 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrieste: Efficiently Exploring The Depths of Black-box Functions with TensorFlow
Feb 16, 2023We present Trieste, an open-source Python package for Bayesian optimization and active learning benefiting from the scalability and efficiency of TensorFlow. Our library enables the plug-and-play of popular TensorFlow-based models within sequential decision-making loops, e.g. Gaussian processes from GPflow or GPflux, or neural networks from Keras. This modular mindset is central to the package and extends to our acquisition functions and the internal dynamics of the decision-making loop, both of which can be tailored and extended by researchers or engineers when tackling custom use cases. Trieste is a research-friendly and production-ready toolkit backed by a comprehensive test suite, extensive documentation, and available at https://github.com/secondmind-labs/trieste.
A Unified Bellman Optimality Principle Combining Reward Maximization and Empowerment
Sep 09, 2019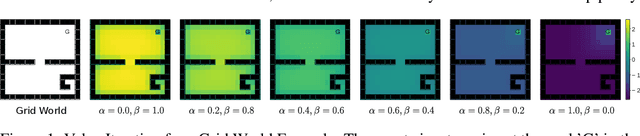
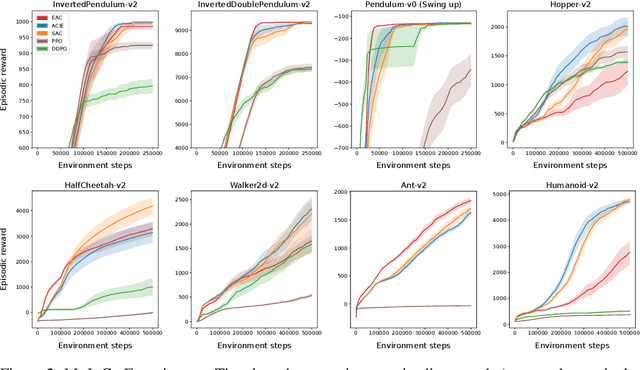
Empowerment is an information-theoretic method that can be used to intrinsically motivate learning agents. It attempts to maximize an agent's control over the environment by encouraging visiting states with a large number of reachable next states. Empowered learning has been shown to lead to complex behaviors, without requiring an explicit reward signal. In this paper, we investigate the use of empowerment in the presence of an extrinsic reward signal. We hypothesize that empowerment can guide reinforcement learning (RL) agents to find good early behavioral solutions by encouraging highly empowered states. We propose a unified Bellman optimality principle for empowered reward maximization. Our empowered reward maximization approach generalizes both Bellman's optimality principle as well as recent information-theoretical extensions to it. We prove uniqueness of the empowered values and show convergence to the optimal solution. We then apply this idea to develop off-policy actor-critic RL algorithms for high-dimensional continuous domains. We experimentally validate our methods in robotics domains (MuJoCo). Our methods demonstrate improved initial and competitive final performance compared to model-free state-of-the-art techniques.
Disentangled Skill Embeddings for Reinforcement Learning
Jun 21, 2019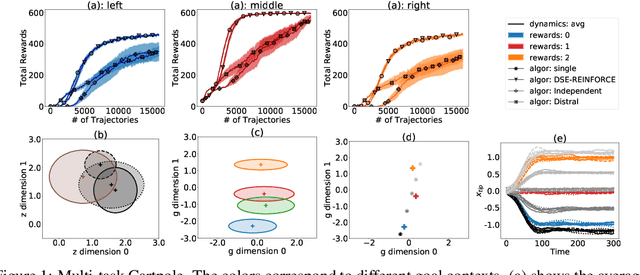

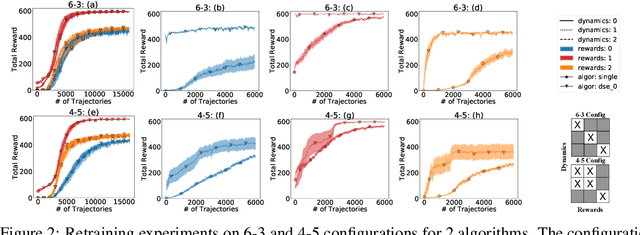
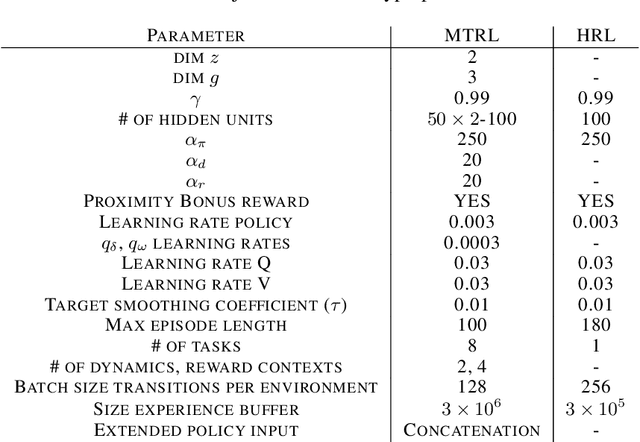
We propose a novel framework for multi-task reinforcement learning (MTRL). Using a variational inference formulation, we learn policies that generalize across both changing dynamics and goals. The resulting policies are parametrized by shared parameters that allow for transfer between different dynamics and goal conditions, and by task-specific latent-space embeddings that allow for specialization to particular tasks. We show how the latent-spaces enable generalization to unseen dynamics and goals conditions. Additionally, policies equipped with such embeddings serve as a space of skills (or options) for hierarchical reinforcement learning. Since we can change task dynamics and goals independently, we name our framework Disentangled Skill Embeddings (DSE).