 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrieste: Efficiently Exploring The Depths of Black-box Functions with TensorFlow
Feb 16, 2023We present Trieste, an open-source Python package for Bayesian optimization and active learning benefiting from the scalability and efficiency of TensorFlow. Our library enables the plug-and-play of popular TensorFlow-based models within sequential decision-making loops, e.g. Gaussian processes from GPflow or GPflux, or neural networks from Keras. This modular mindset is central to the package and extends to our acquisition functions and the internal dynamics of the decision-making loop, both of which can be tailored and extended by researchers or engineers when tackling custom use cases. Trieste is a research-friendly and production-ready toolkit backed by a comprehensive test suite, extensive documentation, and available at https://github.com/secondmind-labs/trieste.
Bellman: A Toolbox for Model-Based Reinforcement Learning in TensorFlow
Apr 13, 2021
In the past decade, model-free reinforcement learning (RL) has provided solutions to challenging domains such as robotics. Model-based RL shows the prospect of being more sample-efficient than model-free methods in terms of agent-environment interactions, because the model enables to extrapolate to unseen situations. In the more recent past, model-based methods have shown superior results compared to model-free methods in some challenging domains with non-linear state transitions. At the same time, it has become apparent that RL is not market-ready yet and that many real-world applications are going to require model-based approaches, because model-free methods are too sample-inefficient and show poor performance in early stages of training. The latter is particularly important in industry, e.g. in production systems that directly impact a company's revenue. This demonstrates the necessity for a toolbox to push the boundaries for model-based RL. While there is a plethora of toolboxes for model-free RL, model-based RL has received little attention in terms of toolbox development. Bellman aims to fill this gap and introduces the first thoroughly designed and tested model-based RL toolbox using state-of-the-art software engineering practices. Our modular approach enables to combine a wide range of environment models with generic model-based agent classes that recover state-of-the-art algorithms. We also provide an experiment harness to compare both model-free and model-based agents in a systematic fashion w.r.t. user-defined evaluation metrics (e.g. cumulative reward). This paves the way for new research directions, e.g. investigating uncertainty-aware environment models that are not necessarily neural-network-based, or developing algorithms to solve industrially-motivated benchmarks that share characteristics with real-world problems.
An empirical evaluation of active inference in multi-armed bandits
Jan 23, 2021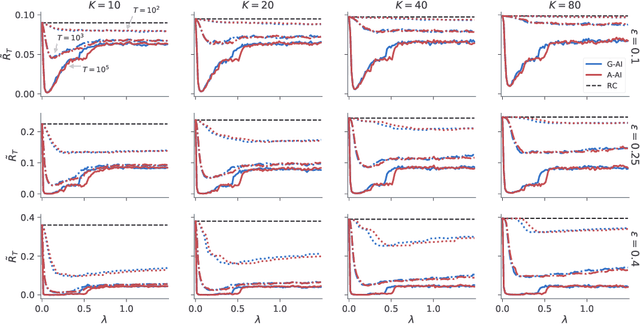
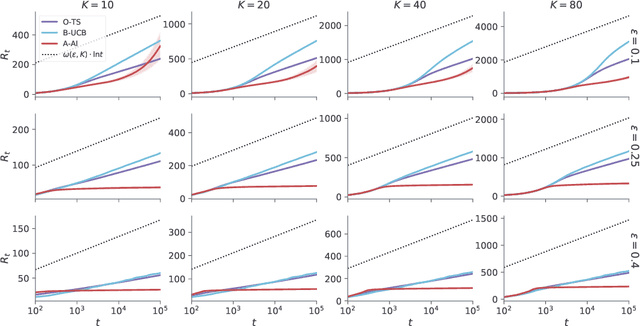
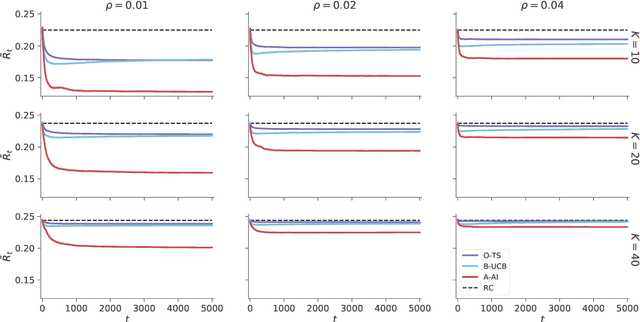
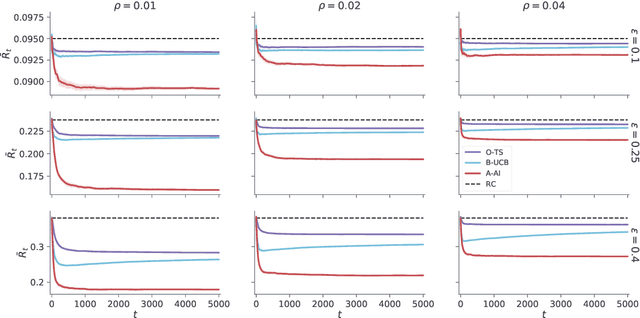
A key feature of sequential decision making under uncertainty is a need to balance between exploiting--choosing the best action according to the current knowledge, and exploring--obtaining information about values of other actions. The multi-armed bandit problem, a classical task that captures this trade-off, served as a vehicle in machine learning for developing bandit algorithms that proved to be useful in numerous industrial applications. The active inference framework, an approach to sequential decision making recently developed in neuroscience for understanding human and animal behaviour, is distinguished by its sophisticated strategy for resolving the exploration-exploitation trade-off. This makes active inference an exciting alternative to already established bandit algorithms. Here we derive an efficient and scalable approximate active inference algorithm and compare it to two state-of-the-art bandit algorithms: Bayesian upper confidence bound and optimistic Thompson sampling. This comparison is done on two types of bandit problems: a stationary and a dynamic switching bandit. Our empirical evaluation shows that the active inference algorithm does not produce efficient long-term behaviour in stationary bandits. However, in the more challenging switching bandit problem active inference performs substantially better than the two state-of-the-art bandit algorithms. The results open exciting venues for further research in theoretical and applied machine learning, as well as lend additional credibility to active inference as a general framework for studying human and animal behaviour.
Diversity of preferences can increase collective welfare in sequential exploration problems
Apr 03, 2017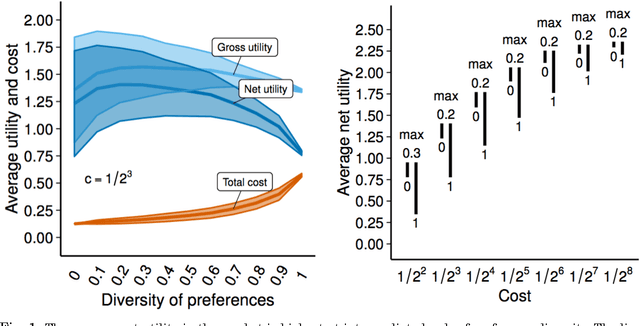
In search engines, online marketplaces and other human-computer interfaces large collectives of individuals sequentially interact with numerous alternatives of varying quality. In these contexts, trial and error (exploration) is crucial for uncovering novel high-quality items or solutions, but entails a high cost for individual users. Self-interested decision makers, are often better off imitating the choices of individuals who have already incurred the costs of exploration. Although imitation makes sense at the individual level, it deprives the group of additional information that could have been gleaned by individual explorers. In this paper we show that in such problems, preference diversity can function as a welfare enhancing mechanism. It leads to a consistent increase in the quality of the consumed alternatives that outweighs the increased cost of search for the users.