 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse-Free Sparse Variational Gaussian Processes
Apr 01, 2026Gaussian processes (GPs) offer appealing properties but are costly to train at scale. Sparse variational GP (SVGP) approximations reduce cost yet still rely on Cholesky decompositions of kernel matrices, ill-suited to low-precision, massively parallel hardware. While one can construct valid variational bounds that rely only on matrix multiplications (matmuls) via an auxiliary matrix parameter, optimising them with off-the-shelf first-order methods is challenging. We make the inverse-free approach practical by proposing a better-conditioned bound and deriving a matmul-only natural-gradient update for the auxiliary parameter, markedly improving stability and convergence. We further provide simple heuristics, such as step-size schedules and stopping criteria, that make the overall optimisation routine fit seamlessly into existing workflows. Across regression and classification benchmarks, we demonstrate that our method 1) serves as a drop-in replacement in SVGP-based models (e.g., deep GPs), 2) recovers similar performance to traditional methods, and 3) can be faster than baselines when well tuned.
Use What You Know: Causal Foundation Models with Partial Graphs
Feb 16, 2026Estimating causal quantities traditionally relies on bespoke estimators tailored to specific assumptions. Recently proposed Causal Foundation Models (CFMs) promise a more unified approach by amortising causal discovery and inference in a single step. However, in their current state, they do not allow for the incorporation of any domain knowledge, which can lead to suboptimal predictions. We bridge this gap by introducing methods to condition CFMs on causal information, such as the causal graph or more readily available ancestral information. When access to complete causal graph information is too strict a requirement, our approach also effectively leverages partial causal information. We systematically evaluate conditioning strategies and find that injecting learnable biases into the attention mechanism is the most effective method to utilise full and partial causal information. Our experiments show that this conditioning allows a general-purpose CFM to match the performance of specialised models trained on specific causal structures. Overall, our approach addresses a central hurdle on the path towards all-in-one causal foundation models: the capability to answer causal queries in a data-driven manner while effectively leveraging any amount of domain expertise.
PSyDUCK: Training-Free Steganography for Latent Diffusion
Jan 31, 2025



Recent advances in AI-generated steganography highlight its potential for safeguarding the privacy of vulnerable democratic actors, including aid workers, journalists, and whistleblowers operating in oppressive regimes. In this work, we address current limitations and establish the foundations for large-throughput generative steganography. We introduce a novel approach that enables secure and efficient steganography within latent diffusion models. We show empirically that our methods perform well across a variety of open-source latent diffusion models, particularly in generative image and video tasks.
Rethinking Aleatoric and Epistemic Uncertainty
Dec 30, 2024

The ideas of aleatoric and epistemic uncertainty are widely used to reason about the probabilistic predictions of machine-learning models. We identify incoherence in existing discussions of these ideas and suggest this stems from the aleatoric-epistemic view being insufficiently expressive to capture all of the distinct quantities that researchers are interested in. To explain and address this we derive a simple delineation of different model-based uncertainties and the data-generating processes associated with training and evaluation. Using this in place of the aleatoric-epistemic view could produce clearer discourse as the field moves forward.
A Meta-Learning Approach to Bayesian Causal Discovery
Dec 21, 2024



Discovering a unique causal structure is difficult due to both inherent identifiability issues, and the consequences of finite data. As such, uncertainty over causal structures, such as those obtained from a Bayesian posterior, are often necessary for downstream tasks. Finding an accurate approximation to this posterior is challenging, due to the large number of possible causal graphs, as well as the difficulty in the subproblem of finding posteriors over the functional relationships of the causal edges. Recent works have used meta-learning to view the problem of estimating the maximum a-posteriori causal graph as supervised learning. Yet, these methods are limited when estimating the full posterior as they fail to encode key properties of the posterior, such as correlation between edges and permutation equivariance with respect to nodes. Further, these methods also cannot reliably sample from the posterior over causal structures. To address these limitations, we propose a Bayesian meta learning model that allows for sampling causal structures from the posterior and encodes these key properties. We compare our meta-Bayesian causal discovery against existing Bayesian causal discovery methods, demonstrating the advantages of directly learning a posterior over causal structure.
Continuous Bayesian Model Selection for Multivariate Causal Discovery
Nov 15, 2024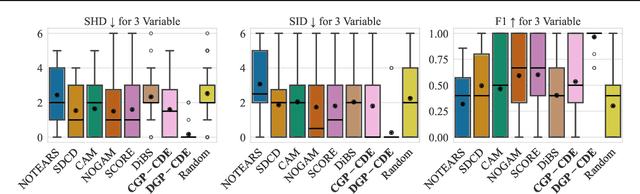

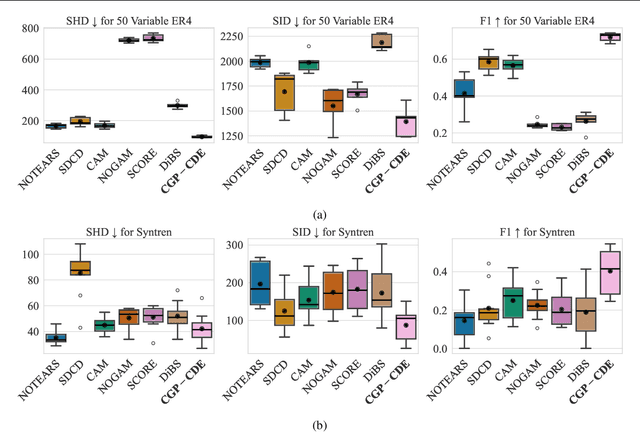
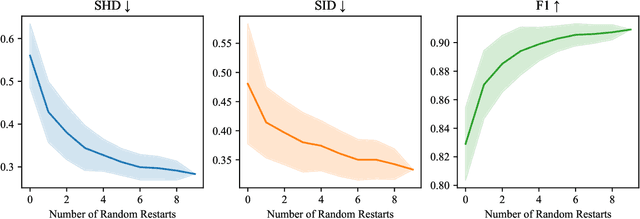
Current causal discovery approaches require restrictive model assumptions or assume access to interventional data to ensure structure identifiability. These assumptions often do not hold in real-world applications leading to a loss of guarantees and poor accuracy in practice. Recent work has shown that, in the bivariate case, Bayesian model selection can greatly improve accuracy by exchanging restrictive modelling for more flexible assumptions, at the cost of a small probability of error. We extend the Bayesian model selection approach to the important multivariate setting by making the large discrete selection problem scalable through a continuous relaxation. We demonstrate how for our choice of Bayesian non-parametric model, the Causal Gaussian Process Conditional Density Estimator (CGP-CDE), an adjacency matrix can be constructed from the model hyperparameters. This adjacency matrix is then optimised using the marginal likelihood and an acyclicity regulariser, outputting the maximum a posteriori causal graph. We demonstrate the competitiveness of our approach on both synthetic and real-world datasets, showing it is possible to perform multivariate causal discovery without infeasible assumptions using Bayesian model selection.
Noether's razor: Learning Conserved Quantities
Oct 10, 2024Symmetries have proven useful in machine learning models, improving generalisation and overall performance. At the same time, recent advancements in learning dynamical systems rely on modelling the underlying Hamiltonian to guarantee the conservation of energy. These approaches can be connected via a seminal result in mathematical physics: Noether's theorem, which states that symmetries in a dynamical system correspond to conserved quantities. This work uses Noether's theorem to parameterise symmetries as learnable conserved quantities. We then allow conserved quantities and associated symmetries to be learned directly from train data through approximate Bayesian model selection, jointly with the regular training procedure. As training objective, we derive a variational lower bound to the marginal likelihood. The objective automatically embodies an Occam's Razor effect that avoids collapse of conservation laws to the trivial constant, without the need to manually add and tune additional regularisers. We demonstrate a proof-of-principle on $n$-harmonic oscillators and $n$-body systems. We find that our method correctly identifies the correct conserved quantities and U($n$) and SE($n$) symmetry groups, improving overall performance and predictive accuracy on test data.
"How Big is Big Enough?" Adjusting Model Size in Continual Gaussian Processes
Aug 14, 2024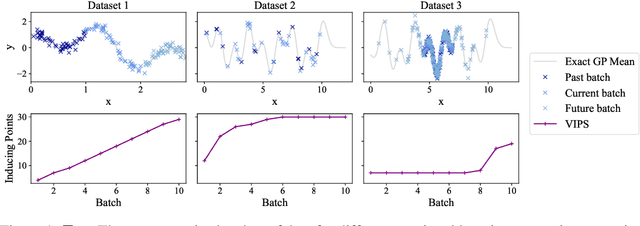



For many machine learning methods, creating a model requires setting a parameter that controls the model's capacity before training, e.g.~number of neurons in DNNs, or inducing points in GPs. Increasing capacity improves performance until all the information from the dataset is captured. After this point, computational cost keeps increasing, without improved performance. This leads to the question ``How big is big enough?'' We investigate this problem for Gaussian processes (single-layer neural networks) in continual learning. Here, data becomes available incrementally, and the final dataset size will therefore not be known before training, preventing the use of heuristics for setting the model size. We provide a method that automatically adjusts this, while maintaining near-optimal performance, and show that a single hyperparameter setting for our method performs well across datasets with a wide range of properties.
Variational Inference Failures Under Model Symmetries: Permutation Invariant Posteriors for Bayesian Neural Networks
Aug 10, 2024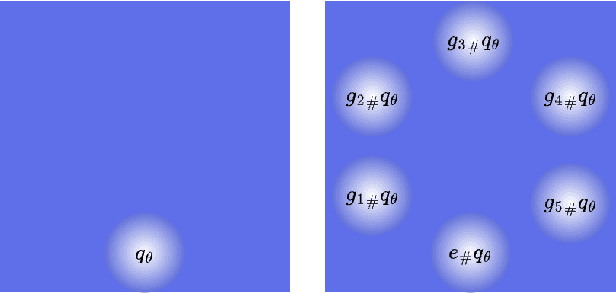

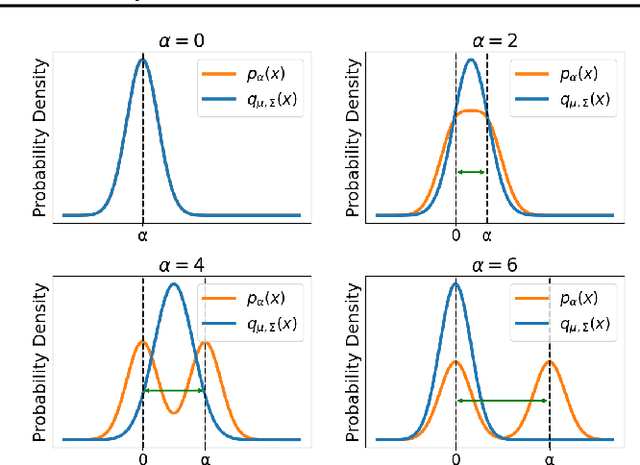
Weight space symmetries in neural network architectures, such as permutation symmetries in MLPs, give rise to Bayesian neural network (BNN) posteriors with many equivalent modes. This multimodality poses a challenge for variational inference (VI) techniques, which typically rely on approximating the posterior with a unimodal distribution. In this work, we investigate the impact of weight space permutation symmetries on VI. We demonstrate, both theoretically and empirically, that these symmetries lead to biases in the approximate posterior, which degrade predictive performance and posterior fit if not explicitly accounted for. To mitigate this behavior, we leverage the symmetric structure of the posterior and devise a symmetrization mechanism for constructing permutation invariant variational posteriors. We show that the symmetrized distribution has a strictly better fit to the true posterior, and that it can be trained using the original ELBO objective with a modified KL regularization term. We demonstrate experimentally that our approach mitigates the aforementioned biases and results in improved predictions and a higher ELBO.
System-Aware Neural ODE Processes for Few-Shot Bayesian Optimization
Jun 04, 2024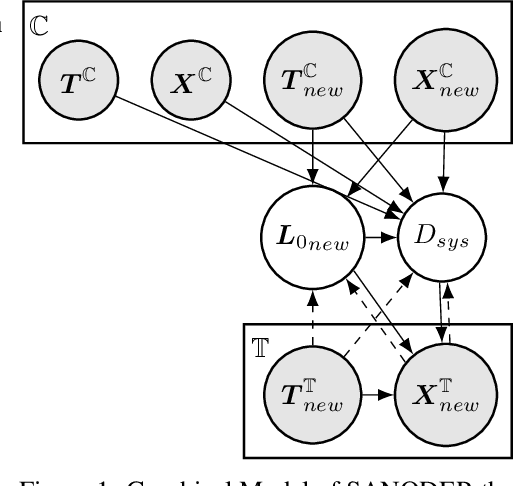



We consider the problem of optimizing initial conditions and timing in dynamical systems governed by unknown ordinary differential equations (ODEs), where evaluating different initial conditions is costly and there are constraints on observation times. To identify the optimal conditions within several trials, we introduce a few-shot Bayesian Optimization (BO) framework based on the system's prior information. At the core of our approach is the System-Aware Neural ODE Processes (SANODEP), an extension of Neural ODE Processes (NODEP) designed to meta-learn ODE systems from multiple trajectories using a novel context embedding block. Additionally, we propose a multi-scenario loss function specifically for optimization purposes. Our two-stage BO framework effectively incorporates search space constraints, enabling efficient optimization of both initial conditions and observation timings. We conduct extensive experiments showcasing SANODEP's potential for few-shot BO. We also explore SANODEP's adaptability to varying levels of prior information, highlighting the trade-off between prior flexibility and model fitting accuracy.