 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Anytime Pareto Set Identification for Multi-Objective Multi-Armed Bandits
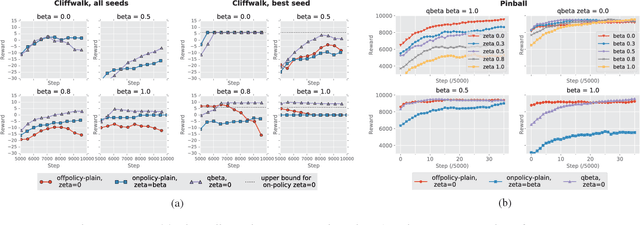
Jun 17, 2026Identifying Pareto optimal solutions is critical to support multi-objective decision-making. We introduce the first anytime Multi-Objective Multi-Armed Bandit algorithm for the Pareto Set Identification problem, taking a Bayesian approach: Top-Two Pareto Front Thompson Sampling (TTPFTS). We benchmark TTPFTS against state-of-the-art fixed-budget Pareto Set Identification algorithms on synthetic environments. Next, we demonstrate its practical utility in a challenging multi-objective molecular discovery setting by efficiently exploring an ultra-large synthesis-on-demand molecular library. Furthermore, we introduce a novel uncertainty quantification metric that estimates our algorithm's confidence in the predicted Pareto set. We demonstrate that this metric effectively proxies true performance, yielding a robust methodology for monitoring learning progress in complex settings. Finally, we complement these empirical findings with a theoretical proof of the algorithm's asymptotic correctness.
Bellman: A Toolbox for Model-Based Reinforcement Learning in TensorFlow
Apr 13, 2021
In the past decade, model-free reinforcement learning (RL) has provided solutions to challenging domains such as robotics. Model-based RL shows the prospect of being more sample-efficient than model-free methods in terms of agent-environment interactions, because the model enables to extrapolate to unseen situations. In the more recent past, model-based methods have shown superior results compared to model-free methods in some challenging domains with non-linear state transitions. At the same time, it has become apparent that RL is not market-ready yet and that many real-world applications are going to require model-based approaches, because model-free methods are too sample-inefficient and show poor performance in early stages of training. The latter is particularly important in industry, e.g. in production systems that directly impact a company's revenue. This demonstrates the necessity for a toolbox to push the boundaries for model-based RL. While there is a plethora of toolboxes for model-free RL, model-based RL has received little attention in terms of toolbox development. Bellman aims to fill this gap and introduces the first thoroughly designed and tested model-based RL toolbox using state-of-the-art software engineering practices. Our modular approach enables to combine a wide range of environment models with generic model-based agent classes that recover state-of-the-art algorithms. We also provide an experiment harness to compare both model-free and model-based agents in a systematic fashion w.r.t. user-defined evaluation metrics (e.g. cumulative reward). This paves the way for new research directions, e.g. investigating uncertainty-aware environment models that are not necessarily neural-network-based, or developing algorithms to solve industrially-motivated benchmarks that share characteristics with real-world problems.
Compatible features for Monotonic Policy Improvement
Oct 30, 2019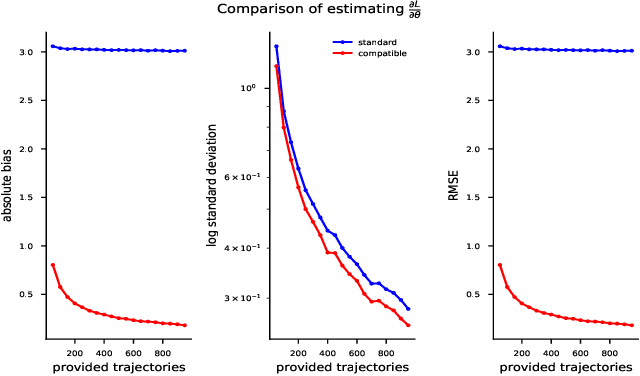
Recent policy optimization approaches have achieved substantial empirical success by constructing surrogate optimization objectives. The Approximate Policy Iteration objective (Schulman et al., 2015a; Kakade and Langford, 2002) has become a standard optimization target for reinforcement learning problems. Using this objective in practice requires an estimator of the advantage function. Policy optimization methods such as those proposed in Schulman et al. (2015b) estimate the advantages using a parametric critic. In this work we establish conditions under which the parametric approximation of the critic does not introduce bias to the updates of surrogate objective. These results hold for a general class of parametric policies, including deep neural networks. We obtain a result analogous to the compatible features derived for the original Policy Gradient Theorem (Sutton et al., 1999). As a result, we also identify a previously unknown bias that current state-of-the-art policy optimization algorithms (Schulman et al., 2015a, 2017) have introduced by not employing these compatible features.
Policy Optimization Through Approximated Importance Sampling
Oct 09, 2019
Recent policy optimization approaches (Schulman et al., 2015a, 2017) have achieved substantial empirical successes by constructing new proxy optimization objectives. These proxy objectives allow stable and low variance policy learning, but require small policy updates to ensure that the proxy objective remains an accurate approximation of the target policy value. In this paper we derive an alternative objective that obtains the value of the target policy by applying importance sampling. This objective can be directly estimated from samples, as it takes an expectation over trajectories generated by the current policy. However, the basic importance sampled objective is not suitable for policy optimization, as it incurs unacceptable variance. We therefore introduce an approximation that allows us to directly trade-off the bias of approximation with the variance in policy updates. We show that our approximation unifies the proxy optimization approaches with the importance sampling objective and allows us to interpolate between them. We then provide a theoretical analysis of the method that directly quantifies the error term due to the approximation. Finally, we obtain a practical algorithm by optimizing the introduced objective with proximal policy optimization techniques (Schulman etal., 2017). We empirically demonstrate that the result-ing algorithm yields superior performance on continuous control benchmarks
Disentangled Skill Embeddings for Reinforcement Learning
Jun 21, 2019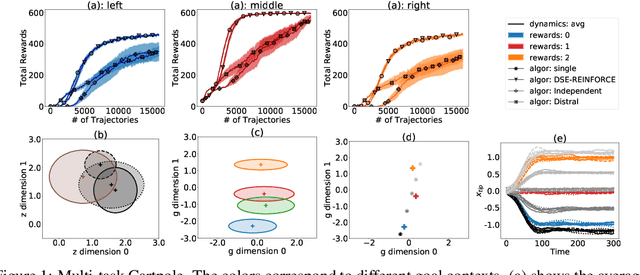

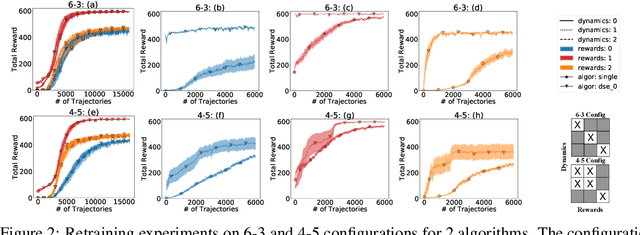
We propose a novel framework for multi-task reinforcement learning (MTRL). Using a variational inference formulation, we learn policies that generalize across both changing dynamics and goals. The resulting policies are parametrized by shared parameters that allow for transfer between different dynamics and goal conditions, and by task-specific latent-space embeddings that allow for specialization to particular tasks. We show how the latent-spaces enable generalization to unseen dynamics and goals conditions. Additionally, policies equipped with such embeddings serve as a space of skills (or options) for hierarchical reinforcement learning. Since we can change task dynamics and goals independently, we name our framework Disentangled Skill Embeddings (DSE).
Model-Based Stabilisation of Deep Reinforcement Learning
Sep 06, 2018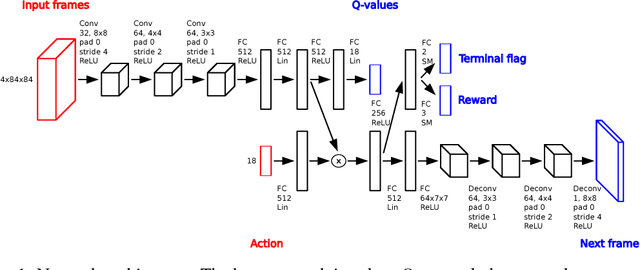
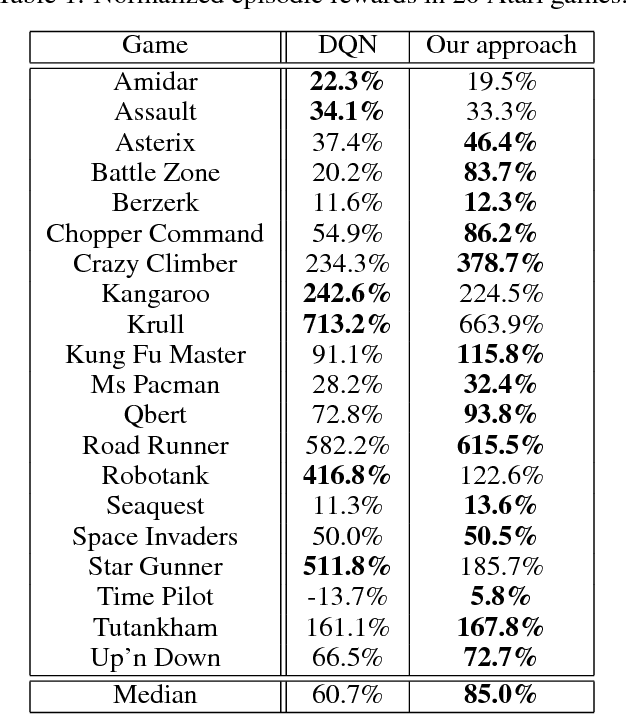
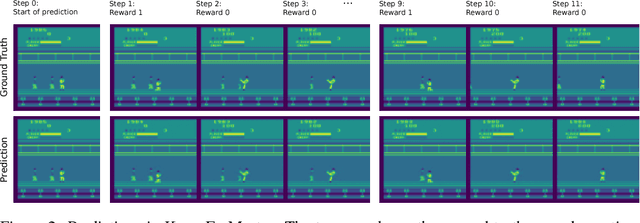
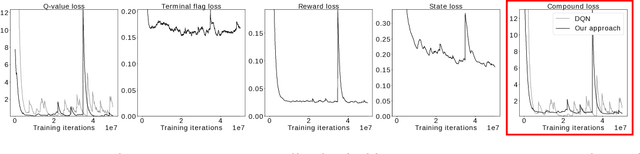
Though successful in high-dimensional domains, deep reinforcement learning exhibits high sample complexity and suffers from stability issues as reported by researchers and practitioners in the field. These problems hinder the application of such algorithms in real-world and safety-critical scenarios. In this paper, we take steps towards stable and efficient reinforcement learning by following a model-based approach that is known to reduce agent-environment interactions. Namely, our method augments deep Q-networks (DQNs) with model predictions for transitions, rewards, and termination flags. Having the model at hand, we then conduct a rigorous theoretical study of our algorithm and show, for the first time, convergence to a stationary point. En route, we provide a counter-example showing that 'vanilla' DQNs can diverge confirming practitioners' and researchers' experiences. Our proof is novel in its own right and can be extended to other forms of deep reinforcement learning. In particular, we believe exploiting the relation between reinforcement (with deep function approximators) and online learning can serve as a recipe for future proofs in the domain. Finally, we validate our theoretical results in 20 games from the Atari benchmark. Our results show that following the proposed model-based learning approach not only ensures convergence but leads to a reduction in sample complexity and superior performance.
Learning High-level Representations from Demonstrations
Feb 28, 2018
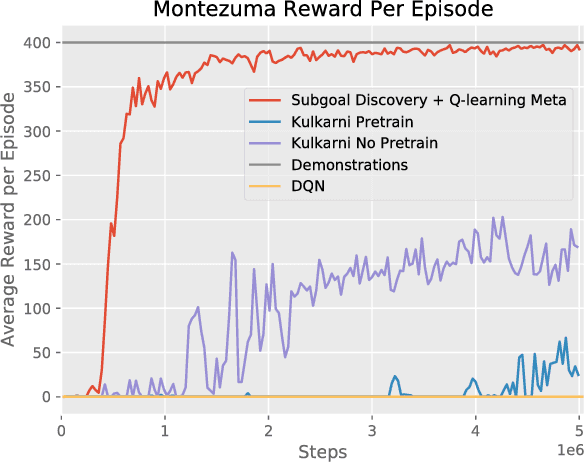
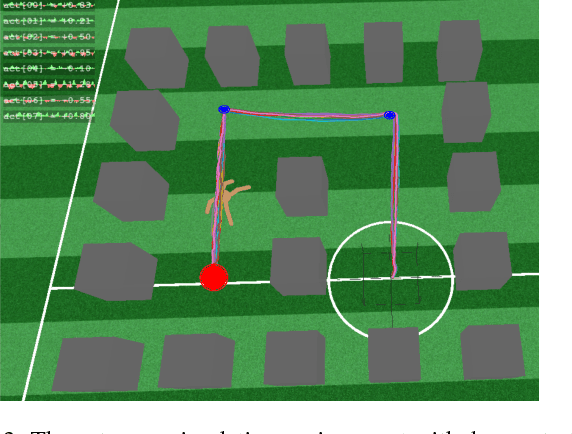
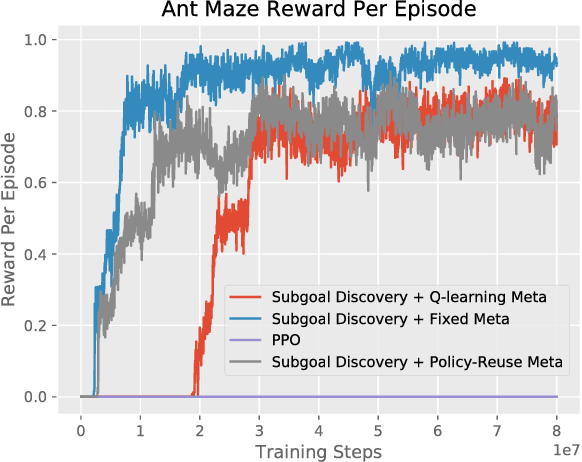
Hierarchical learning (HL) is key to solving complex sequential decision problems with long horizons and sparse rewards. It allows learning agents to break-up large problems into smaller, more manageable subtasks. A common approach to HL, is to provide the agent with a number of high-level skills that solve small parts of the overall problem. A major open question, however, is how to identify a suitable set of reusable skills. We propose a principled approach that uses human demonstrations to infer a set of subgoals based on changes in the demonstration dynamics. Using these subgoals, we decompose the learning problem into an abstract high-level representation and a set of low-level subtasks. The abstract description captures the overall problem structure, while subtasks capture desired skills. We demonstrate that we can jointly optimize over both levels of learning. We show that the resulting method significantly outperforms previous baselines on two challenging problems: the Atari 2600 game Montezuma's Revenge, and a simulated robotics problem moving the ant robot through a maze.
Forecasting day-ahead electricity prices in Europe: the importance of considering market integration
Dec 07, 2017
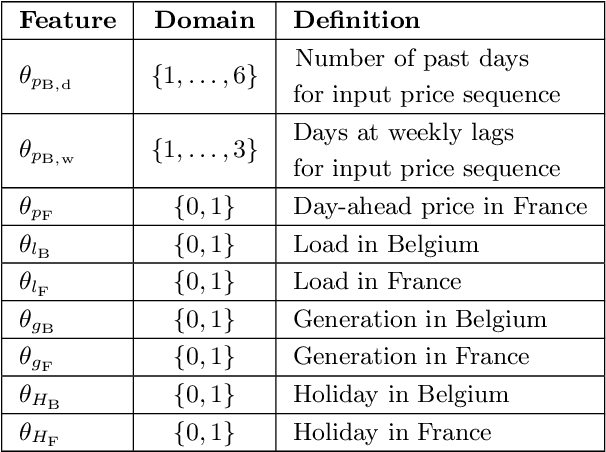
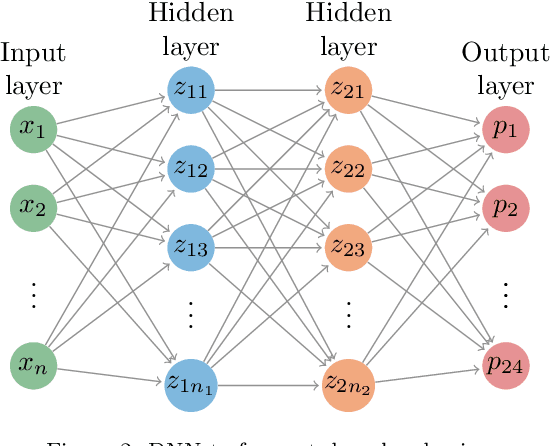

Motivated by the increasing integration among electricity markets, in this paper we propose two different methods to incorporate market integration in electricity price forecasting and to improve the predictive performance. First, we propose a deep neural network that considers features from connected markets to improve the predictive accuracy in a local market. To measure the importance of these features, we propose a novel feature selection algorithm that, by using Bayesian optimization and functional analysis of variance, evaluates the effect of the features on the algorithm performance. In addition, using market integration, we propose a second model that, by simultaneously predicting prices from two markets, improves the forecasting accuracy even further. As a case study, we consider the electricity market in Belgium and the improvements in forecasting accuracy when using various French electricity features. We show that the two proposed models lead to improvements that are statistically significant. Particularly, due to market integration, the predictive accuracy is improved from 15.7% to 12.5% sMAPE (symmetric mean absolute percentage error). In addition, we show that the proposed feature selection algorithm is able to perform a correct assessment, i.e. to discard the irrelevant features.
Learning with Options that Terminate Off-Policy
Dec 02, 2017
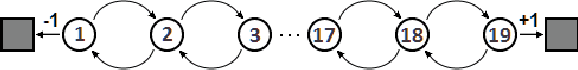
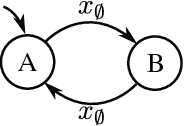
A temporally abstract action, or an option, is specified by a policy and a termination condition: the policy guides option behavior, and the termination condition roughly determines its length. Generally, learning with longer options (like learning with multi-step returns) is known to be more efficient. However, if the option set for the task is not ideal, and cannot express the primitive optimal policy exactly, shorter options offer more flexibility and can yield a better solution. Thus, the termination condition puts learning efficiency at odds with solution quality. We propose to resolve this dilemma by decoupling the behavior and target terminations, just like it is done with policies in off-policy learning. To this end, we give a new algorithm, Q(\beta), that learns the solution with respect to any termination condition, regardless of how the options actually terminate. We derive Q(\beta) by casting learning with options into a common framework with well-studied multi-step off-policy learning. We validate our algorithm empirically, and show that it holds up to its motivating claims.
Reinforcement Learning in POMDPs with Memoryless Options and Option-Observation Initiation Sets
Sep 12, 2017
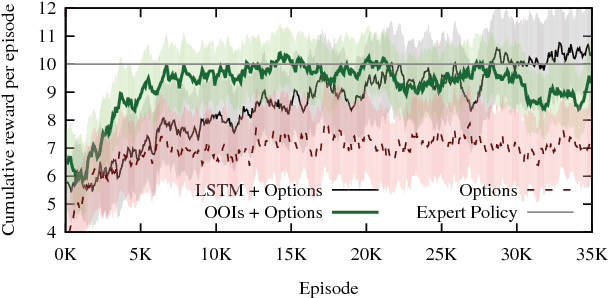
Many real-world reinforcement learning problems have a hierarchical nature, and often exhibit some degree of partial observability. While hierarchy and partial observability are usually tackled separately (for instance by combining recurrent neural networks and options), we show that addressing both problems simultaneously is simpler and more efficient in many cases. More specifically, we make the initiation set of options conditional on the previously-executed option, and show that options with such Option-Observation Initiation Sets (OOIs) are at least as expressive as Finite State Controllers (FSCs), a state-of-the-art approach for learning in POMDPs. OOIs are easy to design based on an intuitive description of the task, lead to explainable policies and keep the top-level and option policies memoryless. Our experiments show that OOIs allow agents to learn optimal policies in challenging POMDPs, while being much more sample-efficient than a recurrent neural network over options.