 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing predictive multiplicity to measure individual performance within the AI Act
Feb 12, 2026When building AI systems for decision support, one often encounters the phenomenon of predictive multiplicity: a single best model does not exist; instead, one can construct many models with similar overall accuracy that differ in their predictions for individual cases. Especially when decisions have a direct impact on humans, this can be highly unsatisfactory. For a person subject to high disagreement between models, one could as well have chosen a different model of similar overall accuracy that would have decided the person's case differently. We argue that this arbitrariness conflicts with the EU AI Act, which requires providers of high-risk AI systems to report performance not only at the dataset level but also for specific persons. The goal of this paper is to put predictive multiplicity in context with the EU AI Act's provisions on accuracy and to subsequently derive concrete suggestions on how to evaluate and report predictive multiplicity in practice. Specifically: (1) We argue that incorporating information about predictive multiplicity can serve compliance with the EU AI Act's accuracy provisions for providers. (2) Based on this legal analysis, we suggest individual conflict ratios and $δ$-ambiguity as tools to quantify the disagreement between models on individual cases and to help detect individuals subject to conflicting predictions. (3) Based on computational insights, we derive easy-to-implement rules on how model providers could evaluate predictive multiplicity in practice. (4) Ultimately, we suggest that information about predictive multiplicity should be made available to deployers under the AI Act, enabling them to judge whether system outputs for specific individuals are reliable enough for their use case.
On the Surprising Effectiveness of Large Learning Rates under Standard Width Scaling
May 28, 2025



The dominant paradigm for training large-scale vision and language models is He initialization and a single global learning rate (\textit{standard parameterization}, SP). Despite its practical success, standard parametrization remains poorly understood from a theoretical perspective: Existing infinite-width theory would predict instability under large learning rates and vanishing feature learning under stable learning rates. However, empirically optimal learning rates consistently decay much slower than theoretically predicted. By carefully studying neural network training dynamics, we demonstrate that this discrepancy is not fully explained by finite-width phenomena such as catapult effects or a lack of alignment between weights and incoming activations. We instead show that the apparent contradiction can be fundamentally resolved by taking the loss function into account: In contrast to Mean Squared Error (MSE) loss, we prove that under cross-entropy (CE) loss, an intermediate \textit{controlled divergence} regime emerges, where logits diverge but loss, gradients, and activations remain stable. Stable training under large learning rates enables persistent feature evolution at scale in all hidden layers, which is crucial for the practical success of SP. In experiments across optimizers (SGD, Adam), architectures (MLPs, GPT) and data modalities (vision, language), we validate that neural networks operate in this controlled divergence regime under CE loss but not under MSE loss. Our empirical evidence suggests that width-scaling considerations are surprisingly useful for predicting empirically optimal learning rate exponents. Finally, our analysis clarifies the effectiveness and limitations of recently proposed layerwise learning rate scalings for standard initialization.
How to safely discard features based on aggregate SHAP values
Mar 29, 2025

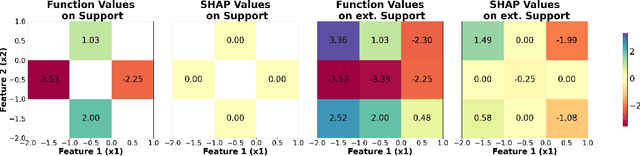

SHAP is one of the most popular local feature-attribution methods. Given a function f and an input x, it quantifies each feature's contribution to f(x). Recently, SHAP has been increasingly used for global insights: practitioners average the absolute SHAP values over many data points to compute global feature importance scores, which are then used to discard unimportant features. In this work, we investigate the soundness of this practice by asking whether small aggregate SHAP values necessarily imply that the corresponding feature does not affect the function. Unfortunately, the answer is no: even if the i-th SHAP value is 0 on the entire data support, there exist functions that clearly depend on Feature i. The issue is that computing SHAP values involves evaluating f on points outside of the data support, where f can be strategically designed to mask its dependence on Feature i. To address this, we propose to aggregate SHAP values over the extended support, which is the product of the marginals of the underlying distribution. With this modification, we show that a small aggregate SHAP value implies that we can safely discard the corresponding feature. We then extend our results to KernelSHAP, the most popular method to approximate SHAP values in practice. We show that if KernelSHAP is computed over the extended distribution, a small aggregate value justifies feature removal. This result holds independently of whether KernelSHAP accurately approximates true SHAP values, making it one of the first theoretical results to characterize the KernelSHAP algorithm itself. Our findings have both theoretical and practical implications. We introduce the Shapley Lie algebra, which offers algebraic insights that may enable a deeper investigation of SHAP and we show that randomly permuting each column of the data matrix enables safely discarding features based on aggregate SHAP and KernelSHAP values.
Disentangling Interactions and Dependencies in Feature Attribution
Oct 31, 2024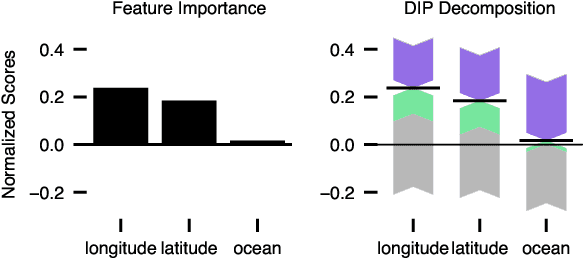
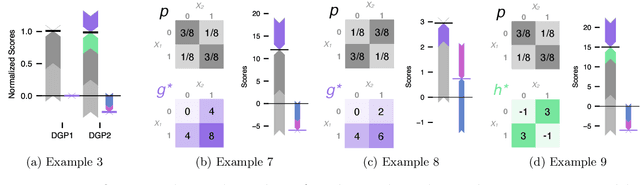
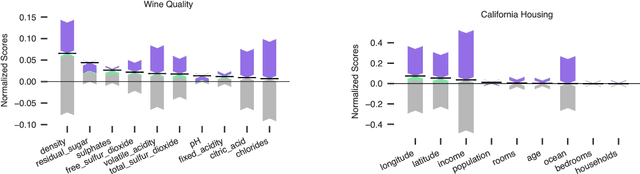
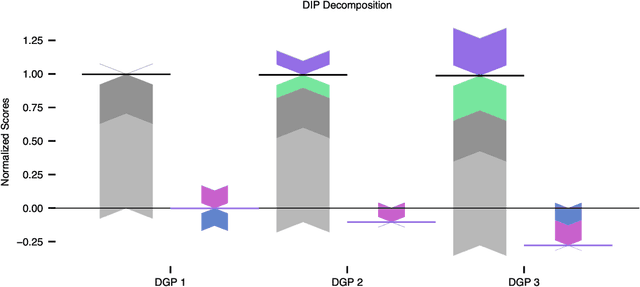
In explainable machine learning, global feature importance methods try to determine how much each individual feature contributes to predicting the target variable, resulting in one importance score for each feature. But often, predicting the target variable requires interactions between several features (such as in the XOR function), and features might have complex statistical dependencies that allow to partially replace one feature with another one. In commonly used feature importance scores these cooperative effects are conflated with the features' individual contributions, making them prone to misinterpretations. In this work, we derive DIP, a new mathematical decomposition of individual feature importance scores that disentangles three components: the standalone contribution and the contributions stemming from interactions and dependencies. We prove that the DIP decomposition is unique and show how it can be estimated in practice. Based on these results, we propose a new visualization of feature importance scores that clearly illustrates the different contributions.
How much can we forget about Data Contamination?
Oct 04, 2024
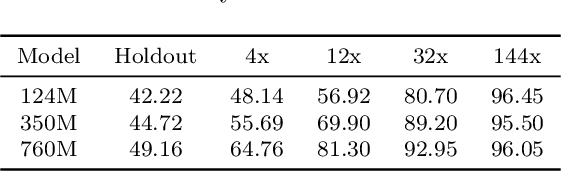
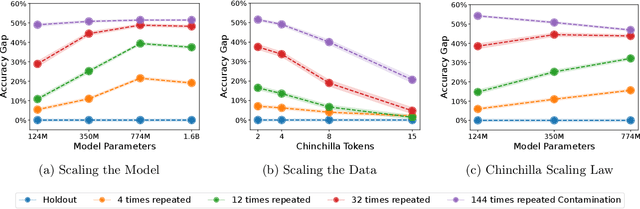
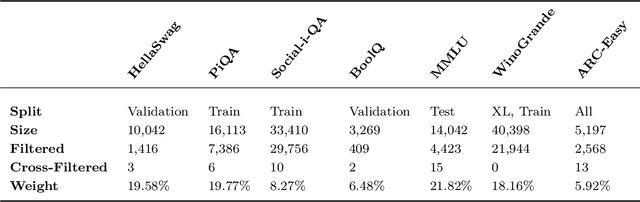
The leakage of benchmark data into the training data has emerged as a significant challenge for evaluating the capabilities of large language models (LLMs). In this work, we use experimental evidence and theoretical estimates to challenge the common assumption that small-scale contamination renders benchmark evaluations invalid. First, we experimentally quantify the magnitude of benchmark overfitting based on scaling along three dimensions: The number of model parameters (up to 1.6B), the number of times an example is seen (up to 144), and the number of training tokens (up to 40B). We find that if model and data follow the Chinchilla scaling laws, minor contamination indeed leads to overfitting. At the same time, even 144 times of contamination can be forgotten if the training data is scaled beyond five times Chinchilla, a regime characteristic of many modern LLMs. We then derive a simple theory of example forgetting via cumulative weight decay. It allows us to bound the number of gradient steps required to forget past data for any training run where we know the hyperparameters of AdamW. This indicates that many LLMs, including Llama 3, have forgotten the data seen at the beginning of training. Experimentally, we demonstrate that forgetting occurs faster than what is predicted by our bounds. Taken together, our results suggest that moderate amounts of contamination can be forgotten at the end of realistically scaled training runs.
Auditing Local Explanations is Hard
Jul 18, 2024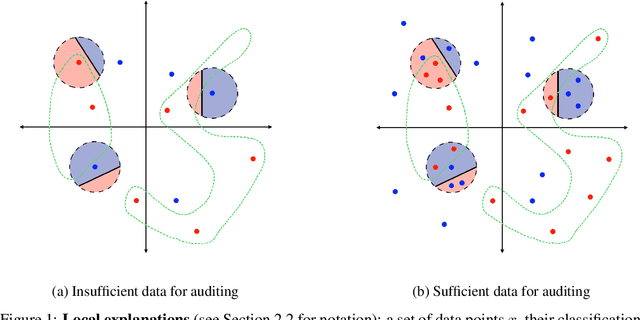
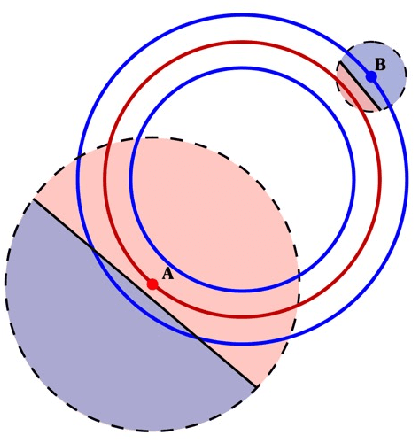
In sensitive contexts, providers of machine learning algorithms are increasingly required to give explanations for their algorithms' decisions. However, explanation receivers might not trust the provider, who potentially could output misleading or manipulated explanations. In this work, we investigate an auditing framework in which a third-party auditor or a collective of users attempts to sanity-check explanations: they can query model decisions and the corresponding local explanations, pool all the information received, and then check for basic consistency properties. We prove upper and lower bounds on the amount of queries that are needed for an auditor to succeed within this framework. Our results show that successful auditing requires a potentially exorbitant number of queries -- particularly in high dimensional cases. Our analysis also reveals that a key property is the ``locality'' of the provided explanations -- a quantity that so far has not been paid much attention to in the explainability literature. Looking forward, our results suggest that for complex high-dimensional settings, merely providing a pointwise prediction and explanation could be insufficient, as there is no way for the users to verify that the provided explanations are not completely made-up.
Statistics without Interpretation: A Sober Look at Explainable Machine Learning
Feb 05, 2024In the rapidly growing literature on explanation algorithms, it often remains unclear what precisely these algorithms are for and how they should be used. We argue that this is because explanation algorithms are often mathematically complex but don't admit a clear interpretation. Unfortunately, complex statistical methods that don't have a clear interpretation are bound to lead to errors in interpretation, a fact that has become increasingly apparent in the literature. In order to move forward, papers on explanation algorithms should make clear how precisely the output of the algorithms should be interpreted. They should also clarify what questions about the function can and cannot be answered given the explanations. Our argument is based on the distinction between statistics and their interpretation. It also relies on parallels between explainable machine learning and applied statistics.
Mind the spikes: Benign overfitting of kernels and neural networks in fixed dimension
May 23, 2023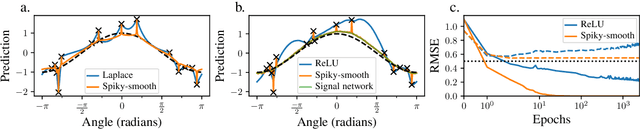
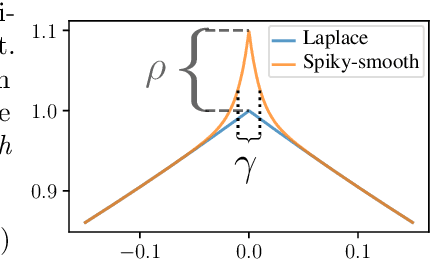

The success of over-parameterized neural networks trained to near-zero training error has caused great interest in the phenomenon of benign overfitting, where estimators are statistically consistent even though they interpolate noisy training data. While benign overfitting in fixed dimension has been established for some learning methods, current literature suggests that for regression with typical kernel methods and wide neural networks, benign overfitting requires a high-dimensional setting where the dimension grows with the sample size. In this paper, we show that the smoothness of the estimators, and not the dimension, is the key: benign overfitting is possible if and only if the estimator's derivatives are large enough. We generalize existing inconsistency results to non-interpolating models and more kernels to show that benign overfitting with moderate derivatives is impossible in fixed dimension. Conversely, we show that benign overfitting is possible for regression with a sequence of spiky-smooth kernels with large derivatives. Using neural tangent kernels, we translate our results to wide neural networks. We prove that while infinite-width networks do not overfit benignly with the ReLU activation, this can be fixed by adding small high-frequency fluctuations to the activation function. Our experiments verify that such neural networks, while overfitting, can indeed generalize well even on low-dimensional data sets.
ChatGPT Participates in a Computer Science Exam
Mar 08, 2023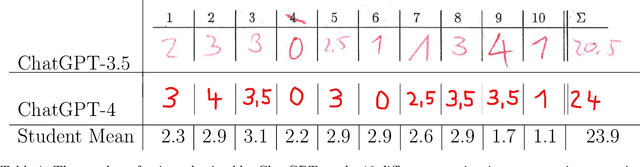


We asked ChatGPT to participate in an undergraduate computer science exam on ''Algorithms and Data Structures''. We evaluated the program on the entire exam as posed to the students. We hand-copied its answers onto an exam sheet, which was subsequently graded in a blind setup alongside those of 200 participating students. We find that ChatGPT narrowly passed the exam, obtaining 20.5 out of 40 points. This impressive performance indicates that ChatGPT can indeed succeed in challenging tasks like university exams. At the same time, the tasks in our exam are structurally similar to those on other exams, solved homework problems, and teaching materials that can be found online. Therefore, it would be premature to conclude from this experiment that ChatGPT has any understanding of computer science. The transcript of our conversation with ChatGPT is available at \url{https://github.com/tml-tuebingen/chatgpt-algorithm-exam}, and the entire graded exam is in the appendix of this paper.
AI for Science: An Emerging Agenda
Mar 07, 2023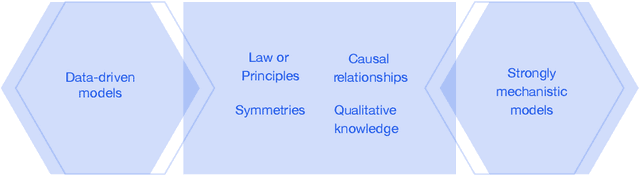
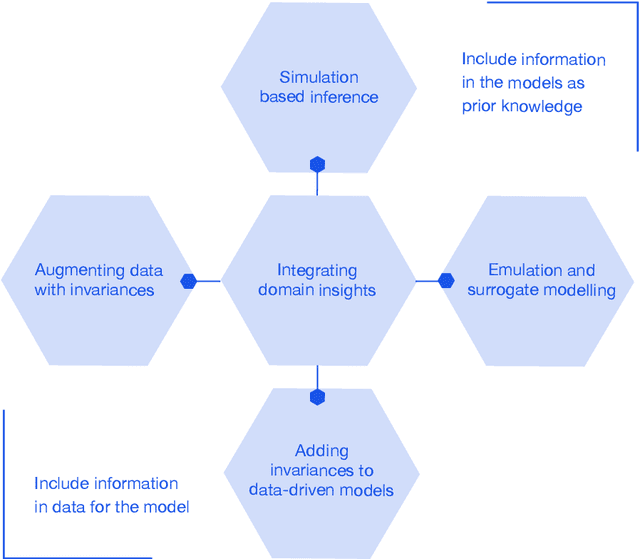
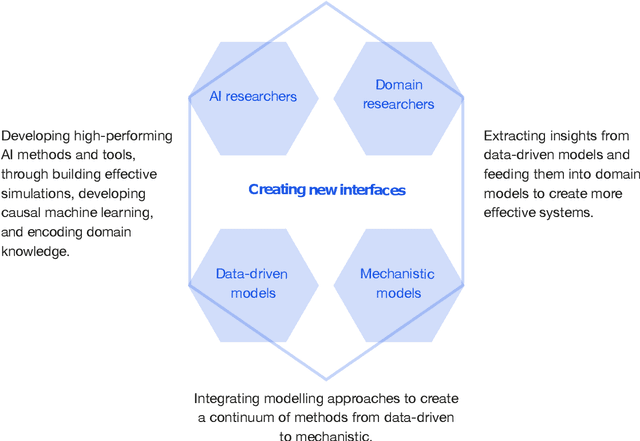
This report documents the programme and the outcomes of Dagstuhl Seminar 22382 "Machine Learning for Science: Bridging Data-Driven and Mechanistic Modelling". Today's scientific challenges are characterised by complexity. Interconnected natural, technological, and human systems are influenced by forces acting across time- and spatial-scales, resulting in complex interactions and emergent behaviours. Understanding these phenomena -- and leveraging scientific advances to deliver innovative solutions to improve society's health, wealth, and well-being -- requires new ways of analysing complex systems. The transformative potential of AI stems from its widespread applicability across disciplines, and will only be achieved through integration across research domains. AI for science is a rendezvous point. It brings together expertise from $\mathrm{AI}$ and application domains; combines modelling knowledge with engineering know-how; and relies on collaboration across disciplines and between humans and machines. Alongside technical advances, the next wave of progress in the field will come from building a community of machine learning researchers, domain experts, citizen scientists, and engineers working together to design and deploy effective AI tools. This report summarises the discussions from the seminar and provides a roadmap to suggest how different communities can collaborate to deliver a new wave of progress in AI and its application for scientific discovery.