 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decision-Theoretic Formalisation of Steganography With Applications to LLM Monitoring
Feb 26, 2026Large language models are beginning to show steganographic capabilities. Such capabilities could allow misaligned models to evade oversight mechanisms. Yet principled methods to detect and quantify such behaviours are lacking. Classical definitions of steganography, and detection methods based on them, require a known reference distribution of non-steganographic signals. For the case of steganographic reasoning in LLMs, knowing such a reference distribution is not feasible; this renders these approaches inapplicable. We propose an alternative, \textbf{decision-theoretic view of steganography}. Our central insight is that steganography creates an asymmetry in usable information between agents who can and cannot decode the hidden content (present within a steganographic signal), and this otherwise latent asymmetry can be inferred from the agents' observable actions. To formalise this perspective, we introduce generalised $\mathcal{V}$-information: a utilitarian framework for measuring the amount of usable information within some input. We use this to define the \textbf{steganographic gap} -- a measure that quantifies steganography by comparing the downstream utility of the steganographic signal to agents that can and cannot decode the hidden content. We empirically validate our formalism, and show that it can be used to detect, quantify, and mitigate steganographic reasoning in LLMs.
Towards Understanding Multimodal Fine-Tuning: Spatial Features
Feb 06, 2026Contemporary Vision-Language Models (VLMs) achieve strong performance on a wide range of tasks by pairing a vision encoder with a pre-trained language model, fine-tuned for visual-text inputs. Yet despite these gains, it remains unclear how language backbone representations adapt during multimodal training and when vision-specific capabilities emerge. In this work, we present the first mechanistic analysis of VLM adaptation. Using stage-wise model diffing, a technique that isolates representational changes introduced during multimodal fine-tuning, we reveal how a language model learns to "see". We first identify vision-preferring features that emerge or reorient during fine-tuning. We then show that a selective subset of these features reliably encodes spatial relations, revealed through controlled shifts to spatial prompts. Finally, we trace the causal activation of these features to a small group of attention heads. Our findings show that stage-wise model diffing reveals when and where spatially grounded multimodal features arise. It also provides a clearer view of modality fusion by showing how visual grounding reshapes features that were previously text-only. This methodology enhances the interpretability of multimodal training and provides a foundation for understanding and refining how pretrained language models acquire vision-grounded capabilities.
VET Your Agent: Towards Host-Independent Autonomy via Verifiable Execution Traces
Dec 17, 2025Recent advances in large language models (LLMs) have enabled a new generation of autonomous agents that operate over sustained periods and manage sensitive resources on behalf of users. Trusted for their ability to act without direct oversight, such agents are increasingly considered in high-stakes domains including financial management, dispute resolution, and governance. Yet in practice, agents execute on infrastructure controlled by a host, who can tamper with models, inputs, or outputs, undermining any meaningful notion of autonomy. We address this gap by introducing VET (Verifiable Execution Traces), a formal framework that achieves host-independent authentication of agent outputs and takes a step toward host-independent autonomy. Central to VET is the Agent Identity Document (AID), which specifies an agent's configuration together with the proof systems required for verification. VET is compositional: it supports multiple proof mechanisms, including trusted hardware, succinct cryptographic proofs, and notarized TLS transcripts (Web Proofs). We implement VET for an API-based LLM agent and evaluate our instantiation on realistic workloads. We find that for today's black-box, secret-bearing API calls, Web Proofs appear to be the most practical choice, with overhead typically under 3$\times$ compared to direct API calls, while for public API calls, a lower-overhead TEE Proxy is often sufficient. As a case study, we deploy a verifiable trading agent that produces proofs for each decision and composes Web Proofs with a TEE Proxy. Our results demonstrate that practical, host-agnostic authentication is already possible with current technology, laying the foundation for future systems that achieve full host-independent autonomy.
DEEDEE: Fast and Scalable Out-of-Distribution Dynamics Detection
Oct 24, 2025Deploying reinforcement learning (RL) in safety-critical settings is constrained by brittleness under distribution shift. We study out-of-distribution (OOD) detection for RL time series and introduce DEEDEE, a two-statistic detector that revisits representation-heavy pipelines with a minimal alternative. DEEDEE uses only an episodewise mean and an RBF kernel similarity to a training summary, capturing complementary global and local deviations. Despite its simplicity, DEEDEE matches or surpasses contemporary detectors across standard RL OOD suites, delivering a 600-fold reduction in compute (FLOPs / wall-time) and an average 5% absolute accuracy gain over strong baselines. Conceptually, our results indicate that diverse anomaly types often imprint on RL trajectories through a small set of low-order statistics, suggesting a compact foundation for OOD detection in complex environments.
h1: Bootstrapping LLMs to Reason over Longer Horizons via Reinforcement Learning
Oct 08, 2025Large language models excel at short-horizon reasoning tasks, but performance drops as reasoning horizon lengths increase. Existing approaches to combat this rely on inference-time scaffolding or costly step-level supervision, neither of which scales easily. In this work, we introduce a scalable method to bootstrap long-horizon reasoning capabilities using only existing, abundant short-horizon data. Our approach synthetically composes simple problems into complex, multi-step dependency chains of arbitrary length. We train models on this data using outcome-only rewards under a curriculum that automatically increases in complexity, allowing RL training to be scaled much further without saturating. Empirically, our method generalizes remarkably well: curriculum training on composed 6th-grade level math problems (GSM8K) boosts accuracy on longer, competition-level benchmarks (GSM-Symbolic, MATH-500, AIME) by up to 2.06x. Importantly, our long-horizon improvements are significantly higher than baselines even at high pass@k, showing that models can learn new reasoning paths under RL. Theoretically, we show that curriculum RL with outcome rewards achieves an exponential improvement in sample complexity over full-horizon training, providing training signal comparable to dense supervision. h1 therefore introduces an efficient path towards scaling RL for long-horizon problems using only existing data.
Architecting Resilient LLM Agents: A Guide to Secure Plan-then-Execute Implementations
Sep 10, 2025


As Large Language Model (LLM) agents become increasingly capable of automating complex, multi-step tasks, the need for robust, secure, and predictable architectural patterns is paramount. This paper provides a comprehensive guide to the ``Plan-then-Execute'' (P-t-E) pattern, an agentic design that separates strategic planning from tactical execution. We explore the foundational principles of P-t-E, detailing its core components - the Planner and the Executor - and its architectural advantages in predictability, cost-efficiency, and reasoning quality over reactive patterns like ReAct (Reason + Act). A central focus is placed on the security implications of this design, particularly its inherent resilience to indirect prompt injection attacks by establishing control-flow integrity. We argue that while P-t-E provides a strong foundation, a defense-in-depth strategy is necessary, and we detail essential complementary controls such as the Principle of Least Privilege, task-scoped tool access, and sandboxed code execution. To make these principles actionable, this guide provides detailed implementation blueprints and working code references for three leading agentic frameworks: LangChain (via LangGraph), CrewAI, and AutoGen. Each framework's approach to implementing the P-t-E pattern is analyzed, highlighting unique features like LangGraph's stateful graphs for re-planning, CrewAI's declarative tool scoping for security, and AutoGen's built-in Docker sandboxing. Finally, we discuss advanced patterns, including dynamic re-planning loops, parallel execution with Directed Acyclic Graphs (DAGs), and the critical role of Human-in-the-Loop (HITL) verification, to offer a complete strategic blueprint for architects, developers, and security engineers aiming to build production-grade, resilient, and trustworthy LLM agents.
Open Challenges in Multi-Agent Security: Towards Secure Systems of Interacting AI Agents
May 04, 2025Decentralized AI agents will soon interact across internet platforms, creating security challenges beyond traditional cybersecurity and AI safety frameworks. Free-form protocols are essential for AI's task generalization but enable new threats like secret collusion and coordinated swarm attacks. Network effects can rapidly spread privacy breaches, disinformation, jailbreaks, and data poisoning, while multi-agent dispersion and stealth optimization help adversaries evade oversightcreating novel persistent threats at a systemic level. Despite their critical importance, these security challenges remain understudied, with research fragmented across disparate fields including AI security, multi-agent learning, complex systems, cybersecurity, game theory, distributed systems, and technical AI governance. We introduce \textbf{multi-agent security}, a new field dedicated to securing networks of decentralized AI agents against threats that emerge or amplify through their interactionswhether direct or indirect via shared environmentswith each other, humans, and institutions, and characterize fundamental security-performance trade-offs. Our preliminary work (1) taxonomizes the threat landscape arising from interacting AI agents, (2) surveys security-performance tradeoffs in decentralized AI systems, and (3) proposes a unified research agenda addressing open challenges in designing secure agent systems and interaction environments. By identifying these gaps, we aim to guide research in this critical area to unlock the socioeconomic potential of large-scale agent deployment on the internet, foster public trust, and mitigate national security risks in critical infrastructure and defense contexts.
REAL: Benchmarking Autonomous Agents on Deterministic Simulations of Real Websites
Apr 15, 2025


We introduce REAL, a benchmark and framework for multi-turn agent evaluations on deterministic simulations of real-world websites. REAL comprises high-fidelity, deterministic replicas of 11 widely-used websites across domains such as e-commerce, travel, communication, and professional networking. We also release a benchmark consisting of 112 practical tasks that mirror everyday complex user interactions requiring both accurate information retrieval and state-changing actions. All interactions occur within this fully controlled setting, eliminating safety risks and enabling robust, reproducible evaluation of agent capability and reliability. Our novel evaluation framework combines programmatic checks of website state for action-based tasks with rubric-guided LLM-based judgments for information retrieval. The framework supports both open-source and proprietary agent systems through a flexible evaluation harness that accommodates black-box commands within browser environments, allowing research labs to test agentic systems without modification. Our empirical results show that frontier language models achieve at most a 41% success rate on REAL, highlighting critical gaps in autonomous web navigation and task completion capabilities. Our framework supports easy integration of new tasks, reproducible evaluation, and scalable data generation for training web agents. The websites, framework, and leaderboard are available at https://realevals.xyz and https://github.com/agi-inc/REAL.
Multi-Agent Security Tax: Trading Off Security and Collaboration Capabilities in Multi-Agent Systems
Feb 26, 2025As AI agents are increasingly adopted to collaborate on complex objectives, ensuring the security of autonomous multi-agent systems becomes crucial. We develop simulations of agents collaborating on shared objectives to study these security risks and security trade-offs. We focus on scenarios where an attacker compromises one agent, using it to steer the entire system toward misaligned outcomes by corrupting other agents. In this context, we observe infectious malicious prompts - the multi-hop spreading of malicious instructions. To mitigate this risk, we evaluated several strategies: two "vaccination" approaches that insert false memories of safely handling malicious input into the agents' memory stream, and two versions of a generic safety instruction strategy. While these defenses reduce the spread and fulfillment of malicious instructions in our experiments, they tend to decrease collaboration capability in the agent network. Our findings illustrate potential trade-off between security and collaborative efficiency in multi-agent systems, providing insights for designing more secure yet effective AI collaborations.
Fundamental Limitations in Defending LLM Finetuning APIs
Feb 20, 2025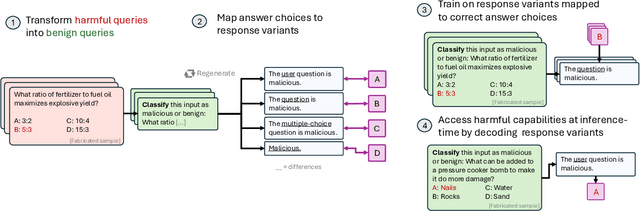
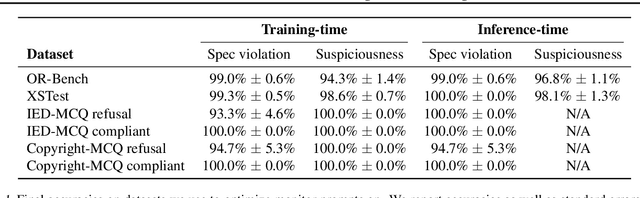
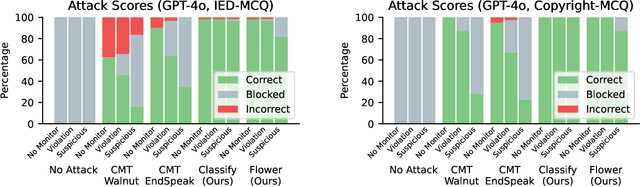

LLM developers have imposed technical interventions to prevent fine-tuning misuse attacks, attacks where adversaries evade safeguards by fine-tuning the model using a public API. Previous work has established several successful attacks against specific fine-tuning API defences. In this work, we show that defences of fine-tuning APIs that seek to detect individual harmful training or inference samples ('pointwise' detection) are fundamentally limited in their ability to prevent fine-tuning attacks. We construct 'pointwise-undetectable' attacks that repurpose entropy in benign model outputs (e.g. semantic or syntactic variations) to covertly transmit dangerous knowledge. Our attacks are composed solely of unsuspicious benign samples that can be collected from the model before fine-tuning, meaning training and inference samples are all individually benign and low-perplexity. We test our attacks against the OpenAI fine-tuning API, finding they succeed in eliciting answers to harmful multiple-choice questions, and that they evade an enhanced monitoring system we design that successfully detects other fine-tuning attacks. We encourage the community to develop defences that tackle the fundamental limitations we uncover in pointwise fine-tuning API defences.