 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks at Any Scale
Nov 14, 2025This article reviews modern optimization methods for training neural networks with an emphasis on efficiency and scale. We present state-of-the-art optimization algorithms under a unified algorithmic template that highlights the importance of adapting to the structures in the problem. We then cover how to make these algorithms agnostic to the scale of the problem. Our exposition is intended as an introduction for both practitioners and researchers who wish to be involved in these exciting new developments.
On the Surprising Effectiveness of Large Learning Rates under Standard Width Scaling
May 28, 2025



The dominant paradigm for training large-scale vision and language models is He initialization and a single global learning rate (\textit{standard parameterization}, SP). Despite its practical success, standard parametrization remains poorly understood from a theoretical perspective: Existing infinite-width theory would predict instability under large learning rates and vanishing feature learning under stable learning rates. However, empirically optimal learning rates consistently decay much slower than theoretically predicted. By carefully studying neural network training dynamics, we demonstrate that this discrepancy is not fully explained by finite-width phenomena such as catapult effects or a lack of alignment between weights and incoming activations. We instead show that the apparent contradiction can be fundamentally resolved by taking the loss function into account: In contrast to Mean Squared Error (MSE) loss, we prove that under cross-entropy (CE) loss, an intermediate \textit{controlled divergence} regime emerges, where logits diverge but loss, gradients, and activations remain stable. Stable training under large learning rates enables persistent feature evolution at scale in all hidden layers, which is crucial for the practical success of SP. In experiments across optimizers (SGD, Adam), architectures (MLPs, GPT) and data modalities (vision, language), we validate that neural networks operate in this controlled divergence regime under CE loss but not under MSE loss. Our empirical evidence suggests that width-scaling considerations are surprisingly useful for predicting empirically optimal learning rate exponents. Finally, our analysis clarifies the effectiveness and limitations of recently proposed layerwise learning rate scalings for standard initialization.
$\boldsymbolμ\mathbf{P^2}$: Effective Sharpness Aware Minimization Requires Layerwise Perturbation Scaling
Oct 31, 2024Sharpness Aware Minimization (SAM) enhances performance across various neural architectures and datasets. As models are continually scaled up to improve performance, a rigorous understanding of SAM's scaling behaviour is paramount. To this end, we study the infinite-width limit of neural networks trained with SAM, using the Tensor Programs framework. Our findings reveal that the dynamics of standard SAM effectively reduce to applying SAM solely in the last layer in wide neural networks, even with optimal hyperparameters. In contrast, we identify a stable parameterization with layerwise perturbation scaling, which we call $\textit{Maximal Update and Perturbation Parameterization}$ ($\mu$P$^2$), that ensures all layers are both feature learning and effectively perturbed in the limit. Through experiments with MLPs, ResNets and Vision Transformers, we empirically demonstrate that $\mu$P$^2$ is the first parameterization to achieve hyperparameter transfer of the joint optimum of learning rate and perturbation radius across model scales. Moreover, we provide an intuitive condition to derive $\mu$P$^2$ for other perturbation rules like Adaptive SAM and SAM-ON, also ensuring balanced perturbation effects across all layers.
Explaining Kernel Clustering via Decision Trees
Feb 15, 2024Despite the growing popularity of explainable and interpretable machine learning, there is still surprisingly limited work on inherently interpretable clustering methods. Recently, there has been a surge of interest in explaining the classic k-means algorithm, leading to efficient algorithms that approximate k-means clusters using axis-aligned decision trees. However, interpretable variants of k-means have limited applicability in practice, where more flexible clustering methods are often needed to obtain useful partitions of the data. In this work, we investigate interpretable kernel clustering, and propose algorithms that construct decision trees to approximate the partitions induced by kernel k-means, a nonlinear extension of k-means. We further build on previous work on explainable k-means and demonstrate how a suitable choice of features allows preserving interpretability without sacrificing approximation guarantees on the interpretable model.
Self-Compatibility: Evaluating Causal Discovery without Ground Truth
Jul 18, 2023As causal ground truth is incredibly rare, causal discovery algorithms are commonly only evaluated on simulated data. This is concerning, given that simulations reflect common preconceptions about generating processes regarding noise distributions, model classes, and more. In this work, we propose a novel method for falsifying the output of a causal discovery algorithm in the absence of ground truth. Our key insight is that while statistical learning seeks stability across subsets of data points, causal learning should seek stability across subsets of variables. Motivated by this insight, our method relies on a notion of compatibility between causal graphs learned on different subsets of variables. We prove that detecting incompatibilities can falsify wrongly inferred causal relations due to violation of assumptions or errors from finite sample effects. Although passing such compatibility tests is only a necessary criterion for good performance, we argue that it provides strong evidence for the causal models whenever compatibility entails strong implications for the joint distribution. We also demonstrate experimentally that detection of incompatibilities can aid in causal model selection.
Reinterpreting causal discovery as the task of predicting unobserved joint statistics
May 11, 2023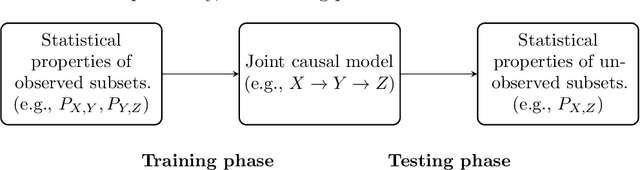

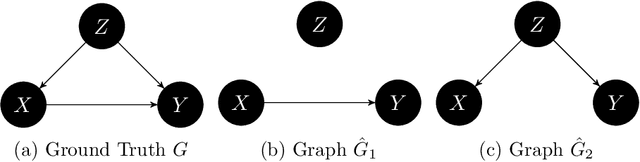
If $X,Y,Z$ denote sets of random variables, two different data sources may contain samples from $P_{X,Y}$ and $P_{Y,Z}$, respectively. We argue that causal discovery can help inferring properties of the `unobserved joint distributions' $P_{X,Y,Z}$ or $P_{X,Z}$. The properties may be conditional independences (as in `integrative causal inference') or also quantitative statements about dependences. More generally, we define a learning scenario where the input is a subset of variables and the label is some statistical property of that subset. Sets of jointly observed variables define the training points, while unobserved sets are possible test points. To solve this learning task, we infer, as an intermediate step, a causal model from the observations that then entails properties of unobserved sets. Accordingly, we can define the VC dimension of a class of causal models and derive generalization bounds for the predictions. Here, causal discovery becomes more modest and better accessible to empirical tests than usual: rather than trying to find a causal hypothesis that is `true' a causal hypothesis is {\it useful} whenever it correctly predicts statistical properties of unobserved joint distributions. This way, a sparse causal graph that omits weak influences may be more useful than a dense one (despite being less accurate) because it is able to reconstruct the full joint distribution from marginal distributions of smaller subsets. Within such a `pragmatic' application of causal discovery, some popular heuristic approaches become justified in retrospect. It is, for instance, allowed to infer DAGs from partial correlations instead of conditional independences if the DAGs are only used to predict partial correlations.
A Consistent Estimator for Confounding Strength
Nov 03, 2022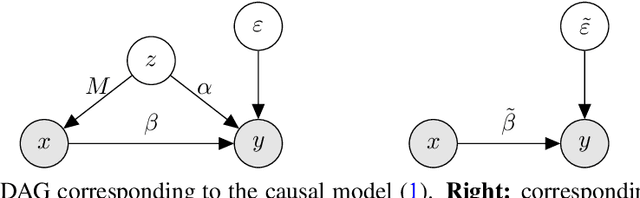
Regression on observational data can fail to capture a causal relationship in the presence of unobserved confounding. Confounding strength measures this mismatch, but estimating it requires itself additional assumptions. A common assumption is the independence of causal mechanisms, which relies on concentration phenomena in high dimensions. While high dimensions enable the estimation of confounding strength, they also necessitate adapted estimators. In this paper, we derive the asymptotic behavior of the confounding strength estimator by Janzing and Sch\"olkopf (2018) and show that it is generally not consistent. We then use tools from random matrix theory to derive an adapted, consistent estimator.
Interpolation and Regularization for Causal Learning
Feb 18, 2022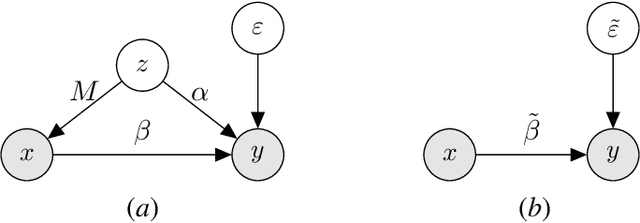

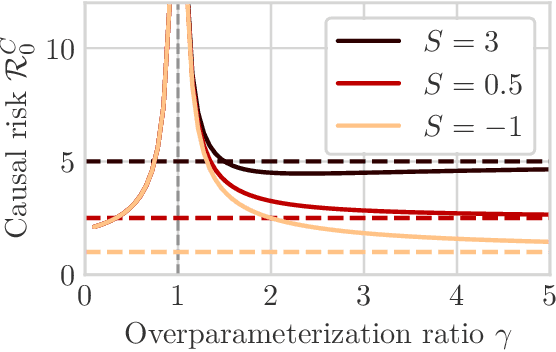
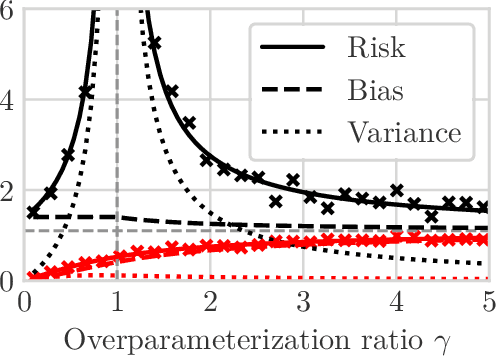
We study the problem of learning causal models from observational data through the lens of interpolation and its counterpart -- regularization. A large volume of recent theoretical, as well as empirical work, suggests that, in highly complex model classes, interpolating estimators can have good statistical generalization properties and can even be optimal for statistical learning. Motivated by an analogy between statistical and causal learning recently highlighted by Janzing (2019), we investigate whether interpolating estimators can also learn good causal models. To this end, we consider a simple linearly confounded model and derive precise asymptotics for the *causal risk* of the min-norm interpolator and ridge-regularized regressors in the high-dimensional regime. Under the principle of independent causal mechanisms, a standard assumption in causal learning, we find that interpolators cannot be optimal and causal learning requires stronger regularization than statistical learning. This resolves a recent conjecture in Janzing (2019). Beyond this assumption, we find a larger range of behavior that can be precisely characterized with a new measure of *confounding strength*. If the confounding strength is negative, causal learning requires weaker regularization than statistical learning, interpolators can be optimal, and the optimal regularization can even be negative. If the confounding strength is large, the optimal regularization is infinite, and learning from observational data is actively harmful.
Learning Theory Can (Sometimes) Explain Generalisation in Graph Neural Networks
Dec 07, 2021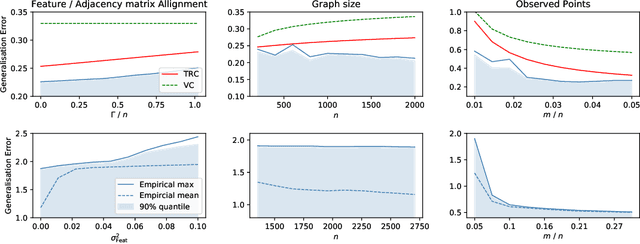
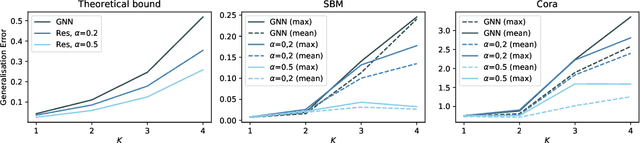
In recent years, several results in the supervised learning setting suggested that classical statistical learning-theoretic measures, such as VC dimension, do not adequately explain the performance of deep learning models which prompted a slew of work in the infinite-width and iteration regimes. However, there is little theoretical explanation for the success of neural networks beyond the supervised setting. In this paper we argue that, under some distributional assumptions, classical learning-theoretic measures can sufficiently explain generalization for graph neural networks in the transductive setting. In particular, we provide a rigorous analysis of the performance of neural networks in the context of transductive inference, specifically by analysing the generalisation properties of graph convolutional networks for the problem of node classification. While VC Dimension does result in trivial generalisation error bounds in this setting as well, we show that transductive Rademacher complexity can explain the generalisation properties of graph convolutional networks for stochastic block models. We further use the generalisation error bounds based on transductive Rademacher complexity to demonstrate the role of graph convolutions and network architectures in achieving smaller generalisation error and provide insights into when the graph structure can help in learning. The findings of this paper could re-new the interest in studying generalisation in neural networks in terms of learning-theoretic measures, albeit in specific problems.
Causal Forecasting:Generalization Bounds for Autoregressive Models
Nov 18, 2021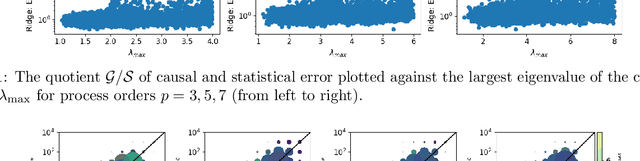
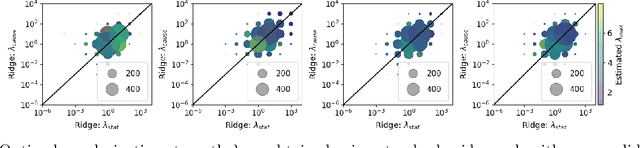
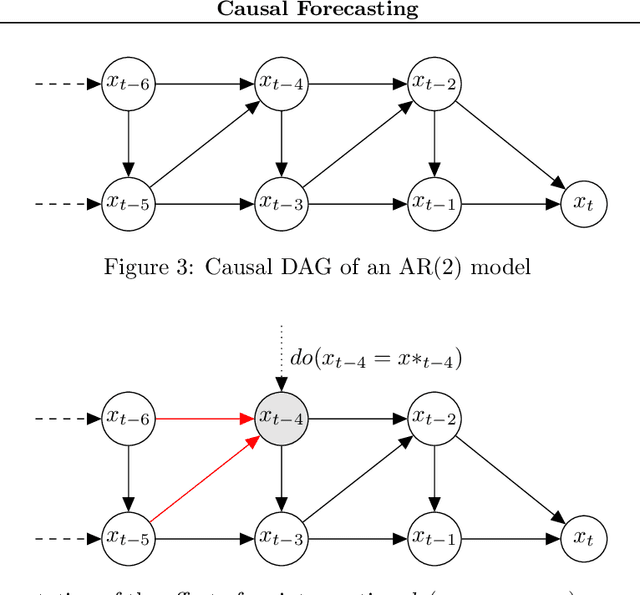
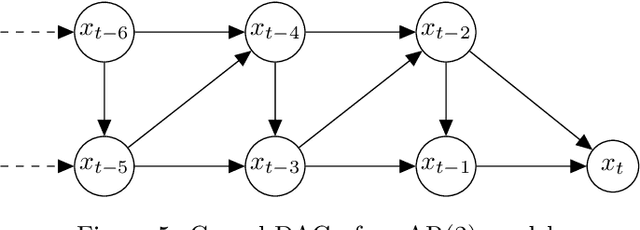
Despite the increasing relevance of forecasting methods, the causal implications of these algorithms remain largely unexplored. This is concerning considering that, even under simplifying assumptions such as causal sufficiency, the statistical risk of a model can differ significantly from its \textit{causal risk}. Here, we study the problem of *causal generalization* -- generalizing from the observational to interventional distributions -- in forecasting. Our goal is to find answers to the question: How does the efficacy of an autoregressive (VAR) model in predicting statistical associations compare with its ability to predict under interventions? To this end, we introduce the framework of *causal learning theory* for forecasting. Using this framework, we obtain a characterization of the difference between statistical and causal risks, which helps identify sources of divergence between them. Under causal sufficiency, the problem of causal generalization amounts to learning under covariate shifts albeit with additional structure (restriction to interventional distributions). This structure allows us to obtain uniform convergence bounds on causal generalizability for the class of VAR models. To the best of our knowledge, this is the first work that provides theoretical guarantees for causal generalization in the time-series setting.