 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimising for Energy Efficiency and Performance in Machine Learning
Jan 13, 2026The ubiquity of machine learning (ML) and the demand for ever-larger models bring an increase in energy consumption and environmental impact. However, little is known about the energy scaling laws in ML, and existing research focuses on training cost -- ignoring the larger cost of inference. Furthermore, tools for measuring the energy consumption of ML do not provide actionable feedback. To address these gaps, we developed Energy Consumption Optimiser (ECOpt): a hyperparameter tuner that optimises for energy efficiency and model performance. ECOpt quantifies the trade-off between these metrics as an interpretable Pareto frontier. This enables ML practitioners to make informed decisions about energy cost and environmental impact, while maximising the benefit of their models and complying with new regulations. Using ECOpt, we show that parameter and floating-point operation counts can be unreliable proxies for energy consumption, and observe that the energy efficiency of Transformer models for text generation is relatively consistent across hardware. These findings motivate measuring and publishing the energy metrics of ML models. We further show that ECOpt can have a net positive environmental impact and use it to uncover seven models for CIFAR-10 that improve upon the state of the art, when considering accuracy and energy efficiency together.
Surrogate-Based Differentiable Pipeline for Shape Optimization
Nov 13, 2025Gradient-based optimization of engineering designs is limited by non-differentiable components in the typical computer-aided engineering (CAE) workflow, which calculates performance metrics from design parameters. While gradient-based methods could provide noticeable speed-ups in high-dimensional design spaces, codes for meshing, physical simulations, and other common components are not differentiable even if the math or physics underneath them is. We propose replacing non-differentiable pipeline components with surrogate models which are inherently differentiable. Using a toy example of aerodynamic shape optimization, we demonstrate an end-to-end differentiable pipeline where a 3D U-Net full-field surrogate replaces both meshing and simulation steps by training it on the mapping between the signed distance field (SDF) of the shape and the fields of interest. This approach enables gradient-based shape optimization without the need for differentiable solvers, which can be useful in situations where adjoint methods are unavailable and/or hard to implement.
Prompt Variability Effects On LLM Code Generation
Jun 11, 2025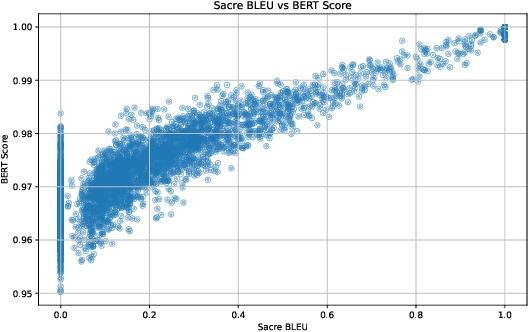



Code generation is one of the most active areas of application of Large Language Models (LLMs). While LLMs lower barriers to writing code and accelerate development process, the overall quality of generated programs depends on the quality of given prompts. Specifically, functionality and quality of generated code can be sensitive to user's background and familiarity with software development. It is therefore important to quantify LLM's sensitivity to variations in the input. To this end we propose a synthetic evaluation pipeline for code generation with LLMs, as well as a systematic persona-based evaluation approach to expose qualitative differences of LLM responses dependent on prospective user background. Both proposed methods are completely independent from specific programming tasks and LLMs, and thus are widely applicable. We provide experimental evidence illustrating utility of our methods and share our code for the benefit of the community.
LLM Performance for Code Generation on Noisy Tasks
May 29, 2025

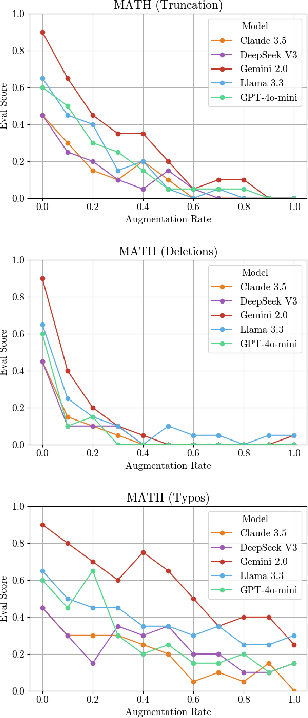

This paper investigates the ability of large language models (LLMs) to recognise and solve tasks which have been obfuscated beyond recognition. Focusing on competitive programming and benchmark tasks (LeetCode and MATH), we compare performance across multiple models and obfuscation methods, such as noise and redaction. We demonstrate that all evaluated LLMs can solve tasks obfuscated to a level where the text would be unintelligible to human readers, and does not contain key pieces of instruction or context. We introduce the concept of eager pattern matching to describe this behaviour, which is not observed in tasks published after the models' knowledge cutoff date, indicating strong memorisation or overfitting to training data, rather than legitimate reasoning about the presented problem. We report empirical evidence of distinct performance decay patterns between contaminated and unseen datasets. We discuss the implications for benchmarking and evaluations of model behaviour, arguing for caution when designing experiments using standard datasets. We also propose measuring the decay of performance under obfuscation as a possible strategy for detecting dataset contamination and highlighting potential safety risks and interpretability issues for automated software systems.
Self-sustaining Software Systems (S4): Towards Improved Interpretability and Adaptation
Jan 21, 2024
Software systems impact society at different levels as they pervasively solve real-world problems. Modern software systems are often so sophisticated that their complexity exceeds the limits of human comprehension. These systems must respond to changing goals, dynamic data, unexpected failures, and security threats, among other variable factors in real-world environments. Systems' complexity challenges their interpretability and requires autonomous responses to dynamic changes. Two main research areas explore autonomous systems' responses: evolutionary computing and autonomic computing. Evolutionary computing focuses on software improvement based on iterative modifications to the source code. Autonomic computing focuses on optimising systems' performance by changing their structure, behaviour, or environment variables. Approaches from both areas rely on feedback loops that accumulate knowledge from the system interactions to inform autonomous decision-making. However, this knowledge is often limited, constraining the systems' interpretability and adaptability. This paper proposes a new concept for interpretable and adaptable software systems: self-sustaining software systems (S4). S4 builds knowledge loops between all available knowledge sources that define modern software systems to improve their interpretability and adaptability. This paper introduces and discusses the S4 concept.
Automated discovery of trade-off between utility, privacy and fairness in machine learning models
Nov 27, 2023Machine learning models are deployed as a central component in decision making and policy operations with direct impact on individuals' lives. In order to act ethically and comply with government regulations, these models need to make fair decisions and protect the users' privacy. However, such requirements can come with decrease in models' performance compared to their potentially biased, privacy-leaking counterparts. Thus the trade-off between fairness, privacy and performance of ML models emerges, and practitioners need a way of quantifying this trade-off to enable deployment decisions. In this work we interpret this trade-off as a multi-objective optimization problem, and propose PFairDP, a pipeline that uses Bayesian optimization for discovery of Pareto-optimal points between fairness, privacy and utility of ML models. We show how PFairDP can be used to replicate known results that were achieved through manual constraint setting process. We further demonstrate effectiveness of PFairDP with experiments on multiple models and datasets.
Causal fault localisation in dataflow systems
Apr 24, 2023Dataflow computing was shown to bring significant benefits to multiple niches of systems engineering and has the potential to become a general-purpose paradigm of choice for data-driven application development. One of the characteristic features of dataflow computing is the natural access to the dataflow graph of the entire system. Recently it has been observed that these dataflow graphs can be treated as complete graphical causal models, opening opportunities to apply causal inference techniques to dataflow systems. In this demonstration paper we aim to provide the first practical validation of this idea with a particular focus on causal fault localisation. We provide multiple demonstrations of how causal inference can be used to detect software bugs and data shifts in multiple scenarios with three modern dataflow engines.
Dataflow graphs as complete causal graphs
Mar 16, 2023Component-based development is one of the core principles behind modern software engineering practices. Understanding of causal relationships between components of a software system can yield significant benefits to developers. Yet modern software design approaches make it difficult to track and discover such relationships at system scale, which leads to growing intellectual debt. In this paper we consider an alternative approach to software design, flow-based programming (FBP), and draw the attention of the community to the connection between dataflow graphs produced by FBP and structural causal models. With expository examples we show how this connection can be leveraged to improve day-to-day tasks in software projects, including fault localisation, business analysis and experimentation.
Trieste: Efficiently Exploring The Depths of Black-box Functions with TensorFlow
Feb 16, 2023We present Trieste, an open-source Python package for Bayesian optimization and active learning benefiting from the scalability and efficiency of TensorFlow. Our library enables the plug-and-play of popular TensorFlow-based models within sequential decision-making loops, e.g. Gaussian processes from GPflow or GPflux, or neural networks from Keras. This modular mindset is central to the package and extends to our acquisition functions and the internal dynamics of the decision-making loop, both of which can be tailored and extended by researchers or engineers when tackling custom use cases. Trieste is a research-friendly and production-ready toolkit backed by a comprehensive test suite, extensive documentation, and available at https://github.com/secondmind-labs/trieste.
Real-world Machine Learning Systems: A survey from a Data-Oriented Architecture Perspective
Feb 09, 2023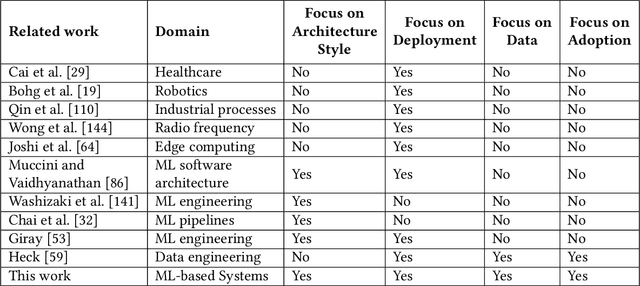
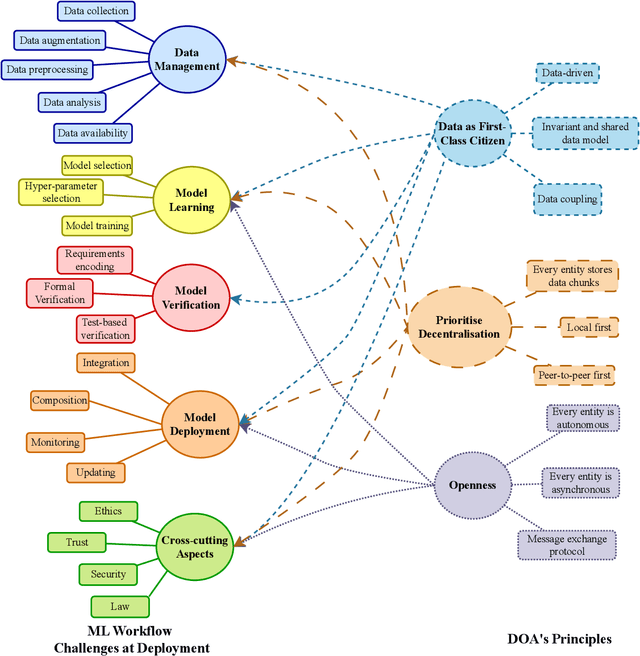


With the upsurge of interest in artificial intelligence machine learning (ML) algorithms, originally developed in academic environments, are now being deployed as parts of real-life systems that deal with large amounts of heterogeneous, dynamic, and high-dimensional data. Deployment of ML methods in real life is prone to challenges across the whole system life-cycle from data management to systems deployment, monitoring, and maintenance. Data-Oriented Architecture (DOA) is an emerging software engineering paradigm that has the potential to mitigate these challenges by proposing a set of principles to create data-driven, loosely coupled, decentralised, and open systems. However DOA as a concept is not widespread yet, and there is no common understanding of how it can be realised in practice. This review addresses that problem by contextualising the principles that underpin the DOA paradigm through the ML system challenges. We explore the extent to which current architectures of ML-based real-world systems have implemented the DOA principles. We also formulate open research challenges and directions for further development of the DOA paradigm.