 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Promises and Pitfalls of Deep Kernel Learning
Paper and Code


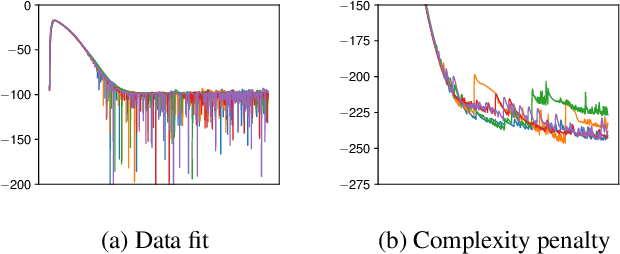
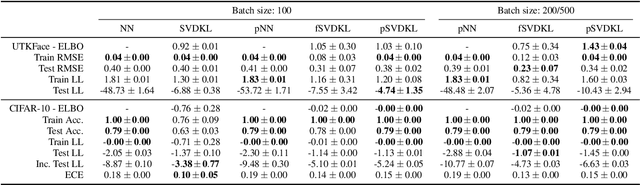
Deep kernel learning and related techniques promise to combine the representational power of neural networks with the reliable uncertainty estimates of Gaussian processes. One crucial aspect of these models is an expectation that, because they are treated as Gaussian process models optimized using the marginal likelihood, they are protected from overfitting. However, we identify pathological behavior, including overfitting, on a simple toy example. We explore this pathology, explaining its origins and considering how it applies to real datasets. Through careful experimentation on UCI datasets, CIFAR-10, and the UTKFace dataset, we find that the overfitting from overparameterized deep kernel learning, in which the model is "somewhat Bayesian", can in certain scenarios be worse than that from not being Bayesian at all. However, we find that a fully Bayesian treatment of deep kernel learning can rectify this overfitting and obtain the desired performance improvements over standard neural networks and Gaussian processes.