 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetCause: Counterfactual Learning for Root Cause Analysis in Large-Scale Networks
Jun 11, 2026Can a learned model capture how faults propagate through a large-scale network and use this knowledge to causally attribute customer impact to its underlying root cause? Existing root cause analysis techniques often rely on static rules, correlation heuristics, or topology-local reasoning, which struggle to generalize in dynamic environments where faults propagate across complex physical and logical dependencies. We present NetCause, a self-supervised learning-based framework that models network incidents as graph-temporal processes and uses counterfactual simulation to rank candidate root causes. This approach produces an interpretable ranking of root cause hypotheses and integrates naturally with operator-defined mitigation and remediation actions. We train the model on over 1,500 incidents collected over six months from a leading cloud provider's production network and evaluate it on 31 expert-labeled incidents. NetCause consistently improves root cause ranking quality in the regime most relevant to operational decision-making, achieving a 16.1% accuracy improvement over a rule-based heuristic baseline. While training is computationally intensive, inference is lightweight, requiring only seconds of GPU runtime per incident (well below typical telemetry collection latencies).
Graphical Causal Reasoning for Root Cause Analysis in Cloud Networks
Jun 11, 2026Cloud-computing relies on large-scale networks which are inherently complex systems. In this paper, we present a novel approach to root cause analysis (RCA) of cloud network incidents, leveraging graph-based causal discovery techniques. Our method addresses the limitations of rule-based automation by introducing a spatiotemporal grouping strategy and an automation ontology to reduce the dimensionality of the problem. We construct a causal graph from binary time series data using bivariate Granger causality and conditional independence tests. For inference, we introduce a probabilistic method that assigns edge-specific conditional probabilities as a function of time lag, allowing for interpretable, time-aware root cause scoring via causal graph traversal. We evaluated the system using a labeled dataset of 35 production incidents from a major cloud provider. The model successfully recalled the correct root cause in 85.7% of incidents and produced an exact match in 74.3%. In production, the deployed system has been used in over 800 real-world incidents, with positive qualitative feedback from network engineers. These results highlight the practicality of a data-driven, causal approach to RCA in dynamic and large-scale operational environments.
Measuring Semantic Progress in Multi-turn Dialogue via Information Gain
Jun 10, 2026Evaluating multi-turn dialogue is challenging because quality emerges across turns rather than within individual responses. We focus on a key dimension of information-seeking dialogue: semantic progress, defined as the accumulation of new, question-relevant, and non-redundant information over the course of a conversation. We formalize semantic progress as question-conditioned uncertainty reduction and introduce an information-theoretic metric that approximates it in embedding space. Our main estimator uses a tractable Gaussian formulation with closed-form updates, while a complementary maximum-entropy argument shows why log-determinant structure arises more broadly when only second-order embedding information is retained. This formulation yields desirable theoretical properties, including monotonicity, additive decomposition of total information gain across turns, and diminishing returns for redundant evidence. Unlike LLM-as-a-judge approaches, our metric requires no autoregressive inference at evaluation time and is fully reproducible for a fixed embedding model. Experiments on MT-Bench, Chatbot Arena, and UltraFeedback show that the proposed metric achieves competitive agreement with human judgments despite targeting only semantic progress, with improved alignment on MT-Bench and UltraFeedback compared to several LLM-based judges. Notably, the method remains effective with lightweight embedding models under CPU-only execution, indicating that semantic progress can be captured without reliance on large model capacity.
Formalizing and falsifying causal pathways of rare events
May 29, 2026Building on recent formalizations of root cause analysis for rare events (``outliers'') in structural equation models, we propose a formal definition of a causal pathway and discuss its testable implications. We identify conditions under which these implications depend only on a causal abstraction defined by the pathway of rare events, rather than on the full causal graph of the underlying system. Accordingly, we introduce an abstraction of causal structure to pathways of rare events that bridges simple verbal causal explanations and detailed causal modeling.
Evaluating Bivariate Causal Statements Based on Mutual Compatibility
May 29, 2026For many real-world systems, causal ground truth is difficult to obtain, making claims about causal effects hard to assess. We develop methods for evaluating collections of $\binom{n}{2}$ bivariate causal statements over a set of $n$ variables. In the setting of acyclic linear statements, any such collection can be extended to a unique multivariate causal model, but we argue that this induced model is implausible if it imposes substantial additional confounding to explain observed correlations. We introduce a compatibility score that quantifies this notion of plausibility, notably without relying on the faithfulness assumption. Additionally, we define an incompatibility score for purely graphical bivariate causal statements, based on global consistency constraints that are derived from acyclicity and faithfulness assumptions. We give theoretical and empirical evidence that both scores can successfully distinguish correct from incorrect causal statements in generic settings. Moreover, we demonstrate the practical applicability of our methods by analyzing causal claims made by large language models. Our work aims to provide a foundation for assessing the reliability of causal information derived from human experts or artificial intelligence in settings where alternative forms of validation are unavailable.
IV Co-Scientist: Multi-Agent LLM Framework for Causal Instrumental Variable Discovery
Feb 08, 2026In the presence of confounding between an endogenous variable and the outcome, instrumental variables (IVs) are used to isolate the causal effect of the endogenous variable. Identifying valid instruments requires interdisciplinary knowledge, creativity, and contextual understanding, making it a non-trivial task. In this paper, we investigate whether large language models (LLMs) can aid in this task. We perform a two-stage evaluation framework. First, we test whether LLMs can recover well-established instruments from the literature, assessing their ability to replicate standard reasoning. Second, we evaluate whether LLMs can identify and avoid instruments that have been empirically or theoretically discredited. Building on these results, we introduce IV Co-Scientist, a multi-agent system that proposes, critiques, and refines IVs for a given treatment-outcome pair. We also introduce a statistical test to contextualize consistency in the absence of ground truth. Our results show the potential of LLMs to discover valid instrumental variables from a large observational database.
From Guess2Graph: When and How Can Unreliable Experts Safely Boost Causal Discovery in Finite Samples?
Oct 16, 2025Causal discovery algorithms often perform poorly with limited samples. While integrating expert knowledge (including from LLMs) as constraints promises to improve performance, guarantees for existing methods require perfect predictions or uncertainty estimates, making them unreliable for practical use. We propose the Guess2Graph (G2G) framework, which uses expert guesses to guide the sequence of statistical tests rather than replacing them. This maintains statistical consistency while enabling performance improvements. We develop two instantiations of G2G: PC-Guess, which augments the PC algorithm, and gPC-Guess, a learning-augmented variant designed to better leverage high-quality expert input. Theoretically, both preserve correctness regardless of expert error, with gPC-Guess provably outperforming its non-augmented counterpart in finite samples when experts are "better than random." Empirically, both show monotonic improvement with expert accuracy, with gPC-Guess achieving significantly stronger gains.
Root Cause Analysis of Outliers in Unknown Cyclic Graphs
Oct 08, 2025We study the propagation of outliers in cyclic causal graphs with linear structural equations, tracing them back to one or several "root cause" nodes. We show that it is possible to identify a short list of potential root causes provided that the perturbation is sufficiently strong and propagates according to the same structural equations as in the normal mode. This shortlist consists of the true root causes together with those of its parents lying on a cycle with the root cause. Notably, our method does not require prior knowledge of the causal graph.
On Different Notions of Redundancy in Conditional-Independence-Based Discovery of Graphical Models
Feb 12, 2025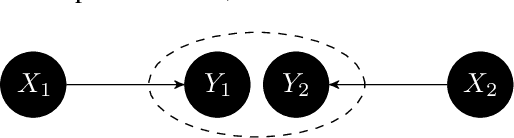

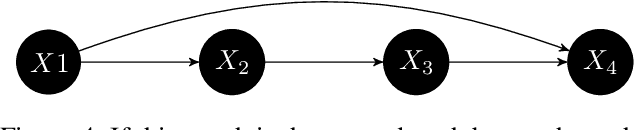
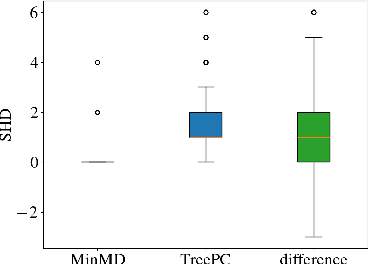
The goal of conditional-independence-based discovery of graphical models is to find a graph that represents the independence structure of variables in a given dataset. To learn such a representation, conditional-independence-based approaches conduct a set of statistical tests that suffices to identify the graphical representation under some assumptions on the underlying distribution of the data. In this work, we highlight that due to the conciseness of the graphical representation, there are often many tests that are not used in the construction of the graph. These redundant tests have the potential to detect or sometimes correct errors in the learned model. We show that not all tests contain this additional information and that such redundant tests have to be applied with care. Precisely, we argue that particularly those conditional (in)dependence statements are interesting that follow only from graphical assumptions but do not hold for every probability distribution.
Toward Universal Laws of Outlier Propagation
Feb 12, 2025We argue that Algorithmic Information Theory (AIT) admits a principled way to quantify outliers in terms of so-called randomness deficiency. For the probability distribution generated by a causal Bayesian network, we show that the randomness deficiency of the joint state decomposes into randomness deficiencies of each causal mechanism, subject to the Independence of Mechanisms Principle. Accordingly, anomalous joint observations can be quantitatively attributed to their root causes, i.e., the mechanisms that behaved anomalously. As an extension of Levin's law of randomness conservation, we show that weak outliers cannot cause strong ones when Independence of Mechanisms holds. We show how these information theoretic laws provide a better understanding of the behaviour of outliers defined with respect to existing scores.