 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSR-SRGAN: A Flexible Super-Resolution Framework for Multispectral Earth Observation Data
Nov 13, 2025We present OpenSR-SRGAN, an open and modular framework for single-image super-resolution in Earth Observation. The software provides a unified implementation of SRGAN-style models that is easy to configure, extend, and apply to multispectral satellite data such as Sentinel-2. Instead of requiring users to modify model code, OpenSR-SRGAN exposes generators, discriminators, loss functions, and training schedules through concise configuration files, making it straightforward to switch between architectures, scale factors, and band setups. The framework is designed as a practical tool and benchmark implementation rather than a state-of-the-art model. It ships with ready-to-use configurations for common remote sensing scenarios, sensible default settings for adversarial training, and built-in hooks for logging, validation, and large-scene inference. By turning GAN-based super-resolution into a configuration-driven workflow, OpenSR-SRGAN lowers the entry barrier for researchers and practitioners who wish to experiment with SRGANs, compare models in a reproducible way, and deploy super-resolution pipelines across diverse Earth-observation datasets.
Multi-Spectral Multi-Image Super-Resolution of Sentinel-2 with Radiometric Consistency Losses and Its Effect on Building Delineation
Nov 05, 2021
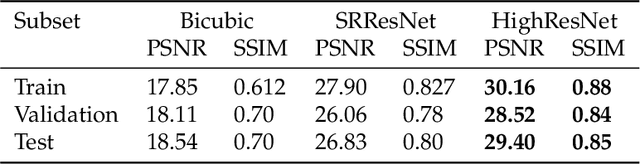
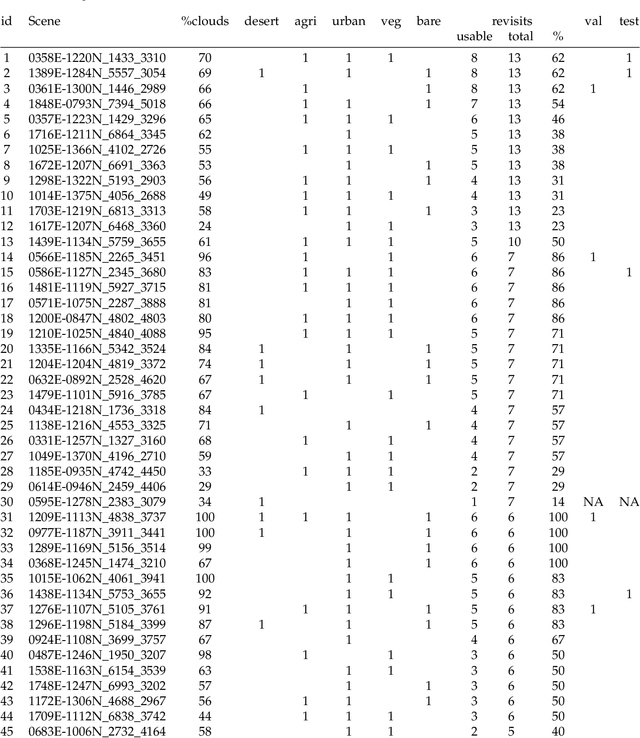
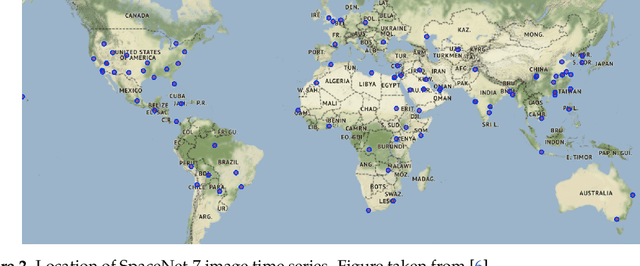
High resolution remote sensing imagery is used in broad range of tasks, including detection and classification of objects. High-resolution imagery is however expensive, while lower resolution imagery is often freely available and can be used by the public for range of social good applications. To that end, we curate a multi-spectral multi-image super-resolution dataset, using PlanetScope imagery from the SpaceNet 7 challenge as the high resolution reference and multiple Sentinel-2 revisits of the same imagery as the low-resolution imagery. We present the first results of applying multi-image super-resolution (MISR) to multi-spectral remote sensing imagery. We, additionally, introduce a radiometric consistency module into MISR model the to preserve the high radiometric resolution of the Sentinel-2 sensor. We show that MISR is superior to single-image super-resolution and other baselines on a range of image fidelity metrics. Furthermore, we conduct the first assessment of the utility of multi-image super-resolution on building delineation, showing that utilising multiple images results in better performance in these downstream tasks.
Convolutional Neural Networks for Multispectral Image Cloud Masking
Dec 09, 2020
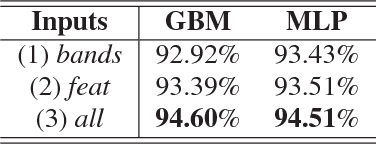

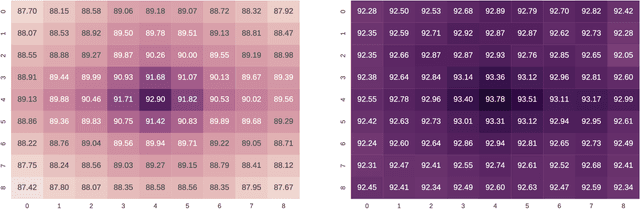
Convolutional neural networks (CNN) have proven to be state of the art methods for many image classification tasks and their use is rapidly increasing in remote sensing problems. One of their major strengths is that, when enough data is available, CNN perform an end-to-end learning without the need of custom feature extraction methods. In this work, we study the use of different CNN architectures for cloud masking of Proba-V multispectral images. We compare such methods with the more classical machine learning approach based on feature extraction plus supervised classification. Experimental results suggest that CNN are a promising alternative for solving cloud masking problems.
Cloud detection machine learning algorithms for PROBA-V
Dec 09, 2020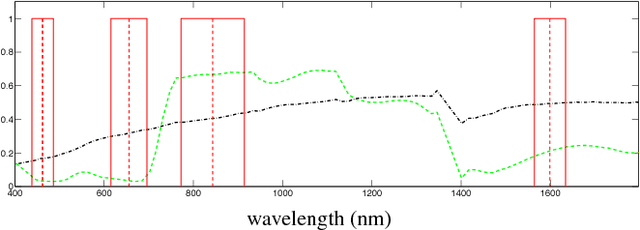
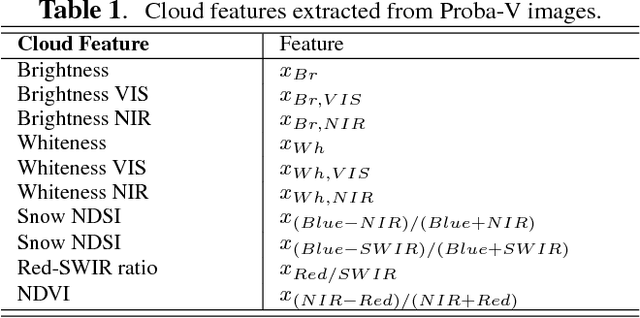
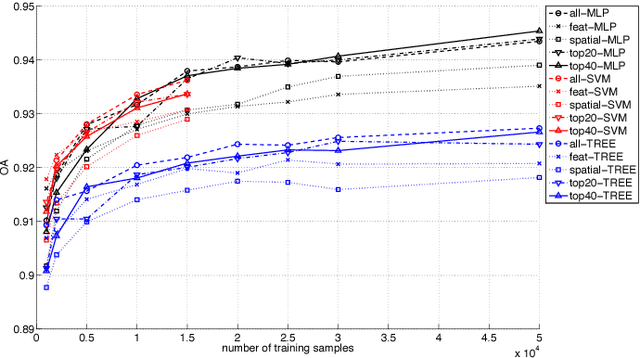

This paper presents the development and implementation of a cloud detection algorithm for Proba-V. Accurate and automatic detection of clouds in satellite scenes is a key issue for a wide range of remote sensing applications. With no accurate cloud masking, undetected clouds are one of the most significant sources of error in both sea and land cover biophysical parameter retrieval. The objective of the algorithms presented in this paper is to detect clouds accurately providing a cloud flag per pixel. For this purpose, the method exploits the information of Proba-V using statistical machine learning techniques to identify the clouds present in Proba-V products. The effectiveness of the proposed method is successfully illustrated using a large number of real Proba-V images.
Pattern Recognition Scheme for Large-Scale Cloud Detection over Landmarks
Dec 08, 2020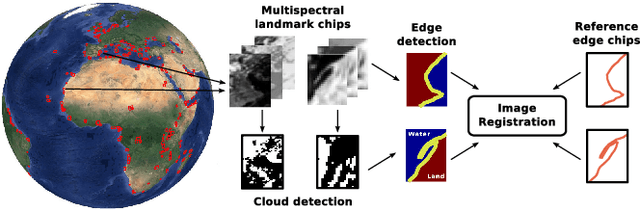

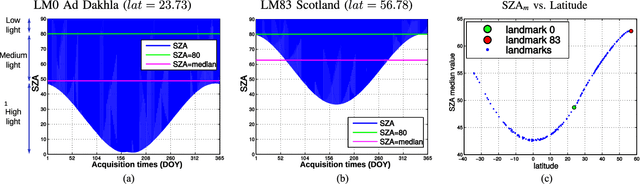

Landmark recognition and matching is a critical step in many Image Navigation and Registration (INR) models for geostationary satellite services, as well as to maintain the geometric quality assessment (GQA) in the instrument data processing chain of Earth observation satellites. Matching the landmark accurately is of paramount relevance, and the process can be strongly impacted by the cloud contamination of a given landmark. This paper introduces a complete pattern recognition methodology able to detect the presence of clouds over landmarks using Meteosat Second Generation (MSG) data. The methodology is based on the ensemble combination of dedicated support vector machines (SVMs) dependent on the particular landmark and illumination conditions. This divide-and-conquer strategy is motivated by the data complexity and follows a physically-based strategy that considers variability both in seasonality and illumination conditions along the day to split observations. In addition, it allows training the classification scheme with millions of samples at an affordable computational costs. The image archive was composed of 200 landmark test sites with near 7 million multispectral images that correspond to MSG acquisitions during 2010. Results are analyzed in terms of cloud detection accuracy and computational cost. We provide illustrative source code and a portion of the huge training data to the community.
Estimating Crop Primary Productivity with Sentinel-2 and Landsat 8 using Machine Learning Methods Trained with Radiative Transfer Simulations
Dec 07, 2020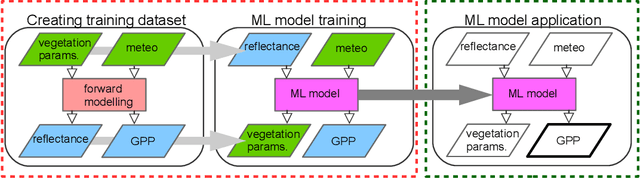
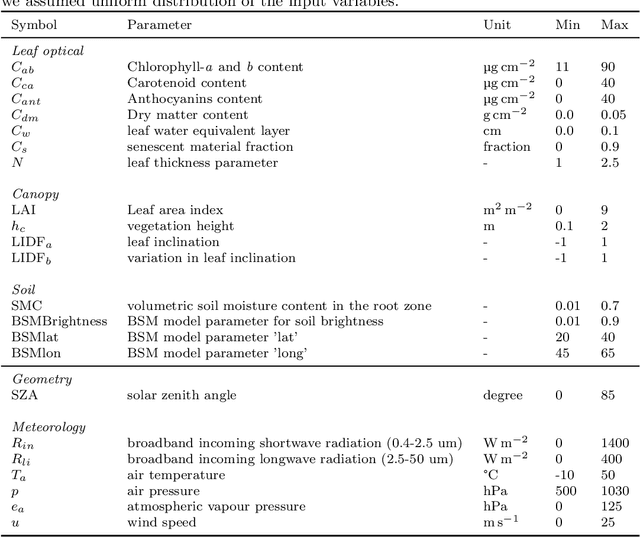
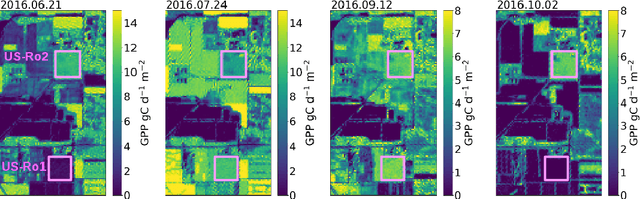
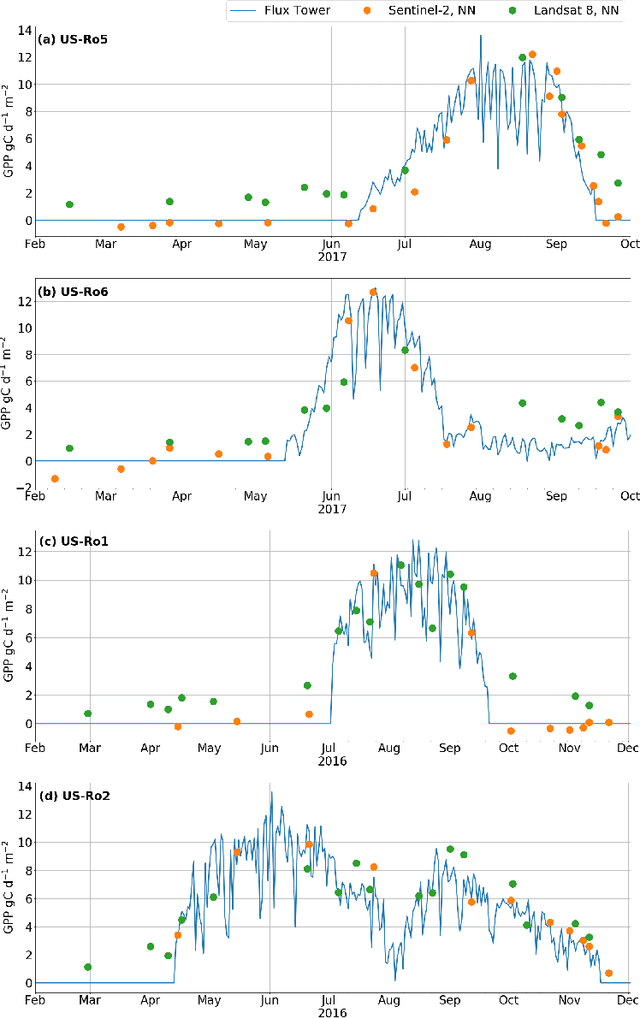
Satellite remote sensing has been widely used in the last decades for agricultural applications, {both for assessing vegetation condition and for subsequent yield prediction.} Existing remote sensing-based methods to estimate gross primary productivity (GPP), which is an important variable to indicate crop photosynthetic function and stress, typically rely on empirical or semi-empirical approaches, which tend to over-simplify photosynthetic mechanisms. In this work, we take advantage of all parallel developments in mechanistic photosynthesis modeling and satellite data availability for advanced monitoring of crop productivity. In particular, we combine process-based modeling with the soil-canopy energy balance radiative transfer model (SCOPE) with Sentinel-2 {and Landsat 8} optical remote sensing data and machine learning methods in order to estimate crop GPP. Our model successfully estimates GPP across a variety of C3 crop types and environmental conditions even though it does not use any local information from the corresponding sites. This highlights its potential to map crop productivity from new satellite sensors at a global scale with the help of current Earth observation cloud computing platforms.
Randomized kernels for large scale Earth observation applications
Dec 07, 2020Dealing with land cover classification of the new image sources has also turned to be a complex problem requiring large amount of memory and processing time. In order to cope with these problems, statistical learning has greatly helped in the last years to develop statistical retrieval and classification models that can ingest large amounts of Earth observation data. Kernel methods constitute a family of powerful machine learning algorithms, which have found wide use in remote sensing and geosciences. However, kernel methods are still not widely adopted because of the high computational cost when dealing with large scale problems, such as the inversion of radiative transfer models or the classification of high spatial-spectral-temporal resolution data. This paper introduces an efficient kernel method for fast statistical retrieval of bio-geo-physical parameters and image classification problems. The method allows to approximate a kernel matrix with a set of projections on random bases sampled from the Fourier domain. The method is simple, computationally very efficient in both memory and processing costs, and easily parallelizable. We show that kernel regression and classification is now possible for datasets with millions of examples and high dimensionality. Examples on atmospheric parameter retrieval from hyperspectral infrared sounders like IASI/Metop; large scale emulation and inversion of the familiar PROSAIL radiative transfer model on Sentinel-2 data; and the identification of clouds over landmarks in time series of MSG/Seviri images show the efficiency and effectiveness of the proposed technique.
Cross-Sensor Adversarial Domain Adaptation of Landsat-8 and Proba-V images for Cloud Detection
Jun 10, 2020
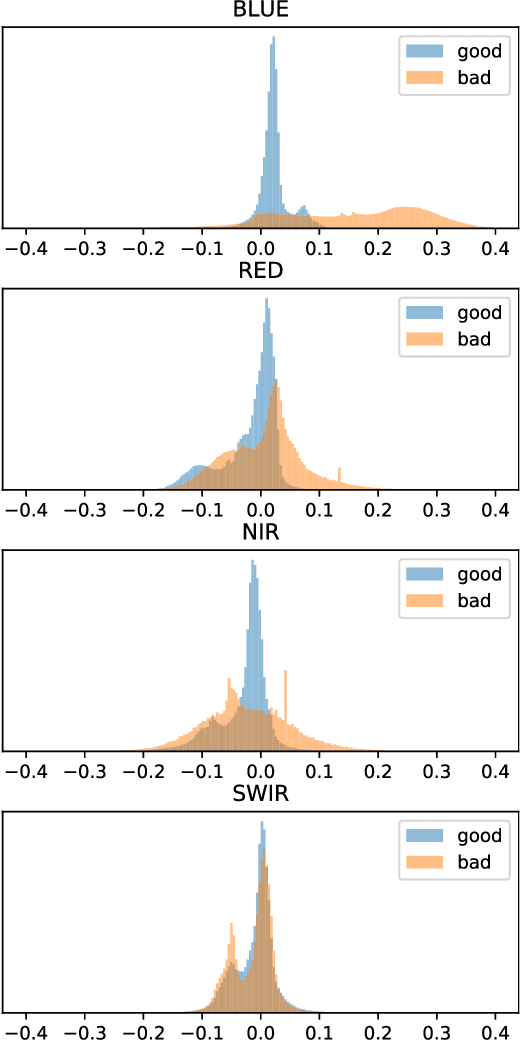

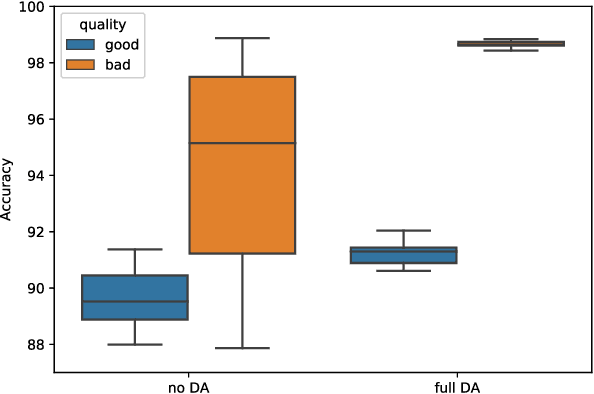
The number of Earth observation satellites carrying optical sensors with similar characteristics is constantly growing. Despite their similarities and the potential synergies among them, derived satellite products are often developed for each sensor independently. Differences in retrieved radiances lead to significant drops in accuracy, which hampers knowledge and information sharing across sensors. This is particularly harmful for machine learning algorithms, since gathering new ground truth data to train models for each sensor is costly and requires experienced manpower. In this work, we propose a domain adaptation transformation to reduce the statistical differences between images of two satellite sensors in order to boost the performance of transfer learning models. The proposed methodology is based on the Cycle Consistent Generative Adversarial Domain Adaptation (CyCADA) framework that trains the transformation model in an unpaired manner. In particular, Landsat-8 and Proba-V satellites, which present different but compatible spatio-spectral characteristics, are used to illustrate the method. The obtained transformation significantly reduces differences between the image datasets while preserving the spatial and spectral information of adapted images, which is hence useful for any general purpose cross-sensor application. In addition, the training of the proposed adversarial domain adaptation model can be modified to improve the performance in a specific remote sensing application, such as cloud detection, by including a dedicated term in the cost function. Results show that, when the proposed transformation is applied, cloud detection models trained in Landsat-8 data increase cloud detection accuracy in Proba-V.
Fair Kernel Learning
Oct 16, 2017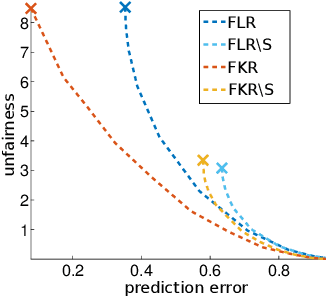
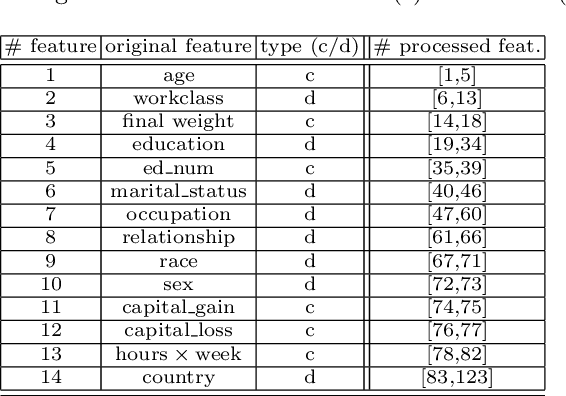
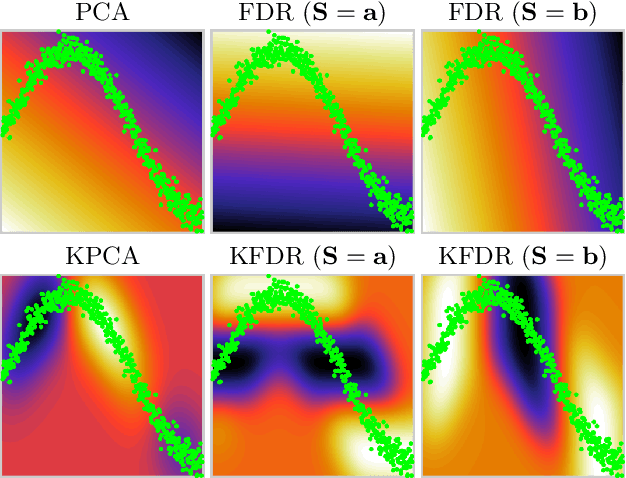
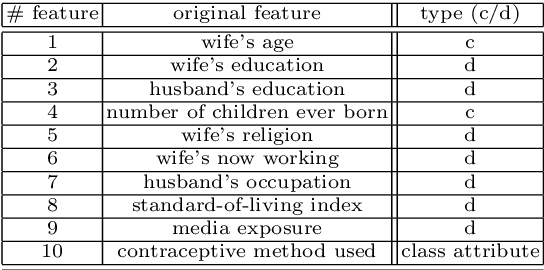
New social and economic activities massively exploit big data and machine learning algorithms to do inference on people's lives. Applications include automatic curricula evaluation, wage determination, and risk assessment for credits and loans. Recently, many governments and institutions have raised concerns about the lack of fairness, equity and ethics in machine learning to treat these problems. It has been shown that not including sensitive features that bias fairness, such as gender or race, is not enough to mitigate the discrimination when other related features are included. Instead, including fairness in the objective function has been shown to be more efficient. We present novel fair regression and dimensionality reduction methods built on a previously proposed fair classification framework. Both methods rely on using the Hilbert Schmidt independence criterion as the fairness term. Unlike previous approaches, this allows us to simplify the problem and to use multiple sensitive variables simultaneously. Replacing the linear formulation by kernel functions allows the methods to deal with nonlinear problems. For both linear and nonlinear formulations the solution reduces to solving simple matrix inversions or generalized eigenvalue problems. This simplifies the evaluation of the solutions for different trade-off values between the predictive error and fairness terms. We illustrate the usefulness of the proposed methods in toy examples, and evaluate their performance on real world datasets to predict income using gender and/or race discrimination as sensitive variables, and contraceptive method prediction under demographic and socio-economic sensitive descriptors.
Optimized Kernel Entropy Components
Mar 09, 2016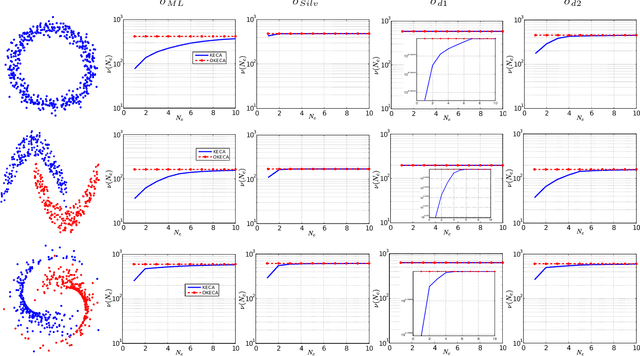


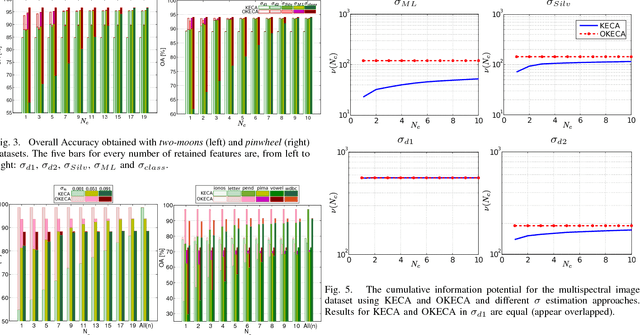
This work addresses two main issues of the standard Kernel Entropy Component Analysis (KECA) algorithm: the optimization of the kernel decomposition and the optimization of the Gaussian kernel parameter. KECA roughly reduces to a sorting of the importance of kernel eigenvectors by entropy instead of by variance as in Kernel Principal Components Analysis. In this work, we propose an extension of the KECA method, named Optimized KECA (OKECA), that directly extracts the optimal features retaining most of the data entropy by means of compacting the information in very few features (often in just one or two). The proposed method produces features which have higher expressive power. In particular, it is based on the Independent Component Analysis (ICA) framework, and introduces an extra rotation to the eigen-decomposition, which is optimized via gradient ascent search. This maximum entropy preservation suggests that OKECA features are more efficient than KECA features for density estimation. In addition, a critical issue in both methods is the selection of the kernel parameter since it critically affects the resulting performance. Here we analyze the most common kernel length-scale selection criteria. Results of both methods are illustrated in different synthetic and real problems. Results show that 1) OKECA returns projections with more expressive power than KECA, 2) the most successful rule for estimating the kernel parameter is based on maximum likelihood, and 3) OKECA is more robust to the selection of the length-scale parameter in kernel density estimation.