 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Deep Image Quality Models
Paper and Code
Feb 26, 2023


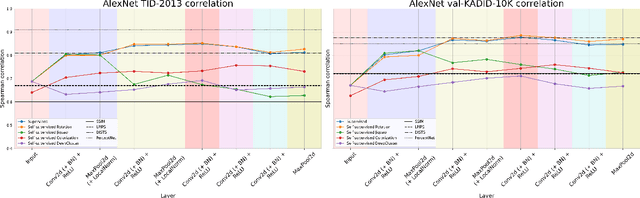
Subjective image quality measures based on deep neural networks are very related to models of visual neuroscience. This connection benefits engineering but, more interestingly, the freedom to optimize deep networks in different ways, make them an excellent tool to explore the principles behind visual perception (both human and artificial). Recently, a myriad of networks have been successfully optimized for many interesting visual tasks. Although these nets were not specifically designed to predict image quality or other psychophysics, they have shown surprising human-like behavior. The reasons for this remain unclear. In this work, we perform a thorough analysis of the perceptual properties of pre-trained nets (particularly their ability to predict image quality) by isolating different factors: the goal (the function), the data (learning environment), the architecture, and the readout: selected layer(s), fine-tuning of channel relevance, and use of statistical descriptors as opposed to plain readout of responses. Several conclusions can be drawn. All the models correlate better with human opinion than SSIM. More importantly, some of the nets are in pair of state-of-the-art with no extra refinement or perceptual information. Nets trained for supervised tasks such as classification correlate substantially better with humans than LPIPS (a net specifically tuned for image quality). Interestingly, self-supervised tasks such as jigsaw also perform better than LPIPS. Simpler architectures are better than very deep nets. In simpler nets, correlation with humans increases with depth as if deeper layers were closer to human judgement. This is not true in very deep nets. Consistently with reports on illusions and contrast sensitivity, small changes in the image environment does not make a big difference. Finally, the explored statistical descriptors and concatenations had no major impact.