 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperational machine learning for remote spectroscopic detection of CH$_{4}$ point sources
Nov 11, 2025


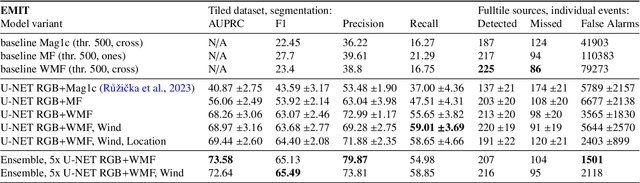
Mitigating anthropogenic methane sources is one the most cost-effective levers to slow down global warming. While satellite-based imaging spectrometers, such as EMIT, PRISMA, and EnMAP, can detect these point sources, current methane retrieval methods based on matched filters still produce a high number of false detections requiring laborious manual verification. This paper describes the operational deployment of a machine learning system for detecting methane emissions within the Methane Alert and Response System (MARS) of the United Nations Environment Programme's International Methane Emissions Observatory. We created the largest and most diverse global dataset of annotated methane plumes from three imaging spectrometer missions and quantitatively compared different deep learning model configurations. Focusing on the requirements for operational deployment, we extended prior evaluation methodologies from small tiled datasets to full granule evaluation. This revealed that deep learning models still produce a large number of false detections, a problem we address with model ensembling, which reduced false detections by over 74%. Deployed in the MARS pipeline, our system processes scenes and proposes plumes to analysts, accelerating the detection and analysis process. During seven months of operational deployment, it facilitated the verification of 1,351 distinct methane leaks, resulting in 479 stakeholder notifications. We further demonstrate the model's utility in verifying mitigation success through case studies in Libya, Argentina, Oman, and Azerbaijan. Our work represents a critical step towards a global AI-assisted methane leak detection system, which is required to process the dramatically higher data volumes expected from new and current imaging spectrometers.
Fast model inference and training on-board of Satellites
Jul 17, 2023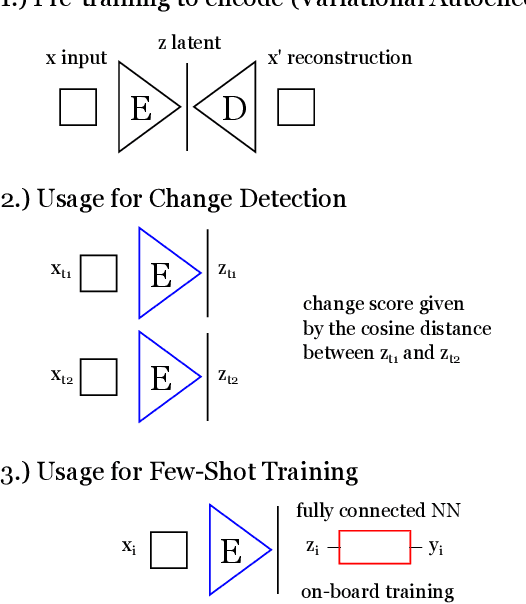
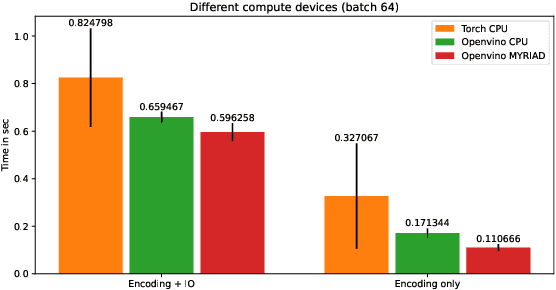
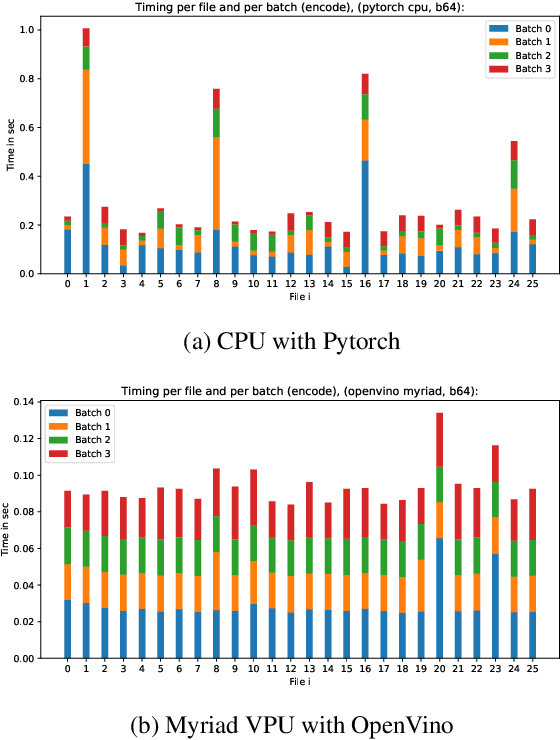
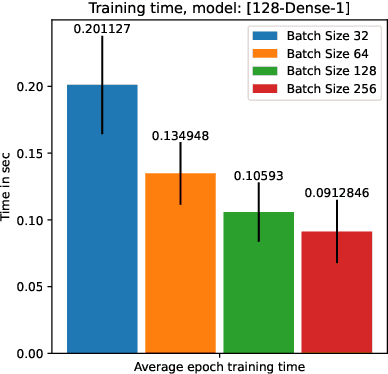
Artificial intelligence onboard satellites has the potential to reduce data transmission requirements, enable real-time decision-making and collaboration within constellations. This study deploys a lightweight foundational model called RaVAEn on D-Orbit's ION SCV004 satellite. RaVAEn is a variational auto-encoder (VAE) that generates compressed latent vectors from small image tiles, enabling several downstream tasks. In this work we demonstrate the reliable use of RaVAEn onboard a satellite, achieving an encoding time of 0.110s for tiles of a 4.8x4.8 km$^2$ area. In addition, we showcase fast few-shot training onboard a satellite using the latent representation of data. We compare the deployment of the model on the on-board CPU and on the available Myriad vision processing unit (VPU) accelerator. To our knowledge, this work shows for the first time the deployment of a multi-task model on-board a CubeSat and the on-board training of a machine learning model.
Convolutional Neural Networks for Multispectral Image Cloud Masking
Dec 09, 2020
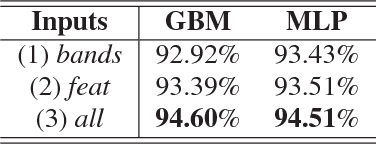

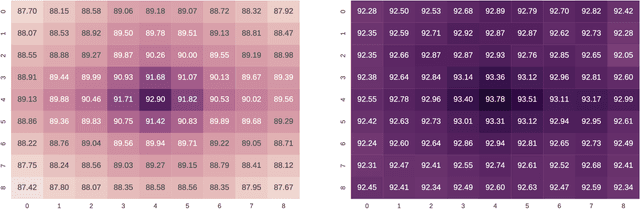
Convolutional neural networks (CNN) have proven to be state of the art methods for many image classification tasks and their use is rapidly increasing in remote sensing problems. One of their major strengths is that, when enough data is available, CNN perform an end-to-end learning without the need of custom feature extraction methods. In this work, we study the use of different CNN architectures for cloud masking of Proba-V multispectral images. We compare such methods with the more classical machine learning approach based on feature extraction plus supervised classification. Experimental results suggest that CNN are a promising alternative for solving cloud masking problems.
Cloud detection machine learning algorithms for PROBA-V
Dec 09, 2020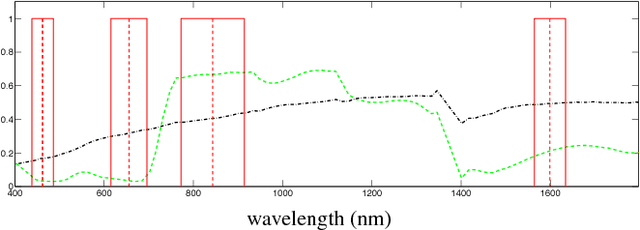
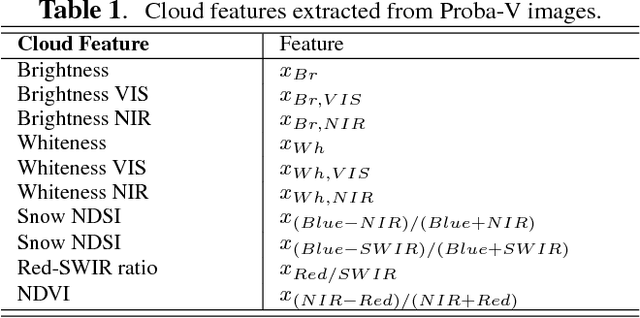
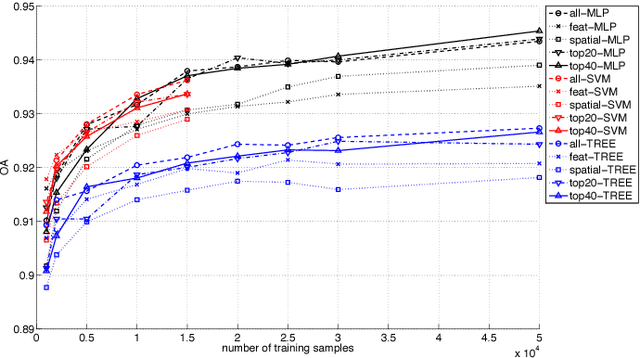

This paper presents the development and implementation of a cloud detection algorithm for Proba-V. Accurate and automatic detection of clouds in satellite scenes is a key issue for a wide range of remote sensing applications. With no accurate cloud masking, undetected clouds are one of the most significant sources of error in both sea and land cover biophysical parameter retrieval. The objective of the algorithms presented in this paper is to detect clouds accurately providing a cloud flag per pixel. For this purpose, the method exploits the information of Proba-V using statistical machine learning techniques to identify the clouds present in Proba-V products. The effectiveness of the proposed method is successfully illustrated using a large number of real Proba-V images.
Estimating Crop Primary Productivity with Sentinel-2 and Landsat 8 using Machine Learning Methods Trained with Radiative Transfer Simulations
Dec 07, 2020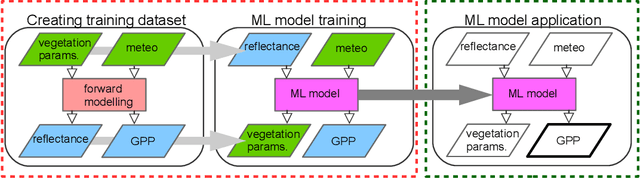
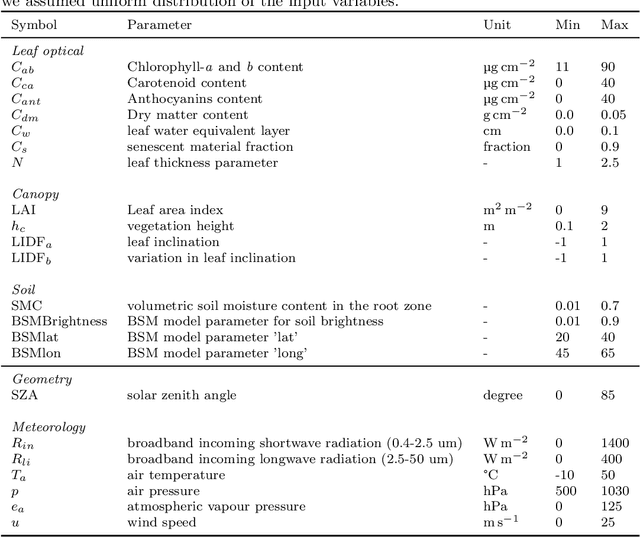
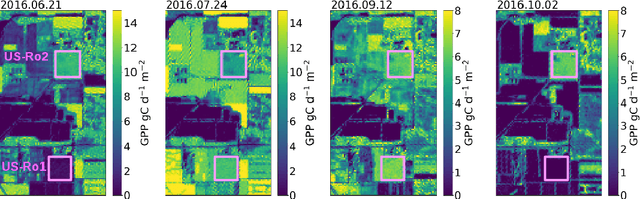
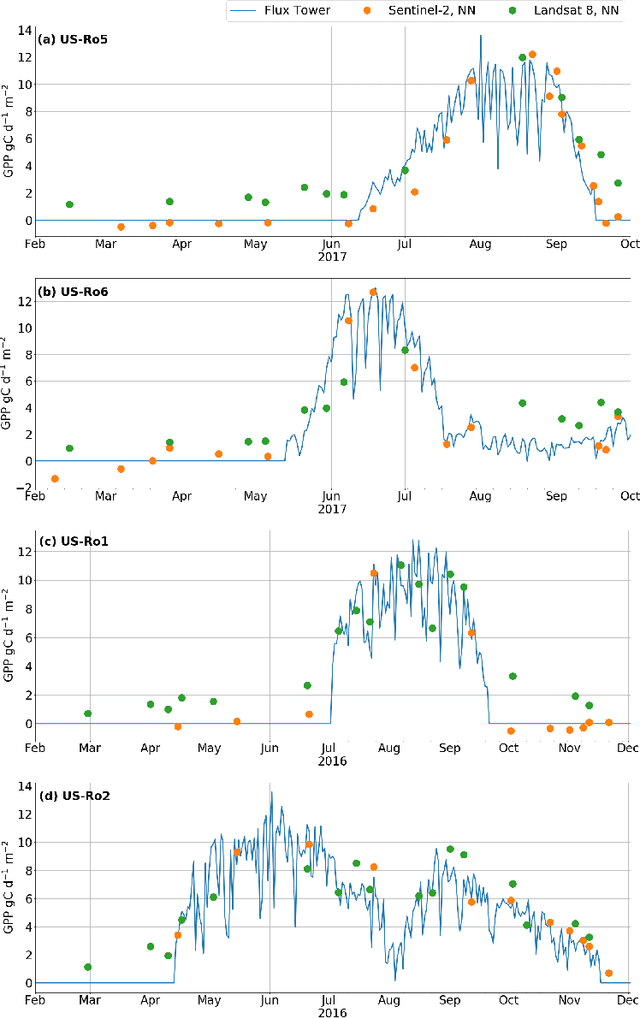
Satellite remote sensing has been widely used in the last decades for agricultural applications, {both for assessing vegetation condition and for subsequent yield prediction.} Existing remote sensing-based methods to estimate gross primary productivity (GPP), which is an important variable to indicate crop photosynthetic function and stress, typically rely on empirical or semi-empirical approaches, which tend to over-simplify photosynthetic mechanisms. In this work, we take advantage of all parallel developments in mechanistic photosynthesis modeling and satellite data availability for advanced monitoring of crop productivity. In particular, we combine process-based modeling with the soil-canopy energy balance radiative transfer model (SCOPE) with Sentinel-2 {and Landsat 8} optical remote sensing data and machine learning methods in order to estimate crop GPP. Our model successfully estimates GPP across a variety of C3 crop types and environmental conditions even though it does not use any local information from the corresponding sites. This highlights its potential to map crop productivity from new satellite sensors at a global scale with the help of current Earth observation cloud computing platforms.
Cross-Sensor Adversarial Domain Adaptation of Landsat-8 and Proba-V images for Cloud Detection
Jun 10, 2020
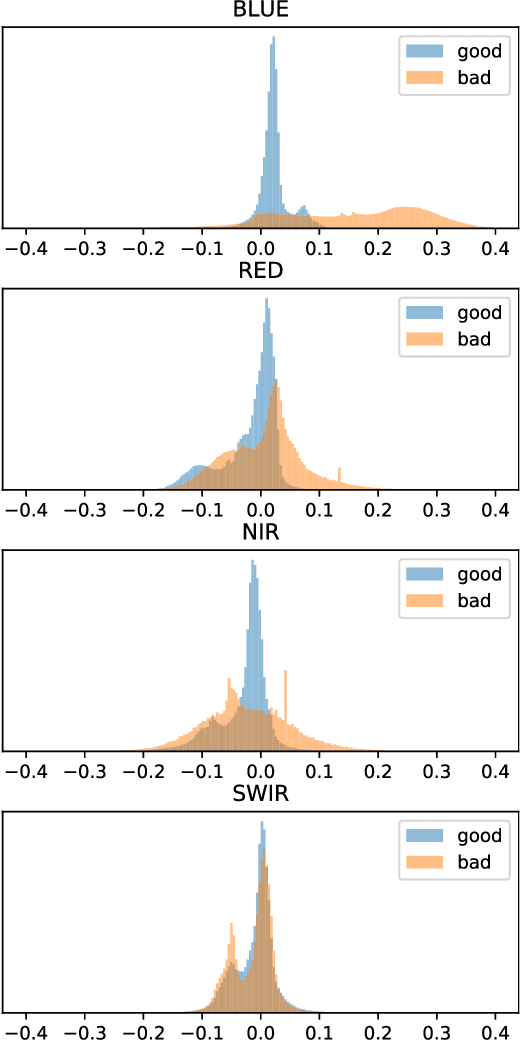

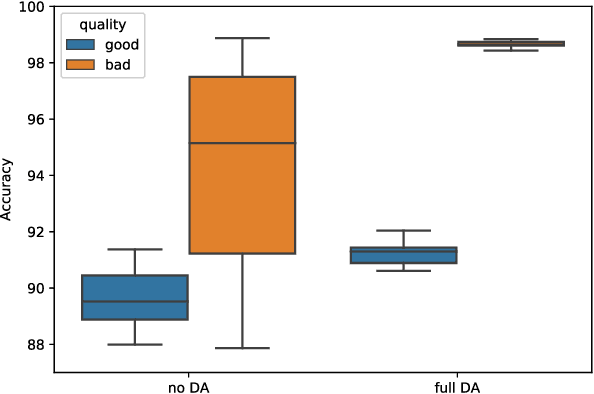
The number of Earth observation satellites carrying optical sensors with similar characteristics is constantly growing. Despite their similarities and the potential synergies among them, derived satellite products are often developed for each sensor independently. Differences in retrieved radiances lead to significant drops in accuracy, which hampers knowledge and information sharing across sensors. This is particularly harmful for machine learning algorithms, since gathering new ground truth data to train models for each sensor is costly and requires experienced manpower. In this work, we propose a domain adaptation transformation to reduce the statistical differences between images of two satellite sensors in order to boost the performance of transfer learning models. The proposed methodology is based on the Cycle Consistent Generative Adversarial Domain Adaptation (CyCADA) framework that trains the transformation model in an unpaired manner. In particular, Landsat-8 and Proba-V satellites, which present different but compatible spatio-spectral characteristics, are used to illustrate the method. The obtained transformation significantly reduces differences between the image datasets while preserving the spatial and spectral information of adapted images, which is hence useful for any general purpose cross-sensor application. In addition, the training of the proposed adversarial domain adaptation model can be modified to improve the performance in a specific remote sensing application, such as cloud detection, by including a dedicated term in the cost function. Results show that, when the proposed transformation is applied, cloud detection models trained in Landsat-8 data increase cloud detection accuracy in Proba-V.
Fair Kernel Learning
Oct 16, 2017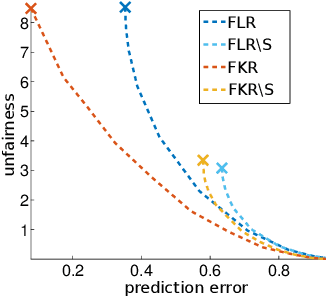
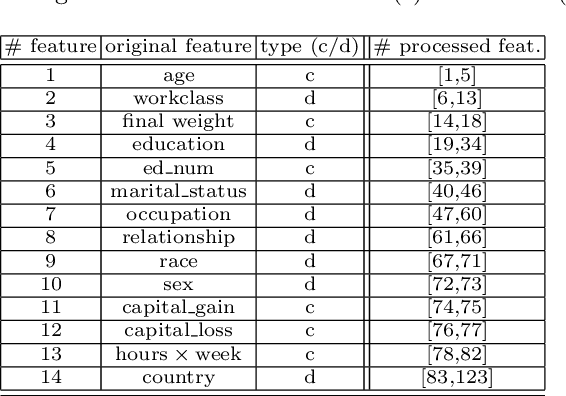
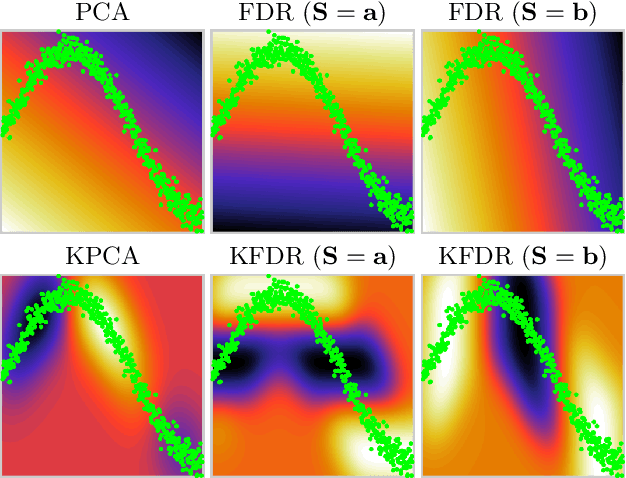
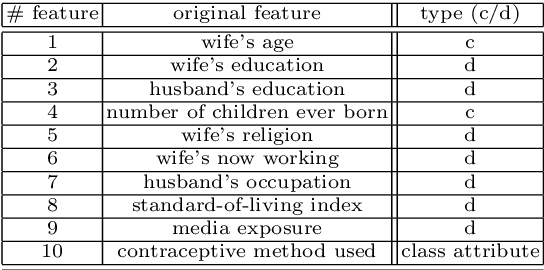
New social and economic activities massively exploit big data and machine learning algorithms to do inference on people's lives. Applications include automatic curricula evaluation, wage determination, and risk assessment for credits and loans. Recently, many governments and institutions have raised concerns about the lack of fairness, equity and ethics in machine learning to treat these problems. It has been shown that not including sensitive features that bias fairness, such as gender or race, is not enough to mitigate the discrimination when other related features are included. Instead, including fairness in the objective function has been shown to be more efficient. We present novel fair regression and dimensionality reduction methods built on a previously proposed fair classification framework. Both methods rely on using the Hilbert Schmidt independence criterion as the fairness term. Unlike previous approaches, this allows us to simplify the problem and to use multiple sensitive variables simultaneously. Replacing the linear formulation by kernel functions allows the methods to deal with nonlinear problems. For both linear and nonlinear formulations the solution reduces to solving simple matrix inversions or generalized eigenvalue problems. This simplifies the evaluation of the solutions for different trade-off values between the predictive error and fairness terms. We illustrate the usefulness of the proposed methods in toy examples, and evaluate their performance on real world datasets to predict income using gender and/or race discrimination as sensitive variables, and contraceptive method prediction under demographic and socio-economic sensitive descriptors.