 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing socio-economic climate impacts from text data
May 20, 2026Recent advances in natural language processing (NLP) and large language models (LLMs) have enabled the systematic use of large-scale textual data from news, social media, and reports to create datasets with socio-economic impacts of climate hazards such as floods, droughts, storms, and multi-hazard events. As the field of text-as-data for impact assessment expands, so does its methodological complexity. Yet research remains fragmented, with no clear guidelines for defining what constitutes an impact, handling temporal and spatial biases, and selecting appropriate modeling and post-processing strategies. This lack of coherence limits transparency and comparability across studies. Here, we address this gap by synthesising common practices, describing key challenges specific to the use of text-as-data methods for analyzing socio-economic impact data, and proposing recommendations to address them. By providing guidance on best practices, we aim to support the construction of robust text-derived socio-economic impact datasets that can more accurately inform disaster risk management and attribution studies.
Causal machine learning for sustainable agroecosystems
Aug 23, 2024

In a changing climate, sustainable agriculture is essential for food security and environmental health. However, it is challenging to understand the complex interactions among its biophysical, social, and economic components. Predictive machine learning (ML), with its capacity to learn from data, is leveraged in sustainable agriculture for applications like yield prediction and weather forecasting. Nevertheless, it cannot explain causal mechanisms and remains descriptive rather than prescriptive. To address this gap, we propose causal ML, which merges ML's data processing with causality's ability to reason about change. This facilitates quantifying intervention impacts for evidence-based decision-making and enhances predictive model robustness. We showcase causal ML through eight diverse applications that benefit stakeholders across the agri-food chain, including farmers, policymakers, and researchers.
Validating Deep-Learning Weather Forecast Models on Recent High-Impact Extreme Events
Apr 26, 2024



The forecast accuracy of deep-learning-based weather prediction models is improving rapidly, leading many to speak of a "second revolution in weather forecasting". With numerous methods being developed, and limited physical guarantees offered by deep-learning models, there is a critical need for comprehensive evaluation of these emerging techniques. While this need has been partly fulfilled by benchmark datasets, they provide little information on rare and impactful extreme events, or on compound impact metrics, for which model accuracy might degrade due to misrepresented dependencies between variables. To address these issues, we compare deep-learning weather prediction models (GraphCast, PanguWeather, FourCastNet) and ECMWF's high-resolution forecast (HRES) system in three case studies: the 2021 Pacific Northwest heatwave, the 2023 South Asian humid heatwave, and the North American winter storm in 2021. We find evidence that machine learning (ML) weather prediction models can locally achieve similar accuracy to HRES on record-shattering events such as the 2021 Pacific Northwest heatwave and even forecast the compound 2021 North American winter storm substantially better. However, extrapolating to extreme conditions may impact machine learning models more severely than HRES, as evidenced by the comparable or superior spatially- and temporally-aggregated forecast accuracy of HRES for the two heatwaves studied. The ML forecasts also lack variables required to assess the health risks of events such as the 2023 South Asian humid heatwave. Generally, case-study-driven, impact-centric evaluation can complement existing research, increase public trust, and aid in developing reliable ML weather prediction models.
Insights into the drivers and spatio-temporal trends of extreme Mediterranean wildfires with statistical deep-learning
Dec 06, 2022



Extreme wildfires continue to be a significant cause of human death and biodiversity destruction within countries that encompass the Mediterranean Basin. Recent worrying trends in wildfire activity (i.e., occurrence and spread) suggest that wildfires are likely to be highly impacted by climate change. In order to facilitate appropriate risk mitigation, it is imperative to identify the main drivers of extreme wildfires and assess their spatio-temporal trends, with a view to understanding the impacts of global warming on fire activity. To this end, we analyse the monthly burnt area due to wildfires over a region encompassing most of Europe and the Mediterranean Basin from 2001 to 2020, and identify high fire activity during this period in eastern Europe, Algeria, Italy and Portugal. We build an extreme quantile regression model with a high-dimensional predictor set describing meteorological conditions, land cover usage, and orography, for the domain. To model the complex relationships between the predictor variables and wildfires, we make use of a hybrid statistical deep-learning framework that allows us to disentangle the effects of vapour-pressure deficit (VPD), air temperature, and drought on wildfire activity. Our results highlight that whilst VPD, air temperature, and drought significantly affect wildfire occurrence, only VPD affects extreme wildfire spread. Furthermore, to gain insights into the effect of climate change on wildfire activity in the near future, we perturb VPD and temperature according to their observed trends and find evidence that global warming may lead to spatially non-uniform changes in wildfire activity.
Modelling and simulating spatial extremes by combining extreme value theory with generative adversarial networks
Oct 30, 2021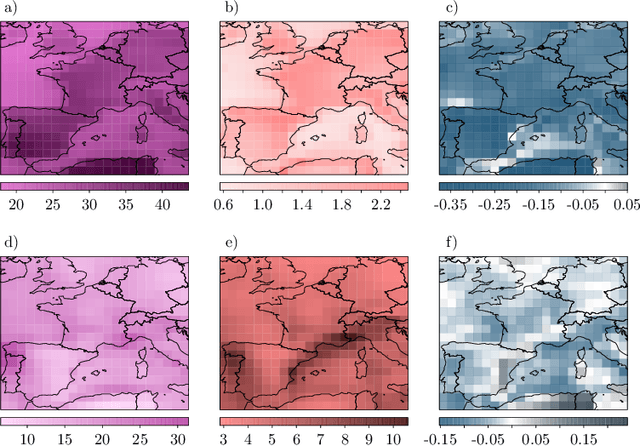
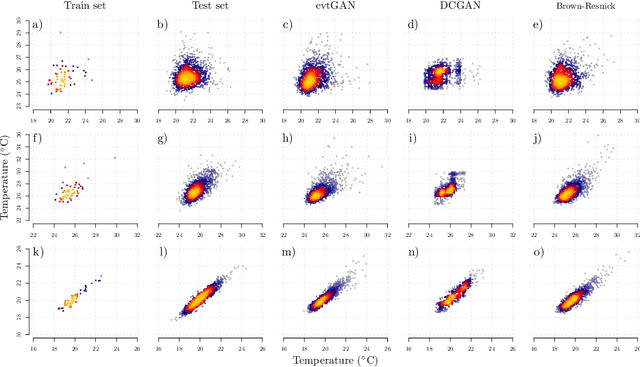
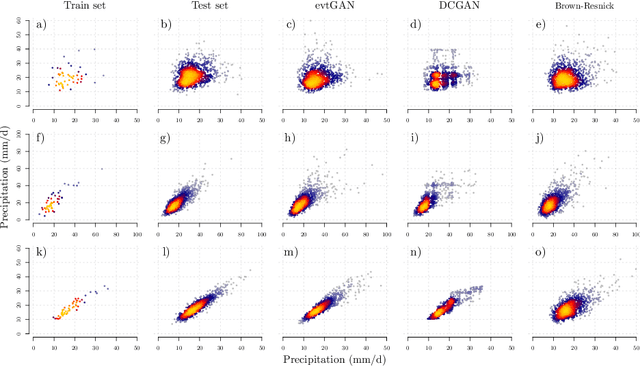
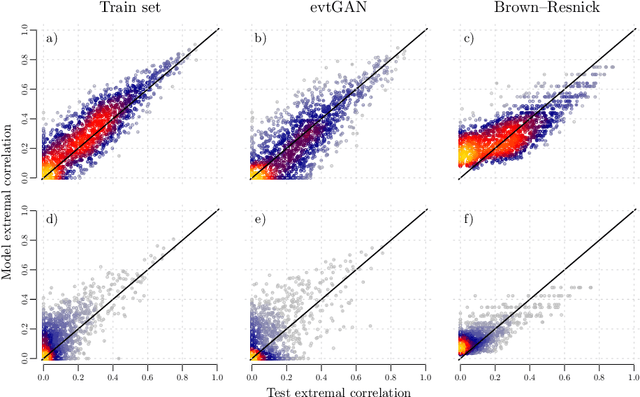
Modelling dependencies between climate extremes is important for climate risk assessment, for instance when allocating emergency management funds. In statistics, multivariate extreme value theory is often used to model spatial extremes. However, most commonly used approaches require strong assumptions and are either too simplistic or over-parametrised. From a machine learning perspective, Generative Adversarial Networks (GANs) are a powerful tool to model dependencies in high-dimensional spaces. Yet in the standard setting, GANs do not well represent dependencies in the extremes. Here we combine GANs with extreme value theory (evtGAN) to model spatial dependencies in summer maxima of temperature and winter maxima in precipitation over a large part of western Europe. We use data from a stationary 2000-year climate model simulation to validate the approach and explore its sensitivity to small sample sizes. Our results show that evtGAN outperforms classical GANs and standard statistical approaches to model spatial extremes. Already with about 50 years of data, which corresponds to commonly available climate records, we obtain reasonably good performance. In general, dependencies between temperature extremes are better captured than dependencies between precipitation extremes due to the high spatial coherence in temperature fields. Our approach can be applied to other climate variables and can be used to emulate climate models when running very long simulations to determine dependencies in the extremes is deemed infeasible.
Distinguishing cause from effect using observational data: methods and benchmarks
Dec 24, 2015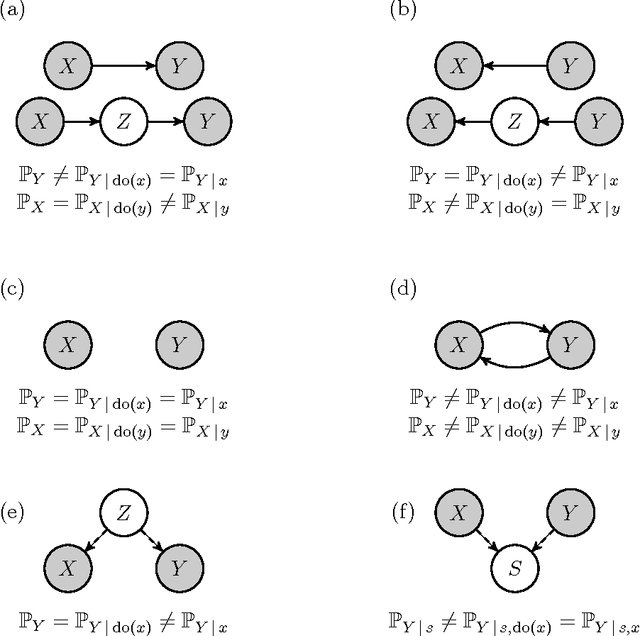
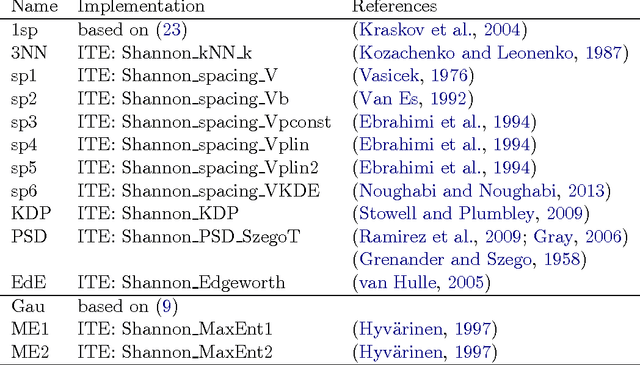
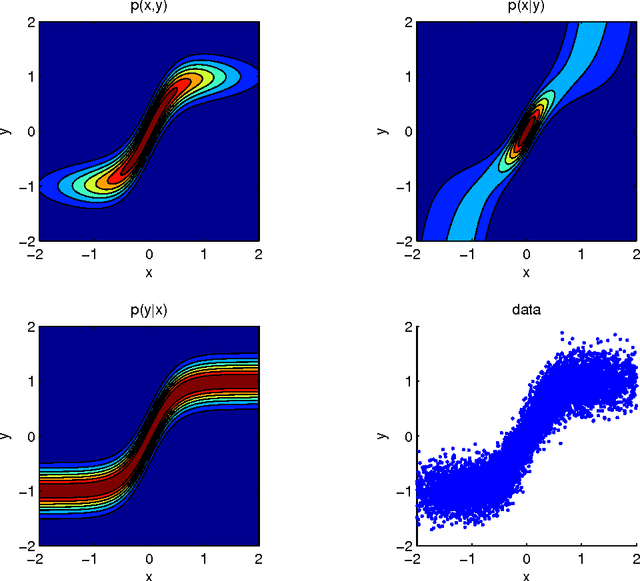
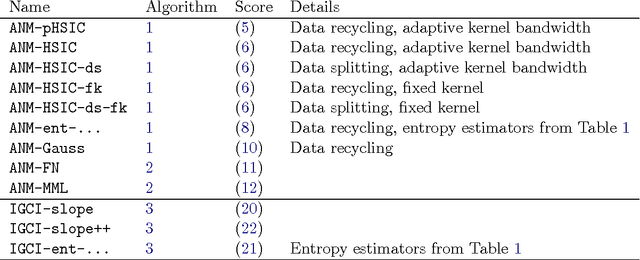
The discovery of causal relationships from purely observational data is a fundamental problem in science. The most elementary form of such a causal discovery problem is to decide whether X causes Y or, alternatively, Y causes X, given joint observations of two variables X, Y. An example is to decide whether altitude causes temperature, or vice versa, given only joint measurements of both variables. Even under the simplifying assumptions of no confounding, no feedback loops, and no selection bias, such bivariate causal discovery problems are challenging. Nevertheless, several approaches for addressing those problems have been proposed in recent years. We review two families of such methods: Additive Noise Methods (ANM) and Information Geometric Causal Inference (IGCI). We present the benchmark CauseEffectPairs that consists of data for 100 different cause-effect pairs selected from 37 datasets from various domains (e.g., meteorology, biology, medicine, engineering, economy, etc.) and motivate our decisions regarding the "ground truth" causal directions of all pairs. We evaluate the performance of several bivariate causal discovery methods on these real-world benchmark data and in addition on artificially simulated data. Our empirical results on real-world data indicate that certain methods are indeed able to distinguish cause from effect using only purely observational data, although more benchmark data would be needed to obtain statistically significant conclusions. One of the best performing methods overall is the additive-noise method originally proposed by Hoyer et al. (2009), which obtains an accuracy of 63+-10 % and an AUC of 0.74+-0.05 on the real-world benchmark. As the main theoretical contribution of this work we prove the consistency of that method.
* 101 pages, second revision submitted to Journal of Machine Learning Research
Inferring deterministic causal relations
Mar 15, 2012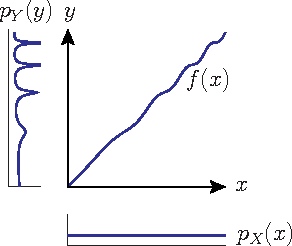
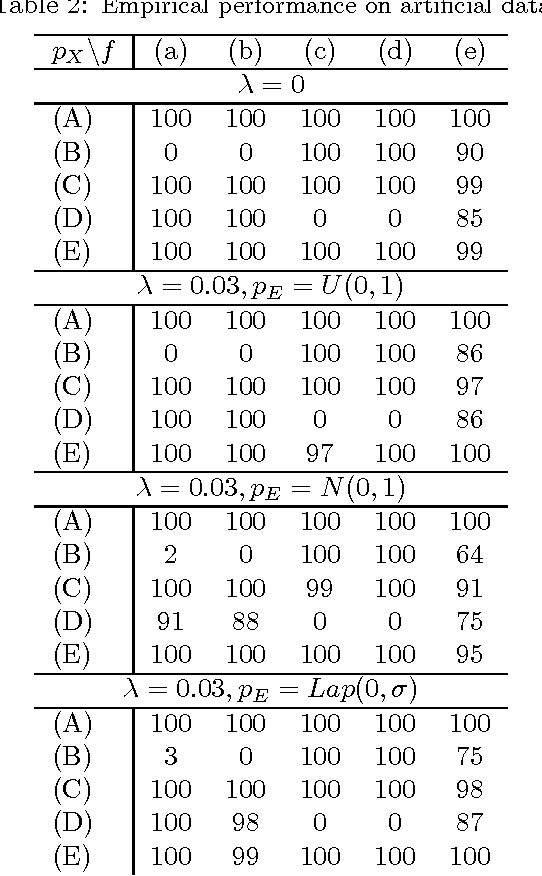
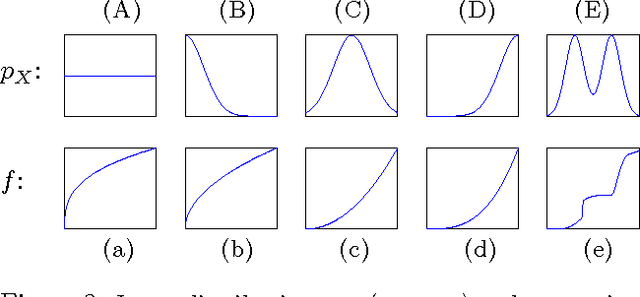

We consider two variables that are related to each other by an invertible function. While it has previously been shown that the dependence structure of the noise can provide hints to determine which of the two variables is the cause, we presently show that even in the deterministic (noise-free) case, there are asymmetries that can be exploited for causal inference. Our method is based on the idea that if the function and the probability density of the cause are chosen independently, then the distribution of the effect will, in a certain sense, depend on the function. We provide a theoretical analysis of this method, showing that it also works in the low noise regime, and link it to information geometry. We report strong empirical results on various real-world data sets from different domains.
Testing whether linear equations are causal: A free probability theory approach
Feb 14, 2012
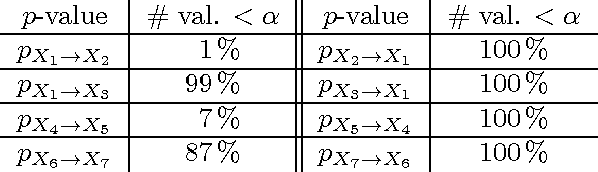
We propose a method that infers whether linear relations between two high-dimensional variables X and Y are due to a causal influence from X to Y or from Y to X. The earlier proposed so-called Trace Method is extended to the regime where the dimension of the observed variables exceeds the sample size. Based on previous work, we postulate conditions that characterize a causal relation between X and Y. Moreover, we describe a statistical test and argue that both causal directions are typically rejected if there is a common cause. A full theoretical analysis is presented for the deterministic case but our approach seems to be valid for the noisy case, too, for which we additionally present an approach based on a sparsity constraint. The discussed method yields promising results for both simulated and real world data.