 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariance of deep image quality metrics to affine transformations
Jul 29, 2024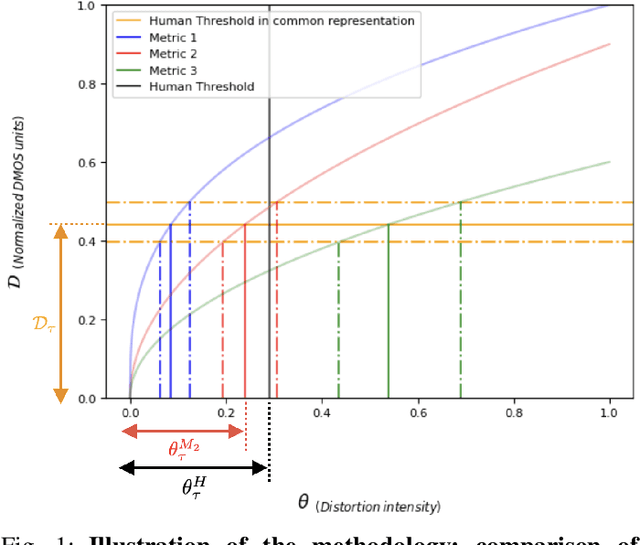


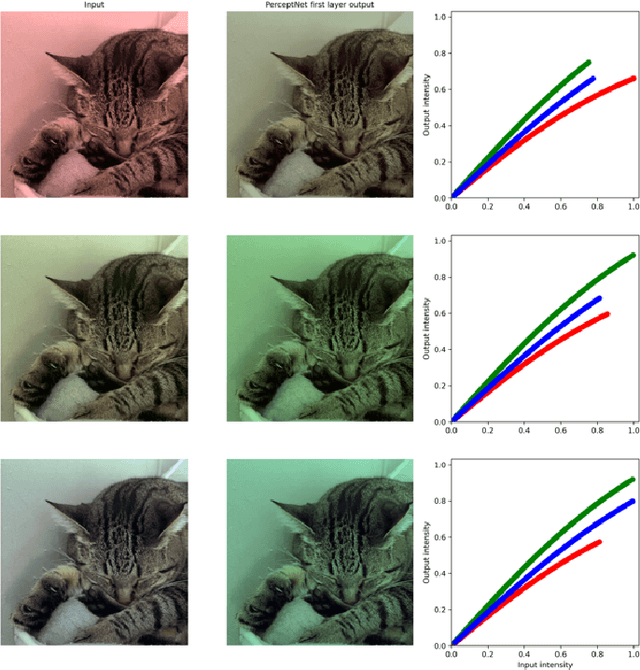
Deep architectures are the current state-of-the-art in predicting subjective image quality. Usually, these models are evaluated according to their ability to correlate with human opinion in databases with a range of distortions that may appear in digital media. However, these oversee affine transformations which may represent better the changes in the images actually happening in natural conditions. Humans can be particularly invariant to these natural transformations, as opposed to the digital ones. In this work, we evaluate state-of-the-art deep image quality metrics by assessing their invariance to affine transformations, specifically: rotation, translation, scaling, and changes in spectral illumination. Here invariance of a metric refers to the fact that certain distances should be neglected (considered to be zero) if their values are below a threshold. This is what we call invisibility threshold of a metric. We propose a methodology to assign such invisibility thresholds for any perceptual metric. This methodology involves transformations to a distance space common to any metric, and psychophysical measurements of thresholds in this common space. By doing so, we allow the analyzed metrics to be directly comparable with actual human thresholds. We find that none of the state-of-the-art metrics shows human-like results under this strong test based on invisibility thresholds. This means that tuning the models exclusively to predict the visibility of generic distortions may disregard other properties of human vision as for instance invariances or invisibility thresholds.
Image Segmentation via Divisive Normalization: dealing with environmental diversity
Jul 25, 2024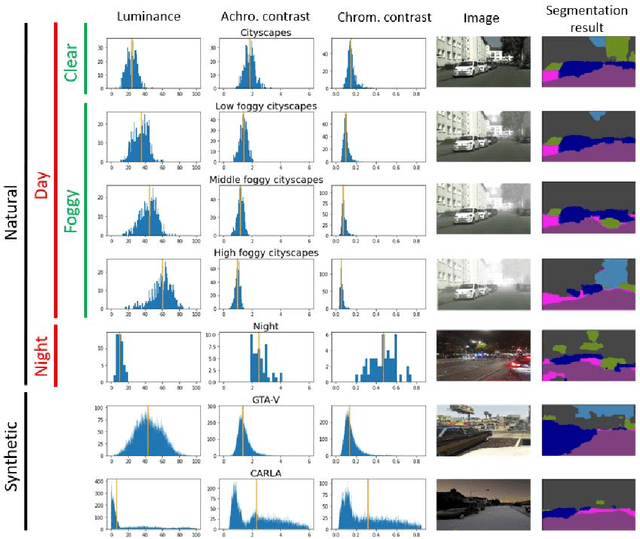

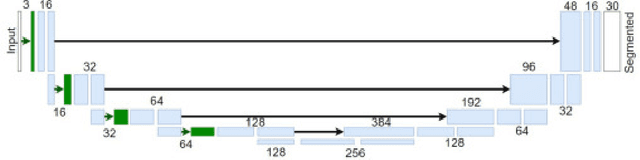

Autonomous driving is a challenging scenario for image segmentation due to the presence of uncontrolled environmental conditions and the eventually catastrophic consequences of failures. Previous work suggested that a biologically motivated computation, the so-called Divisive Normalization, could be useful to deal with image variability, but its effects have not been systematically studied over different data sources and environmental factors. Here we put segmentation U-nets augmented with Divisive Normalization to work far from training conditions to find where this adaptation is more critical. We categorize the scenes according to their radiance level and dynamic range (day/night), and according to their achromatic/chromatic contrasts. We also consider video game (synthetic) images to broaden the range of environments. We check the performance in the extreme percentiles of such categorization. Then, we push the limits further by artificially modifying the images in perceptually/environmentally relevant dimensions: luminance, contrasts and spectral radiance. Results show that neural networks with Divisive Normalization get better results in all the scenarios and their performance remains more stable with regard to the considered environmental factors and nature of the source. Finally, we explain the improvements in segmentation performance in two ways: (1) by quantifying the invariance of the responses that incorporate Divisive Normalization, and (2) by illustrating the adaptive nonlinearity of the different layers that depends on the local activity.