 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimising for Energy Efficiency and Performance in Machine Learning
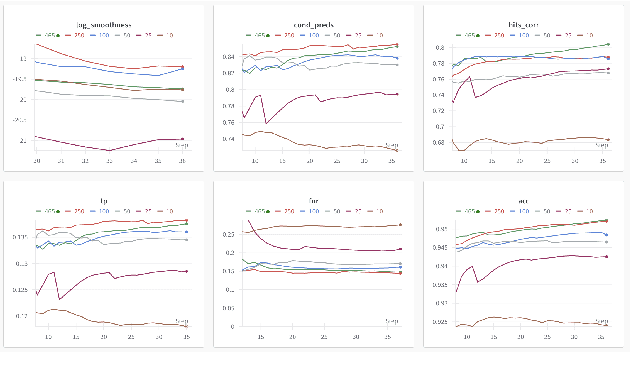
Jan 13, 2026The ubiquity of machine learning (ML) and the demand for ever-larger models bring an increase in energy consumption and environmental impact. However, little is known about the energy scaling laws in ML, and existing research focuses on training cost -- ignoring the larger cost of inference. Furthermore, tools for measuring the energy consumption of ML do not provide actionable feedback. To address these gaps, we developed Energy Consumption Optimiser (ECOpt): a hyperparameter tuner that optimises for energy efficiency and model performance. ECOpt quantifies the trade-off between these metrics as an interpretable Pareto frontier. This enables ML practitioners to make informed decisions about energy cost and environmental impact, while maximising the benefit of their models and complying with new regulations. Using ECOpt, we show that parameter and floating-point operation counts can be unreliable proxies for energy consumption, and observe that the energy efficiency of Transformer models for text generation is relatively consistent across hardware. These findings motivate measuring and publishing the energy metrics of ML models. We further show that ECOpt can have a net positive environmental impact and use it to uncover seven models for CIFAR-10 that improve upon the state of the art, when considering accuracy and energy efficiency together.
Transformers as Unrolled Inference in Probabilistic Laplacian Eigenmaps: An Interpretation and Potential Improvements
Jul 28, 2025We propose a probabilistic interpretation of transformers as unrolled inference steps assuming a probabilistic Laplacian Eigenmaps model from the ProbDR framework. Our derivation shows that at initialisation, transformers perform "linear" dimensionality reduction. We also show that within the transformer block, a graph Laplacian term arises from our arguments, rather than an attention matrix (which we interpret as an adjacency matrix). We demonstrate that simply subtracting the identity from the attention matrix (and thereby taking a graph diffusion step) improves validation performance on a language model and a simple vision transformer.
Prompt Variability Effects On LLM Code Generation
Jun 11, 2025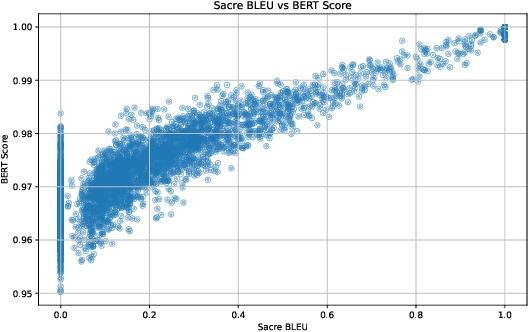



Code generation is one of the most active areas of application of Large Language Models (LLMs). While LLMs lower barriers to writing code and accelerate development process, the overall quality of generated programs depends on the quality of given prompts. Specifically, functionality and quality of generated code can be sensitive to user's background and familiarity with software development. It is therefore important to quantify LLM's sensitivity to variations in the input. To this end we propose a synthetic evaluation pipeline for code generation with LLMs, as well as a systematic persona-based evaluation approach to expose qualitative differences of LLM responses dependent on prospective user background. Both proposed methods are completely independent from specific programming tasks and LLMs, and thus are widely applicable. We provide experimental evidence illustrating utility of our methods and share our code for the benefit of the community.
The Systems Engineering Approach in Times of Large Language Models
Nov 13, 2024



Using Large Language Models (LLMs) to address critical societal problems requires adopting this novel technology into socio-technical systems. However, the complexity of such systems and the nature of LLMs challenge such a vision. It is unlikely that the solution to such challenges will come from the Artificial Intelligence (AI) community itself. Instead, the Systems Engineering approach is better equipped to facilitate the adoption of LLMs by prioritising the problems and their context before any other aspects. This paper introduces the challenges LLMs generate and surveys systems research efforts for engineering AI-based systems. We reveal how the systems engineering principles have supported addressing similar issues to the ones LLMs pose and discuss our findings to provide future directions for adopting LLMs.
On Feature Learning for Titi Monkey Activity Detection
Jul 01, 2024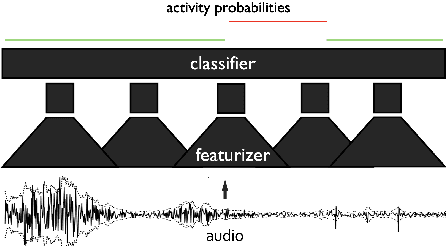
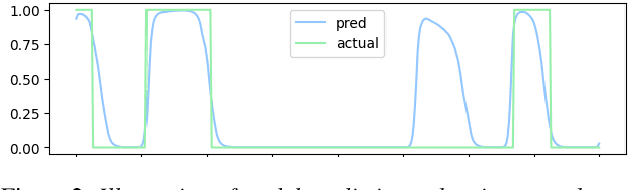
This paper, a technical summary of our preceding publication, introduces a robust machine learning framework for the detection of vocal activities of Coppery titi monkeys. Utilizing a combination of MFCC features and a bidirectional LSTM-based classifier, we effectively address the challenges posed by the small amount of expert-annotated vocal data available. Our approach significantly reduces false positives and improves the accuracy of call detection in bioacoustic research. Initial results demonstrate an accuracy of 95\% on instance predictions, highlighting the effectiveness of our model in identifying and classifying complex vocal patterns in environmental audio recordings. Moreover, we show how call classification can be done downstream, paving the way for real-world monitoring.
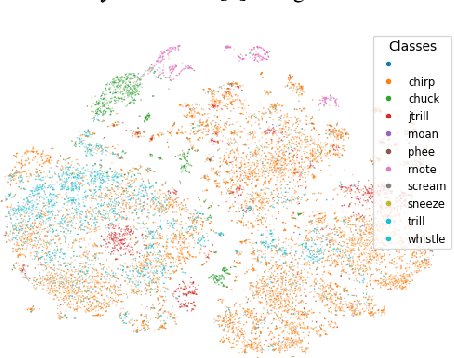
Towards One Model for Classical Dimensionality Reduction: A Probabilistic Perspective on UMAP and t-SNE
May 27, 2024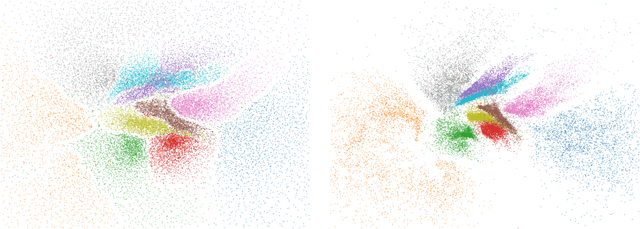
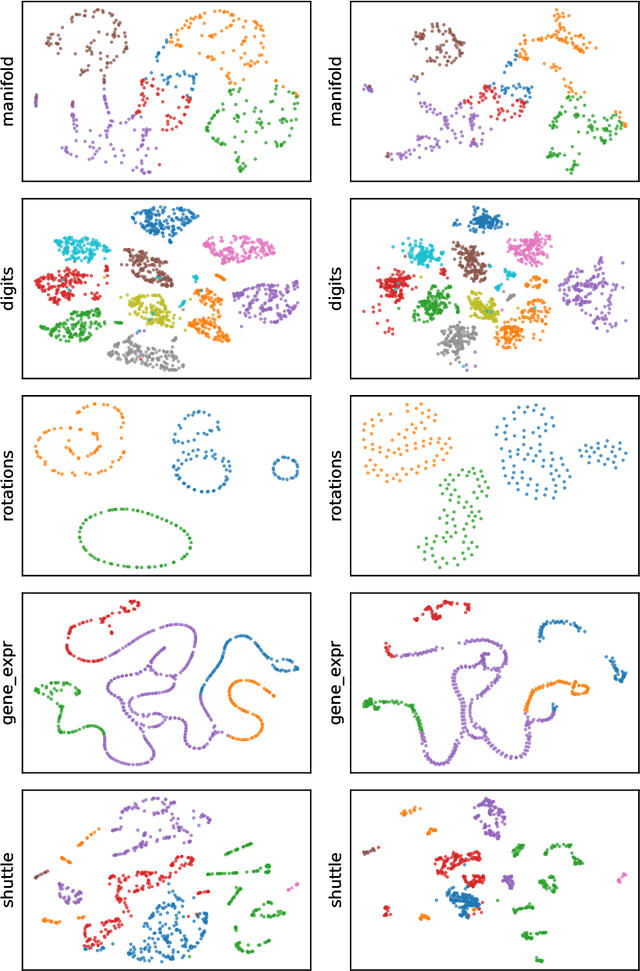
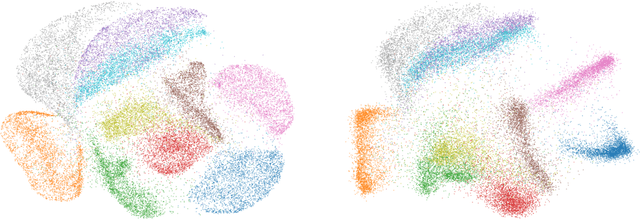
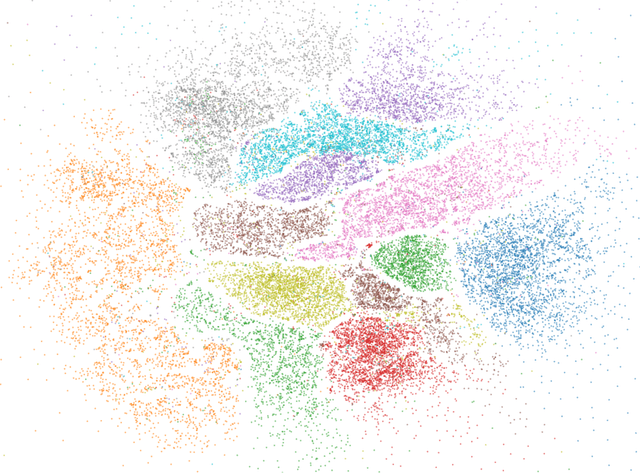
This paper shows that the dimensionality reduction methods, UMAP and t-SNE, can be approximately recast as MAP inference methods corresponding to a generalized Wishart-based model introduced in ProbDR. This interpretation offers deeper theoretical insights into these algorithms, while introducing tools with which similar dimensionality reduction methods can be studied.
Scalable Amortized GPLVMs for Single Cell Transcriptomics Data
May 06, 2024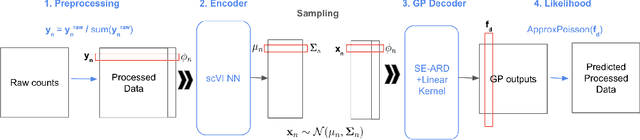
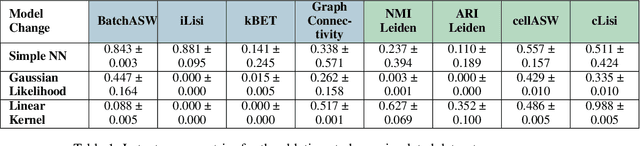

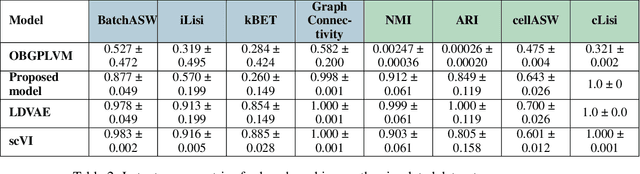
Dimensionality reduction is crucial for analyzing large-scale single-cell RNA-seq data. Gaussian Process Latent Variable Models (GPLVMs) offer an interpretable dimensionality reduction method, but current scalable models lack effectiveness in clustering cell types. We introduce an improved model, the amortized stochastic variational Bayesian GPLVM (BGPLVM), tailored for single-cell RNA-seq with specialized encoder, kernel, and likelihood designs. This model matches the performance of the leading single-cell variational inference (scVI) approach on synthetic and real-world COVID datasets and effectively incorporates cell-cycle and batch information to reveal more interpretable latent structures as we demonstrate on an innate immunity dataset.
Self-sustaining Software Systems (S4): Towards Improved Interpretability and Adaptation
Jan 21, 2024
Software systems impact society at different levels as they pervasively solve real-world problems. Modern software systems are often so sophisticated that their complexity exceeds the limits of human comprehension. These systems must respond to changing goals, dynamic data, unexpected failures, and security threats, among other variable factors in real-world environments. Systems' complexity challenges their interpretability and requires autonomous responses to dynamic changes. Two main research areas explore autonomous systems' responses: evolutionary computing and autonomic computing. Evolutionary computing focuses on software improvement based on iterative modifications to the source code. Autonomic computing focuses on optimising systems' performance by changing their structure, behaviour, or environment variables. Approaches from both areas rely on feedback loops that accumulate knowledge from the system interactions to inform autonomous decision-making. However, this knowledge is often limited, constraining the systems' interpretability and adaptability. This paper proposes a new concept for interpretable and adaptable software systems: self-sustaining software systems (S4). S4 builds knowledge loops between all available knowledge sources that define modern software systems to improve their interpretability and adaptability. This paper introduces and discusses the S4 concept.
Automated discovery of trade-off between utility, privacy and fairness in machine learning models
Nov 27, 2023Machine learning models are deployed as a central component in decision making and policy operations with direct impact on individuals' lives. In order to act ethically and comply with government regulations, these models need to make fair decisions and protect the users' privacy. However, such requirements can come with decrease in models' performance compared to their potentially biased, privacy-leaking counterparts. Thus the trade-off between fairness, privacy and performance of ML models emerges, and practitioners need a way of quantifying this trade-off to enable deployment decisions. In this work we interpret this trade-off as a multi-objective optimization problem, and propose PFairDP, a pipeline that uses Bayesian optimization for discovery of Pareto-optimal points between fairness, privacy and utility of ML models. We show how PFairDP can be used to replicate known results that were achieved through manual constraint setting process. We further demonstrate effectiveness of PFairDP with experiments on multiple models and datasets.
Causal fault localisation in dataflow systems
Apr 24, 2023Dataflow computing was shown to bring significant benefits to multiple niches of systems engineering and has the potential to become a general-purpose paradigm of choice for data-driven application development. One of the characteristic features of dataflow computing is the natural access to the dataflow graph of the entire system. Recently it has been observed that these dataflow graphs can be treated as complete graphical causal models, opening opportunities to apply causal inference techniques to dataflow systems. In this demonstration paper we aim to provide the first practical validation of this idea with a particular focus on causal fault localisation. We provide multiple demonstrations of how causal inference can be used to detect software bugs and data shifts in multiple scenarios with three modern dataflow engines.