 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor Names in Vision-Language Models
Sep 26, 2025Color serves as a fundamental dimension of human visual perception and a primary means of communicating about objects and scenes. As vision-language models (VLMs) become increasingly prevalent, understanding whether they name colors like humans is crucial for effective human-AI interaction. We present the first systematic evaluation of color naming capabilities across VLMs, replicating classic color naming methodologies using 957 color samples across five representative models. Our results show that while VLMs achieve high accuracy on prototypical colors from classical studies, performance drops significantly on expanded, non-prototypical color sets. We identify 21 common color terms that consistently emerge across all models, revealing two distinct approaches: constrained models using predominantly basic terms versus expansive models employing systematic lightness modifiers. Cross-linguistic analysis across nine languages demonstrates severe training imbalances favoring English and Chinese, with hue serving as the primary driver of color naming decisions. Finally, ablation studies reveal that language model architecture significantly influences color naming independent of visual processing capabilities.
Contrast Sensitivity Function of Multimodal Vision-Language Models
Aug 14, 2025Assessing the alignment of multimodal vision-language models~(VLMs) with human perception is essential to understand how they perceive low-level visual features. A key characteristic of human vision is the contrast sensitivity function (CSF), which describes sensitivity to spatial frequency at low-contrasts. Here, we introduce a novel behavioral psychophysics-inspired method to estimate the CSF of chat-based VLMs by directly prompting them to judge pattern visibility at different contrasts for each frequency. This methodology is closer to the real experiments in psychophysics than the previously reported. Using band-pass filtered noise images and a diverse set of prompts, we assess model responses across multiple architectures. We find that while some models approximate human-like CSF shape or magnitude, none fully replicate both. Notably, prompt phrasing has a large effect on the responses, raising concerns about prompt stability. Our results provide a new framework for probing visual sensitivity in multimodal models and reveal key gaps between their visual representations and human perception.
RAID-Database: human Responses to Affine Image Distortions
Dec 13, 2024


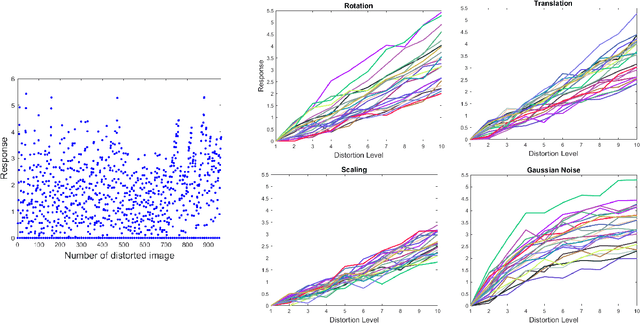
Image quality databases are used to train models for predicting subjective human perception. However, most existing databases focus on distortions commonly found in digital media and not in natural conditions. Affine transformations are particularly relevant to study, as they are among the most commonly encountered by human observers in everyday life. This Data Descriptor presents a set of human responses to suprathreshold affine image transforms (rotation, translation, scaling) and Gaussian noise as convenient reference to compare with previously existing image quality databases. The responses were measured using well established psychophysics: the Maximum Likelihood Difference Scaling method. The set contains responses to 864 distorted images. The experiments involved 105 observers and more than 20000 comparisons of quadruples of images. The quality of the dataset is ensured because (a) it reproduces the classical Pi\'eron's law, (b) it reproduces classical absolute detection thresholds, and (c) it is consistent with conventional image quality databases but improves them according to Group-MAD experiments.
Parametric Enhancement of PerceptNet: A Human-Inspired Approach for Image Quality Assessment
Dec 04, 2024



While deep learning models can learn human-like features at earlier levels, which suggests their utility in modeling human vision, few attempts exist to incorporate these features by design. Current approaches mostly optimize all parameters blindly, only constraining minor architectural aspects. This paper demonstrates how parametrizing neural network layers enables more biologically-plausible operations while reducing trainable parameters and improving interpretability. We constrain operations to functional forms present in human vision, optimizing only these functions' parameters rather than all convolutional tensor elements independently. We present two parametric model versions: one with hand-chosen biologically plausible parameters, and another fitted to human perception experimental data. We compare these with a non-parametric version. All models achieve comparable state-of-the-art results, with parametric versions showing orders of magnitude parameter reduction for minimal performance loss. The parametric models demonstrate improved interpretability and training behavior. Notably, the model fitted to human perception, despite biological initialization, converges to biologically incorrect results. This raises scientific questions and highlights the need for diverse evaluation methods to measure models' humanness, rather than assuming task performance correlates with human-like behavior.
The Effect of Perceptual Metrics on Music Representation Learning for Genre Classification
Sep 25, 2024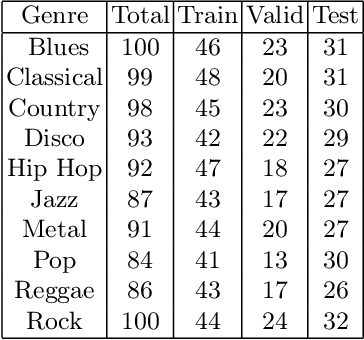
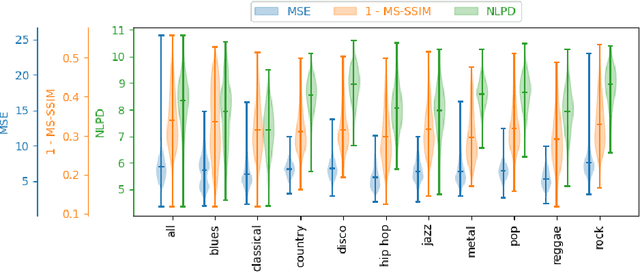
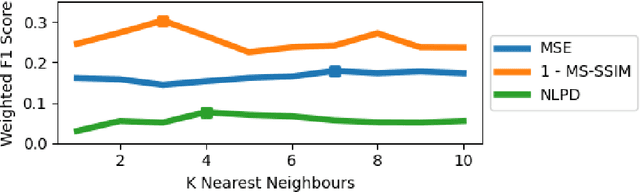
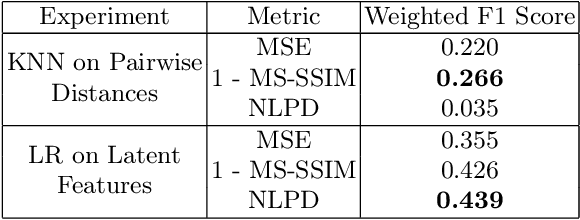
The subjective quality of natural signals can be approximated with objective perceptual metrics. Designed to approximate the perceptual behaviour of human observers, perceptual metrics often reflect structures found in natural signals and neurological pathways. Models trained with perceptual metrics as loss functions can capture perceptually meaningful features from the structures held within these metrics. We demonstrate that using features extracted from autoencoders trained with perceptual losses can improve performance on music understanding tasks, i.e. genre classification, over using these metrics directly as distances when learning a classifier. This result suggests improved generalisation to novel signals when using perceptual metrics as loss functions for representation learning.
Invariance of deep image quality metrics to affine transformations
Jul 29, 2024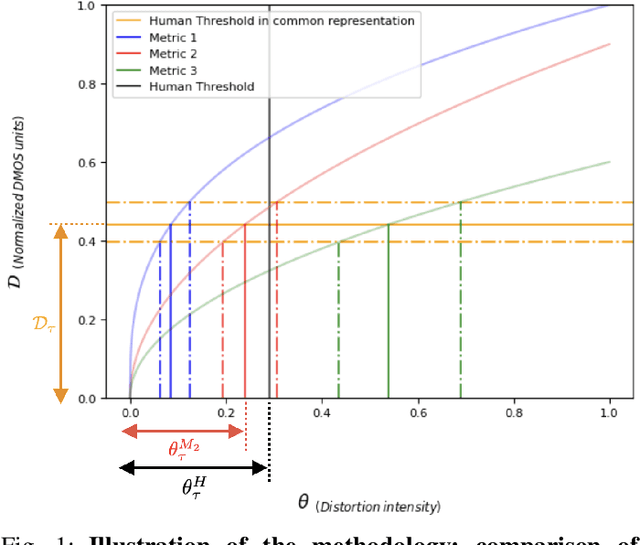


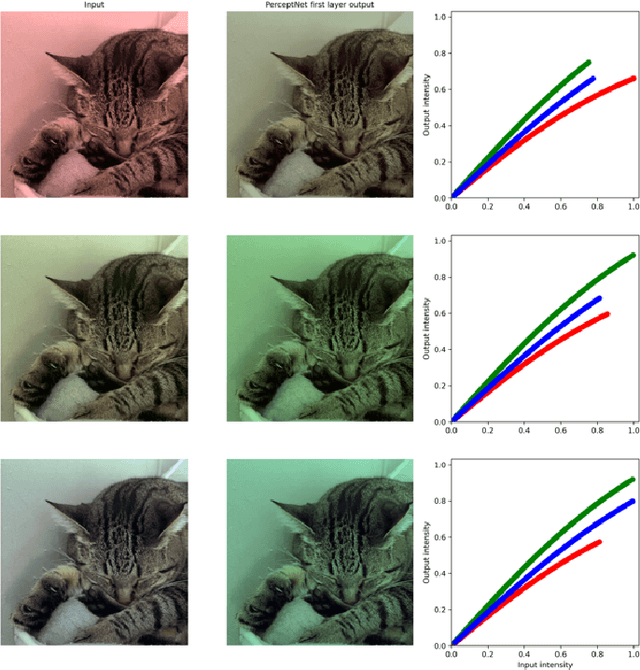
Deep architectures are the current state-of-the-art in predicting subjective image quality. Usually, these models are evaluated according to their ability to correlate with human opinion in databases with a range of distortions that may appear in digital media. However, these oversee affine transformations which may represent better the changes in the images actually happening in natural conditions. Humans can be particularly invariant to these natural transformations, as opposed to the digital ones. In this work, we evaluate state-of-the-art deep image quality metrics by assessing their invariance to affine transformations, specifically: rotation, translation, scaling, and changes in spectral illumination. Here invariance of a metric refers to the fact that certain distances should be neglected (considered to be zero) if their values are below a threshold. This is what we call invisibility threshold of a metric. We propose a methodology to assign such invisibility thresholds for any perceptual metric. This methodology involves transformations to a distance space common to any metric, and psychophysical measurements of thresholds in this common space. By doing so, we allow the analyzed metrics to be directly comparable with actual human thresholds. We find that none of the state-of-the-art metrics shows human-like results under this strong test based on invisibility thresholds. This means that tuning the models exclusively to predict the visibility of generic distortions may disregard other properties of human vision as for instance invariances or invisibility thresholds.
Image Segmentation via Divisive Normalization: dealing with environmental diversity
Jul 25, 2024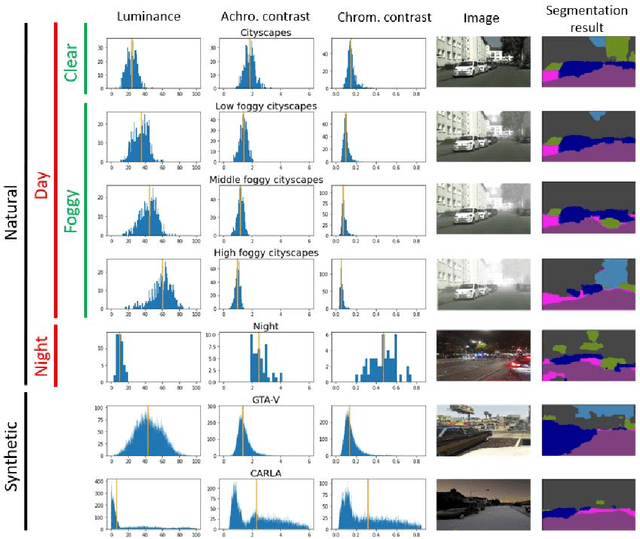

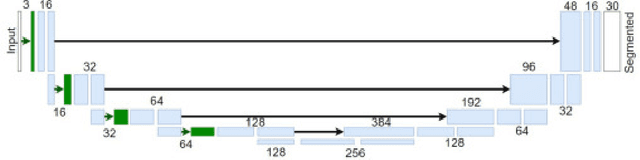

Autonomous driving is a challenging scenario for image segmentation due to the presence of uncontrolled environmental conditions and the eventually catastrophic consequences of failures. Previous work suggested that a biologically motivated computation, the so-called Divisive Normalization, could be useful to deal with image variability, but its effects have not been systematically studied over different data sources and environmental factors. Here we put segmentation U-nets augmented with Divisive Normalization to work far from training conditions to find where this adaptation is more critical. We categorize the scenes according to their radiance level and dynamic range (day/night), and according to their achromatic/chromatic contrasts. We also consider video game (synthetic) images to broaden the range of environments. We check the performance in the extreme percentiles of such categorization. Then, we push the limits further by artificially modifying the images in perceptually/environmentally relevant dimensions: luminance, contrasts and spectral radiance. Results show that neural networks with Divisive Normalization get better results in all the scenarios and their performance remains more stable with regard to the considered environmental factors and nature of the source. Finally, we explain the improvements in segmentation performance in two ways: (1) by quantifying the invariance of the responses that incorporate Divisive Normalization, and (2) by illustrating the adaptive nonlinearity of the different layers that depends on the local activity.
Data is Overrated: Perceptual Metrics Can Lead Learning in the Absence of Training Data
Dec 06, 2023

Perceptual metrics are traditionally used to evaluate the quality of natural signals, such as images and audio. They are designed to mimic the perceptual behaviour of human observers and usually reflect structures found in natural signals. This motivates their use as loss functions for training generative models such that models will learn to capture the structure held in the metric. We take this idea to the extreme in the audio domain by training a compressive autoencoder to reconstruct uniform noise, in lieu of natural data. We show that training with perceptual losses improves the reconstruction of spectrograms and re-synthesized audio at test time over models trained with a standard Euclidean loss. This demonstrates better generalisation to unseen natural signals when using perceptual metrics.
What You Hear Is What You See: Audio Quality Metrics From Image Quality Metrics
May 19, 2023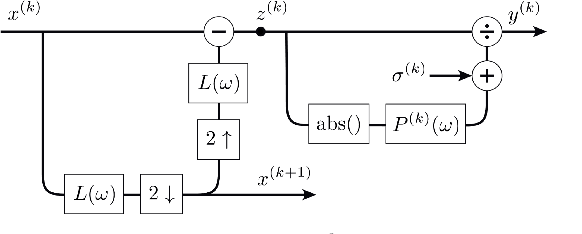


In this study, we investigate the feasibility of utilizing state-of-the-art image perceptual metrics for evaluating audio signals by representing them as spectrograms. The encouraging outcome of the proposed approach is based on the similarity between the neural mechanisms in the auditory and visual pathways. Furthermore, we customise one of the metrics which has a psychoacoustically plausible architecture to account for the peculiarities of sound signals. We evaluate the effectiveness of our proposed metric and several baseline metrics using a music dataset, with promising results in terms of the correlation between the metrics and the perceived quality of audio as rated by human evaluators.
Disentangling the Link Between Image Statistics and Human Perception
Mar 17, 2023
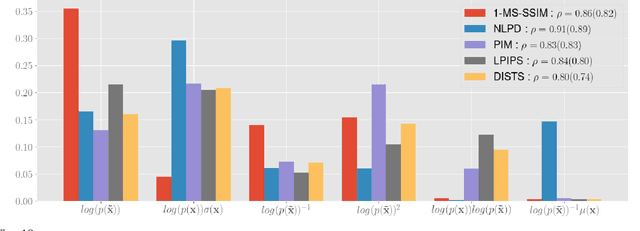
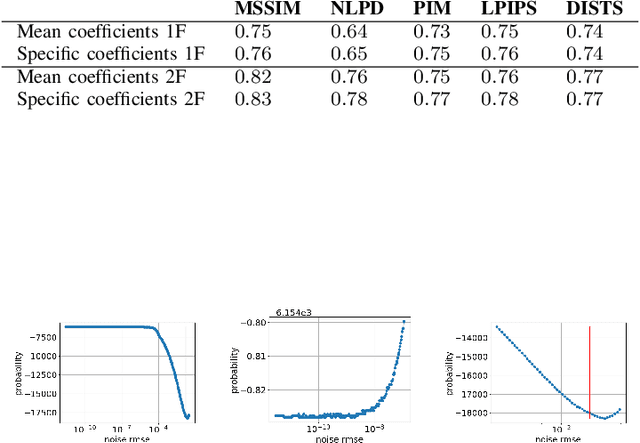

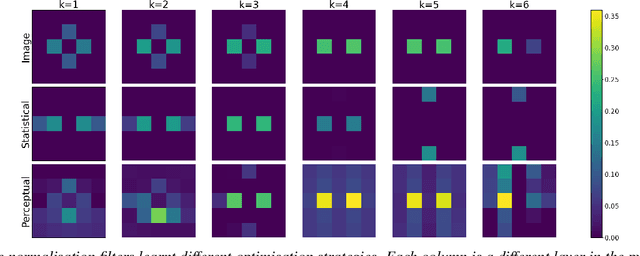
In the 1950s Horace Barlow and Fred Attneave suggested a connection between sensory systems and how they are adapted to the environment: early vision evolved to maximise the information it conveys about incoming signals. Following Shannon's definition, this information was described using the probability of the images taken from natural scenes. Previously, direct accurate predictions of image probabilities were not possible due to computational limitations. Despite the exploration of this idea being indirect, mainly based on oversimplified models of the image density or on system design methods, these methods had success in reproducing a wide range of physiological and psychophysical phenomena. In this paper, we directly evaluate the probability of natural images and analyse how it may determine perceptual sensitivity. We employ image quality metrics that correlate well with human opinion as a surrogate of human vision, and an advanced generative model to directly estimate the probability. Specifically, we analyse how the sensitivity of full-reference image quality metrics can be predicted from quantities derived directly from the probability distribution of natural images. First, we compute the mutual information between a wide range of probability surrogates and the sensitivity of the metrics and find that the most influential factor is the probability of the noisy image. Then we explore how these probability surrogates can be combined using a simple model to predict the metric sensitivity, giving an upper bound for the correlation of 0.85 between the model predictions and the actual perceptual sensitivity. Finally, we explore how to combine the probability surrogates using simple expressions, and obtain two functional forms (using one or two surrogates) that can be used to predict the sensitivity of the human visual system given a particular pair of images.