 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality Reduction for Remote Sensing Data Analysis: A Systematic Review of Methods and Applications
Oct 21, 2025Earth observation involves collecting, analyzing, and processing an ever-growing mass of data. Automatically harvesting information is crucial for addressing significant societal, economic, and environmental challenges, ranging from environmental monitoring to urban planning and disaster management. However, the high dimensionality of these data poses challenges in terms of sparsity, inefficiency, and the curse of dimensionality, which limits the effectiveness of machine learning models. Dimensionality reduction (DR) techniques, specifically feature extraction, address these challenges by preserving essential data properties while reducing complexity and enhancing tasks such as data compression, cleaning, fusion, visualization, anomaly detection, and prediction. This review provides a handbook for leveraging DR across the RS data value chain and identifies opportunities for under-explored DR algorithms and their application in future research.
Geospatial Foundation Models to Enable Progress on Sustainable Development Goals
May 30, 2025Foundation Models (FMs) are large-scale, pre-trained AI systems that have revolutionized natural language processing and computer vision, and are now advancing geospatial analysis and Earth Observation (EO). They promise improved generalization across tasks, scalability, and efficient adaptation with minimal labeled data. However, despite the rapid proliferation of geospatial FMs, their real-world utility and alignment with global sustainability goals remain underexplored. We introduce SustainFM, a comprehensive benchmarking framework grounded in the 17 Sustainable Development Goals with extremely diverse tasks ranging from asset wealth prediction to environmental hazard detection. This study provides a rigorous, interdisciplinary assessment of geospatial FMs and offers critical insights into their role in attaining sustainability goals. Our findings show: (1) While not universally superior, FMs often outperform traditional approaches across diverse tasks and datasets. (2) Evaluating FMs should go beyond accuracy to include transferability, generalization, and energy efficiency as key criteria for their responsible use. (3) FMs enable scalable, SDG-grounded solutions, offering broad utility for tackling complex sustainability challenges. Critically, we advocate for a paradigm shift from model-centric development to impact-driven deployment, and emphasize metrics such as energy efficiency, robustness to domain shifts, and ethical considerations.
A Collaborative Platform for Soil Organic Carbon Inference Based on Spatiotemporal Remote Sensing Data
Apr 17, 2025Soil organic carbon (SOC) is a key indicator of soil health, fertility, and carbon sequestration, making it essential for sustainable land management and climate change mitigation. However, large-scale SOC monitoring remains challenging due to spatial variability, temporal dynamics, and multiple influencing factors. We present WALGREEN, a platform that enhances SOC inference by overcoming limitations of current applications. Leveraging machine learning and diverse soil samples, WALGREEN generates predictive models using historical public and private data. Built on cloud-based technologies, it offers a user-friendly interface for researchers, policymakers, and land managers to access carbon data, analyze trends, and support evidence-based decision-making. Implemented in Python, Java, and JavaScript, WALGREEN integrates Google Earth Engine and Sentinel Copernicus via scripting, OpenLayers, and Thymeleaf in a Model-View-Controller framework. This paper aims to advance soil science, promote sustainable agriculture, and drive critical ecosystem responses to climate change.
Probabilistic Machine Learning for Noisy Labels in Earth Observation
Apr 04, 2025Label noise poses a significant challenge in Earth Observation (EO), often degrading the performance and reliability of supervised Machine Learning (ML) models. Yet, given the critical nature of several EO applications, developing robust and trustworthy ML solutions is essential. In this study, we take a step in this direction by leveraging probabilistic ML to model input-dependent label noise and quantify data uncertainty in EO tasks, accounting for the unique noise sources inherent in the domain. We train uncertainty-aware probabilistic models across a broad range of high-impact EO applications-spanning diverse noise sources, input modalities, and ML configurations-and introduce a dedicated pipeline to assess their accuracy and reliability. Our experimental results show that the uncertainty-aware models consistently outperform the standard deterministic approaches across most datasets and evaluation metrics. Moreover, through rigorous uncertainty evaluation, we validate the reliability of the predicted uncertainty estimates, enhancing the interpretability of model predictions. Our findings emphasize the importance of modeling label noise and incorporating uncertainty quantification in EO, paving the way for more accurate, reliable, and trustworthy ML solutions in the field.
On the Generalization of Representation Uncertainty in Earth Observation
Mar 10, 2025Recent advances in Computer Vision have introduced the concept of pretrained representation uncertainty, enabling zero-shot uncertainty estimation. This holds significant potential for Earth Observation (EO), where trustworthiness is critical, yet the complexity of EO data poses challenges to uncertainty-aware methods. In this work, we investigate the generalization of representation uncertainty in EO, considering the domain's unique semantic characteristics. We pretrain uncertainties on large EO datasets and propose an evaluation framework to assess their zero-shot performance in multi-label classification and segmentation EO tasks. Our findings reveal that, unlike uncertainties pretrained on natural images, EO-pretraining exhibits strong generalization across unseen EO domains, geographic locations, and target granularities, while maintaining sensitivity to variations in ground sampling distance. We demonstrate the practical utility of pretrained uncertainties showcasing their alignment with task-specific uncertainties in downstream tasks, their sensitivity to real-world EO image noise, and their ability to generate spatial uncertainty estimates out-of-the-box. Initiating the discussion on representation uncertainty in EO, our study provides insights into its strengths and limitations, paving the way for future research in the field. Code and weights are available at: https://github.com/Orion-AI-Lab/EOUncertaintyGeneralization.
Learning Causal Response Representations through Direct Effect Analysis
Mar 06, 2025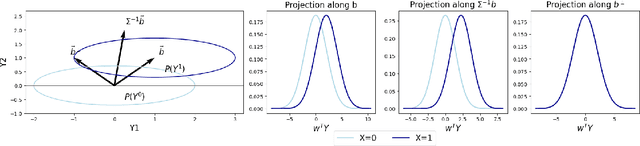

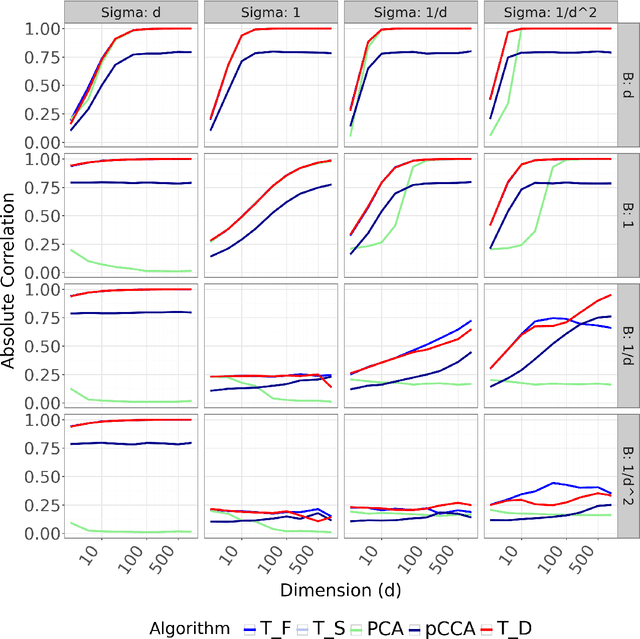

We propose a novel approach for learning causal response representations. Our method aims to extract directions in which a multidimensional outcome is most directly caused by a treatment variable. By bridging conditional independence testing with causal representation learning, we formulate an optimisation problem that maximises the evidence against conditional independence between the treatment and outcome, given a conditioning set. This formulation employs flexible regression models tailored to specific applications, creating a versatile framework. The problem is addressed through a generalised eigenvalue decomposition. We show that, under mild assumptions, the distribution of the largest eigenvalue can be bounded by a known $F$-distribution, enabling testable conditional independence. We also provide theoretical guarantees for the optimality of the learned representation in terms of signal-to-noise ratio and Fisher information maximisation. Finally, we demonstrate the empirical effectiveness of our approach in simulation and real-world experiments. Our results underscore the utility of this framework in uncovering direct causal effects within complex, multivariate settings.
UrbanSAM: Learning Invariance-Inspired Adapters for Segment Anything Models in Urban Construction
Feb 21, 2025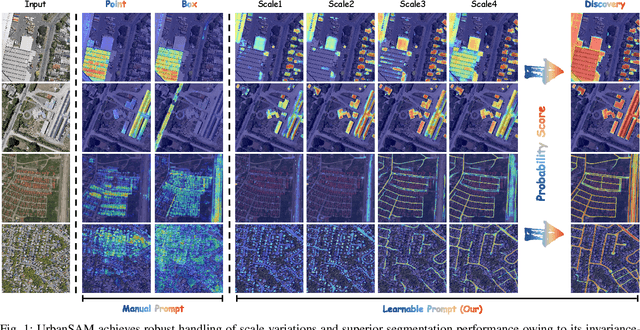
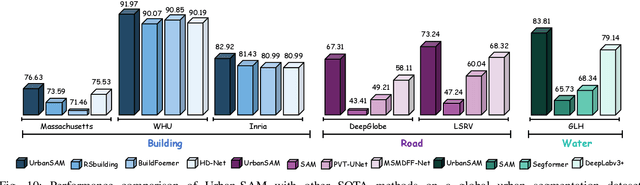
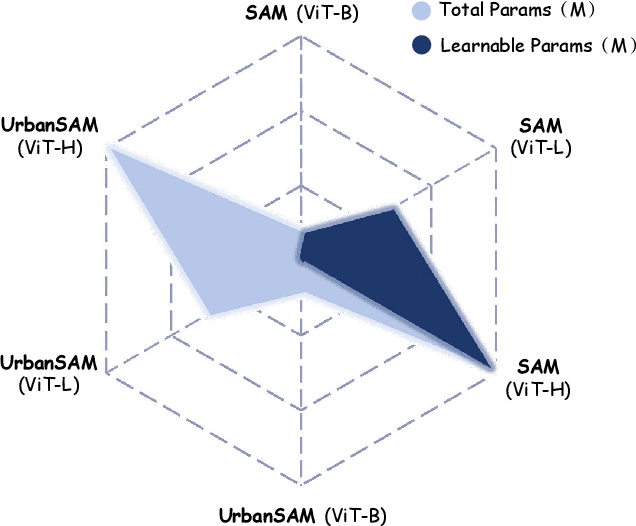
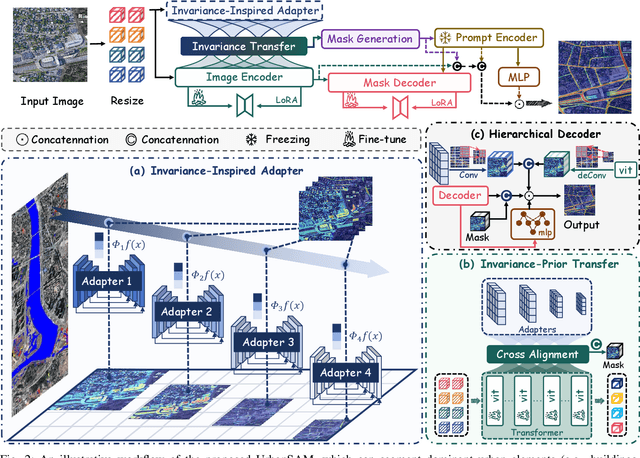
Object extraction and segmentation from remote sensing (RS) images is a critical yet challenging task in urban environment monitoring. Urban morphology is inherently complex, with irregular objects of diverse shapes and varying scales. These challenges are amplified by heterogeneity and scale disparities across RS data sources, including sensors, platforms, and modalities, making accurate object segmentation particularly demanding. While the Segment Anything Model (SAM) has shown significant potential in segmenting complex scenes, its performance in handling form-varying objects remains limited due to manual-interactive prompting. To this end, we propose UrbanSAM, a customized version of SAM specifically designed to analyze complex urban environments while tackling scaling effects from remotely sensed observations. Inspired by multi-resolution analysis (MRA) theory, UrbanSAM incorporates a novel learnable prompter equipped with a Uscaling-Adapter that adheres to the invariance criterion, enabling the model to capture multiscale contextual information of objects and adapt to arbitrary scale variations with theoretical guarantees. Furthermore, features from the Uscaling-Adapter and the trunk encoder are aligned through a masked cross-attention operation, allowing the trunk encoder to inherit the adapter's multiscale aggregation capability. This synergy enhances the segmentation performance, resulting in more powerful and accurate outputs, supported by the learned adapter. Extensive experimental results demonstrate the flexibility and superior segmentation performance of the proposed UrbanSAM on a global-scale dataset, encompassing scale-varying urban objects such as buildings, roads, and water.
A Flag Decomposition for Hierarchical Datasets
Feb 11, 2025Flag manifolds encode hierarchical nested sequences of subspaces and serve as powerful structures for various computer vision and machine learning applications. Despite their utility in tasks such as dimensionality reduction, motion averaging, and subspace clustering, current applications are often restricted to extracting flags using common matrix decomposition methods like the singular value decomposition. Here, we address the need for a general algorithm to factorize and work with hierarchical datasets. In particular, we propose a novel, flag-based method that decomposes arbitrary hierarchical real-valued data into a hierarchy-preserving flag representation in Stiefel coordinates. Our work harnesses the potential of flag manifolds in applications including denoising, clustering, and few-shot learning.
Explainable Earth Surface Forecasting under Extreme Events
Oct 02, 2024



With climate change-related extreme events on the rise, high dimensional Earth observation data presents a unique opportunity for forecasting and understanding impacts on ecosystems. This is, however, impeded by the complexity of processing, visualizing, modeling, and explaining this data. To showcase how this challenge can be met, here we train a convolutional long short-term memory-based architecture on the novel DeepExtremeCubes dataset. DeepExtremeCubes includes around 40,000 long-term Sentinel-2 minicubes (January 2016-October 2022) worldwide, along with labeled extreme events, meteorological data, vegetation land cover, and topography map, sampled from locations affected by extreme climate events and surrounding areas. When predicting future reflectances and vegetation impacts through kernel normalized difference vegetation index, the model achieved an R$^2$ score of 0.9055 in the test set. Explainable artificial intelligence was used to analyze the model's predictions during the October 2020 Central South America compound heatwave and drought event. We chose the same area exactly one year before the event as counterfactual, finding that the average temperature and surface pressure are generally the best predictors under normal conditions. In contrast, minimum anomalies of evaporation and surface latent heat flux take the lead during the event. A change of regime is also observed in the attributions before the event, which might help assess how long the event was brewing before happening. The code to replicate all experiments and figures in this paper is publicly available at https://github.com/DeepExtremes/txyXAI
Causal machine learning for sustainable agroecosystems
Aug 23, 2024

In a changing climate, sustainable agriculture is essential for food security and environmental health. However, it is challenging to understand the complex interactions among its biophysical, social, and economic components. Predictive machine learning (ML), with its capacity to learn from data, is leveraged in sustainable agriculture for applications like yield prediction and weather forecasting. Nevertheless, it cannot explain causal mechanisms and remains descriptive rather than prescriptive. To address this gap, we propose causal ML, which merges ML's data processing with causality's ability to reason about change. This facilitates quantifying intervention impacts for evidence-based decision-making and enhances predictive model robustness. We showcase causal ML through eight diverse applications that benefit stakeholders across the agri-food chain, including farmers, policymakers, and researchers.