 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to make the most of your masked language model for protein engineering
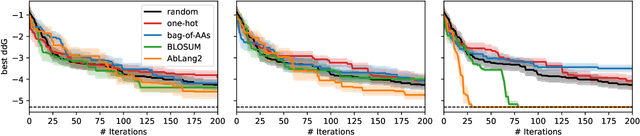
Mar 11, 2026A plethora of protein language models have been released in recent years. Yet comparatively little work has addressed how to best sample from them to optimize desired biological properties. We fill this gap by proposing a flexible, effective sampling method for masked language models (MLMs), and by systematically evaluating models and methods both in silico and in vitro on actual antibody therapeutics campaigns. Firstly, we propose sampling with stochastic beam search, exploiting the fact that MLMs are remarkably efficient at evaluating the pseudo-perplexity of the entire 1-edit neighborhood of a sequence. Reframing generation in terms of entire-sequence evaluation enables flexible guidance with multiple optimization objectives. Secondly, we report results from our extensive in vitro head-to-head evaluation for the antibody engineering setting. This reveals that choice of sampling method is at least as impactful as the model used, motivating future research into this under-explored area.
A Unification of Discrete, Gaussian, and Simplicial Diffusion
Dec 17, 2025To model discrete sequences such as DNA, proteins, and language using diffusion, practitioners must choose between three major methods: diffusion in discrete space, Gaussian diffusion in Euclidean space, or diffusion on the simplex. Despite their shared goal, these models have disparate algorithms, theoretical structures, and tradeoffs: discrete diffusion has the most natural domain, Gaussian diffusion has more mature algorithms, and diffusion on the simplex in principle combines the strengths of the other two but in practice suffers from a numerically unstable stochastic processes. Ideally we could see each of these models as instances of the same underlying framework, and enable practitioners to switch between models for downstream applications. However previous theories have only considered connections in special cases. Here we build a theory unifying all three methods of discrete diffusion as different parameterizations of the same underlying process: the Wright-Fisher population genetics model. In particular, we find simplicial and Gaussian diffusion as two large-population limits. Our theory formally connects the likelihoods and hyperparameters of these models and leverages decades of mathematical genetics literature to unlock stable simplicial diffusion. Finally, we relieve the practitioner of balancing model trade-offs by demonstrating it is possible to train a single model that can perform diffusion in any of these three domains at test time. Our experiments show that Wright-Fisher simplicial diffusion is more stable and outperforms previous simplicial diffusion models on conditional DNA generation. We also show that we can train models on multiple domains at once that are competitive with models trained on any individual domain.
Big Batch Bayesian Active Learning by Considering Predictive Probabilities
Jan 14, 2025

We observe that BatchBALD, a popular acquisition function for batch Bayesian active learning for classification, can conflate epistemic and aleatoric uncertainty, leading to suboptimal performance. Motivated by this observation, we propose to focus on the predictive probabilities, which only exhibit epistemic uncertainty. The result is an acquisition function that not only performs better, but is also faster to evaluate, allowing for larger batches than before.
Active learning for affinity prediction of antibodies
Jun 11, 2024


The primary objective of most lead optimization campaigns is to enhance the binding affinity of ligands. For large molecules such as antibodies, identifying mutations that enhance antibody affinity is particularly challenging due to the combinatorial explosion of potential mutations. When the structure of the antibody-antigen complex is available, relative binding free energy (RBFE) methods can offer valuable insights into how different mutations will impact the potency and selectivity of a drug candidate, thereby reducing the reliance on costly and time-consuming wet-lab experiments. However, accurately simulating the physics of large molecules is computationally intensive. We present an active learning framework that iteratively proposes promising sequences for simulators to evaluate, thereby accelerating the search for improved binders. We explore different modeling approaches to identify the most effective surrogate model for this task, and evaluate our framework both using pre-computed pools of data and in a realistic full-loop setting.
Recommendations for Baselines and Benchmarking Approximate Gaussian Processes
Feb 15, 2024



Gaussian processes (GPs) are a mature and widely-used component of the ML toolbox. One of their desirable qualities is automatic hyperparameter selection, which allows for training without user intervention. However, in many realistic settings, approximations are typically needed, which typically do require tuning. We argue that this requirement for tuning complicates evaluation, which has led to a lack of a clear recommendations on which method should be used in which situation. To address this, we make recommendations for comparing GP approximations based on a specification of what a user should expect from a method. In addition, we develop a training procedure for the variational method of Titsias [2009] that leaves no choices to the user, and show that this is a strong baseline that meets our specification. We conclude that benchmarking according to our suggestions gives a clearer view of the current state of the field, and uncovers problems that are still open that future papers should address.
Towards Improved Variational Inference for Deep Bayesian Models
Jan 23, 2024Deep learning has revolutionized the last decade, being at the forefront of extraordinary advances in a wide range of tasks including computer vision, natural language processing, and reinforcement learning, to name but a few. However, it is well-known that deep models trained via maximum likelihood estimation tend to be overconfident and give poorly-calibrated predictions. Bayesian deep learning attempts to address this by placing priors on the model parameters, which are then combined with a likelihood to perform posterior inference. Unfortunately, for deep models, the true posterior is intractable, forcing the user to resort to approximations. In this thesis, we explore the use of variational inference (VI) as an approximation, as it is unique in simultaneously approximating the posterior and providing a lower bound to the marginal likelihood. If tight enough, this lower bound can be used to optimize hyperparameters and to facilitate model selection. However, this capacity has rarely been used to its full extent for Bayesian neural networks, likely because the approximate posteriors typically used in practice can lack the flexibility to effectively bound the marginal likelihood. We therefore explore three aspects of Bayesian learning for deep models: 1) we ask whether it is necessary to perform inference over as many parameters as possible, or whether it is reasonable to treat many of them as optimizable hyperparameters; 2) we propose a variational posterior that provides a unified view of inference in Bayesian neural networks and deep Gaussian processes; 3) we demonstrate how VI can be improved in certain deep Gaussian process models by analytically removing symmetries from the posterior, and performing inference on Gram matrices instead of features. We hope that our contributions will provide a stepping stone to fully realize the promises of VI in the future.
Trieste: Efficiently Exploring The Depths of Black-box Functions with TensorFlow
Feb 16, 2023We present Trieste, an open-source Python package for Bayesian optimization and active learning benefiting from the scalability and efficiency of TensorFlow. Our library enables the plug-and-play of popular TensorFlow-based models within sequential decision-making loops, e.g. Gaussian processes from GPflow or GPflux, or neural networks from Keras. This modular mindset is central to the package and extends to our acquisition functions and the internal dynamics of the decision-making loop, both of which can be tailored and extended by researchers or engineers when tackling custom use cases. Trieste is a research-friendly and production-ready toolkit backed by a comprehensive test suite, extensive documentation, and available at https://github.com/secondmind-labs/trieste.
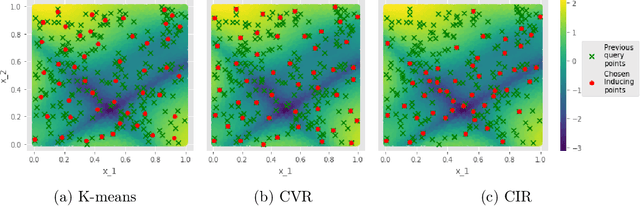
Inducing Point Allocation for Sparse Gaussian Processes in High-Throughput Bayesian Optimisation
Jan 24, 2023Sparse Gaussian Processes are a key component of high-throughput Bayesian Optimisation (BO) loops; however, we show that existing methods for allocating their inducing points severely hamper optimisation performance. By exploiting the quality-diversity decomposition of Determinantal Point Processes, we propose the first inducing point allocation strategy designed specifically for use in BO. Unlike existing methods which seek only to reduce global uncertainty in the objective function, our approach provides the local high-fidelity modelling of promising regions required for precise optimisation. More generally, we demonstrate that our proposed framework provides a flexible way to allocate modelling capacity in sparse models and so is suitable broad range of downstream sequential decision making tasks.
Information-theoretic Inducing Point Placement for High-throughput Bayesian Optimisation
Jun 06, 2022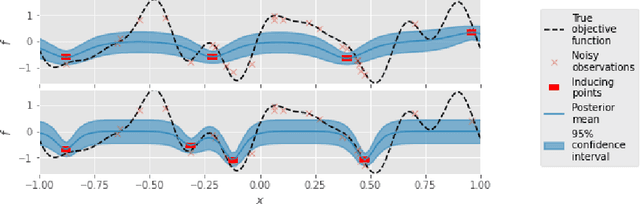
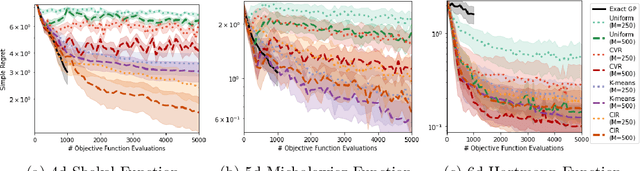
Sparse Gaussian Processes are a key component of high-throughput Bayesian optimisation (BO) loops -- an increasingly common setting where evaluation budgets are large and highly parallelised. By using representative subsets of the available data to build approximate posteriors, sparse models dramatically reduce the computational costs of surrogate modelling by relying on a small set of pseudo-observations, the so-called inducing points, in lieu of the full data set. However, current approaches to design inducing points are not appropriate within BO loops as they seek to reduce global uncertainty in the objective function. Thus, the high-fidelity modelling of promising and data-dense regions required for precise optimisation is sacrificed and computational resources are instead wasted on modelling areas of the space already known to be sub-optimal. Inspired by entropy-based BO methods, we propose a novel inducing point design that uses a principled information-theoretic criterion to select inducing points. By choosing inducing points to maximally reduce both global uncertainty and uncertainty in the maximum value of the objective function, we build surrogate models able to support high-precision high-throughput BO.
A variational approximate posterior for the deep Wishart process
Jul 21, 2021
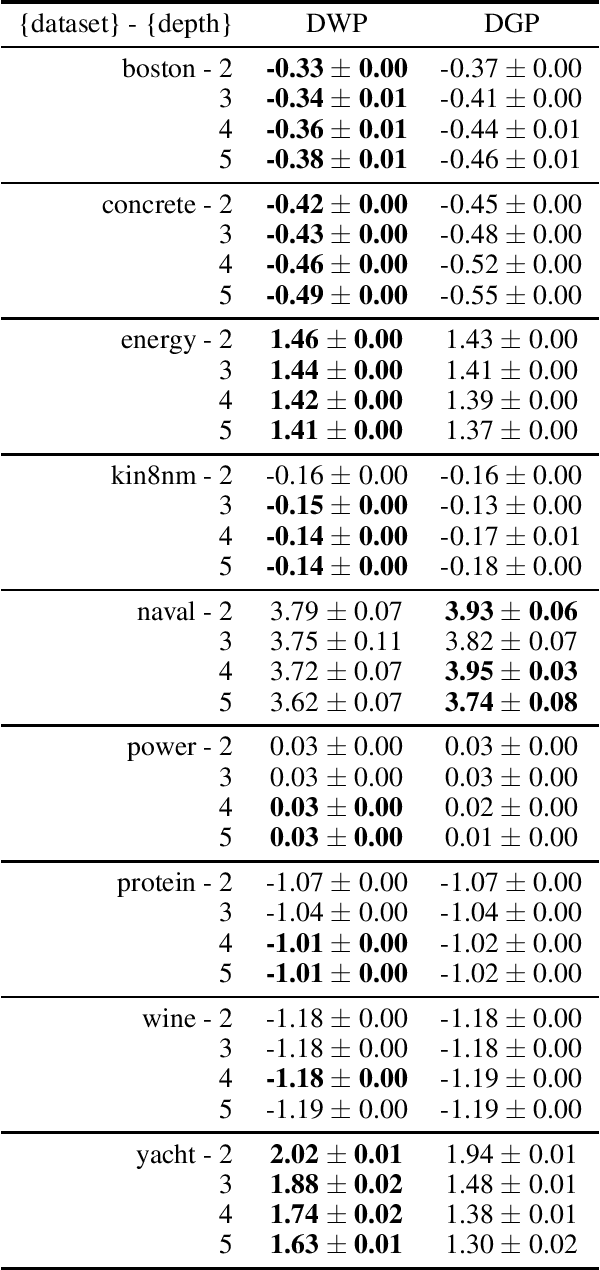

Recent work introduced deep kernel processes as an entirely kernel-based alternative to NNs (Aitchison et al. 2020). Deep kernel processes flexibly learn good top-layer representations by alternately sampling the kernel from a distribution over positive semi-definite matrices and performing nonlinear transformations. A particular deep kernel process, the deep Wishart process (DWP), is of particular interest because its prior is equivalent to deep Gaussian process (DGP) priors. However, inference in DWPs has not yet been possible due to the lack of sufficiently flexible distributions over positive semi-definite matrices. Here, we give a novel approach to obtaining flexible distributions over positive semi-definite matrices by generalising the Bartlett decomposition of the Wishart probability density. We use this new distribution to develop an approximate posterior for the DWP that includes dependency across layers. We develop a doubly-stochastic inducing-point inference scheme for the DWP and show experimentally that inference in the DWP gives improved performance over doing inference in a DGP with the equivalent prior.