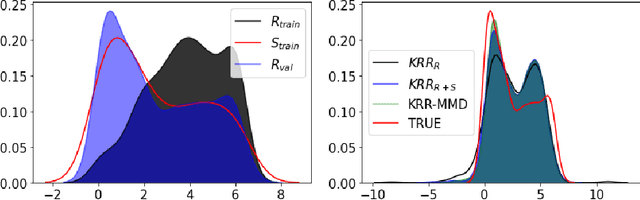
Most problems in Earth sciences aim to do inferences about the system, where accurate predictions are just a tiny part of the whole problem. Inferences mean understanding variables relations, deriving models that are physically interpretable, that are simple parsimonious, and mathematically tractable. Machine learning models alone are excellent approximators, but very often do not respect the most elementary laws of physics, like mass or energy conservation, so consistency and confidence are compromised. In this paper, we describe the main challenges ahead in the field, and introduce several ways to live in the Physics and machine learning interplay: to encode differential equations from data, constrain data-driven models with physics-priors and dependence constraints, improve parameterizations, emulate physical models, and blend data-driven and process-based models. This is a collective long-term AI agenda towards developing and applying algorithms capable of discovering knowledge in the Earth system.