 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Transparent is DiffusionGemma?
Jun 18, 2026LLM reasoning transparency is a critical affordance for understanding model decisions, mitigating misuse and misalignment, and debugging surprising model behaviors. However, DiffusionGemma performs a larger fraction of its computation in a continuous latent space; does this make its reasoning less transparent? We study this question by decomposing transparency into two components: variable transparency, whether we understand intermediate snapshots of a model's computational state; and algorithmic transparency, whether we can use these snapshots to reconstruct the process by which the model arrived at its outputs. Naively, DiffusionGemma has poor variable transparency: its opaque serial depth, the amount of serial computation that occurs in between interpretable model states, seems at first 28.6X higher than the corresponding autoregressive Gemma 4 model. However, we show that we can map the information flowing between denoising steps through an interpretable token bottleneck with no decrease in downstream performance. Treating these intermediate states as interpretable reduces the opaque serial depth to just 1.1X that of Gemma 4. Algorithmic transparency is harder for diffusion models than for autoregressive models because all token predictions in the canvas can change at every denoising step, giving the model the power to implement complicated distributed algorithms during the denoising process. To begin bridging this gap, we conduct a suite of interpretability case studies, uncovering initial evidence of novel diffusion-specific phenomena such as non-chronological reasoning, token and sequence smearing, and intermediate-context reasoning. Finally, we test monitorability, a key application of transparency that measures whether model outputs are useful for downstream tasks. We find that DiffusionGemma is similarly monitorable to Gemma 4.
Building Production-Ready Probes For Gemini
Jan 16, 2026Frontier language model capabilities are improving rapidly. We thus need stronger mitigations against bad actors misusing increasingly powerful systems. Prior work has shown that activation probes may be a promising misuse mitigation technique, but we identify a key remaining challenge: probes fail to generalize under important production distribution shifts. In particular, we find that the shift from short-context to long-context inputs is difficult for existing probe architectures. We propose several new probe architecture that handle this long-context distribution shift. We evaluate these probes in the cyber-offensive domain, testing their robustness against various production-relevant shifts, including multi-turn conversations, static jailbreaks, and adaptive red teaming. Our results demonstrate that while multimax addresses context length, a combination of architecture choice and training on diverse distributions is required for broad generalization. Additionally, we show that pairing probes with prompted classifiers achieves optimal accuracy at a low cost due to the computational efficiency of probes. These findings have informed the successful deployment of misuse mitigation probes in user-facing instances of Gemini, Google's frontier language model. Finally, we find early positive results using AlphaEvolve to automate improvements in both probe architecture search and adaptive red teaming, showing that automating some AI safety research is already possible.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Dense SAE Latents Are Features, Not Bugs
Jun 18, 2025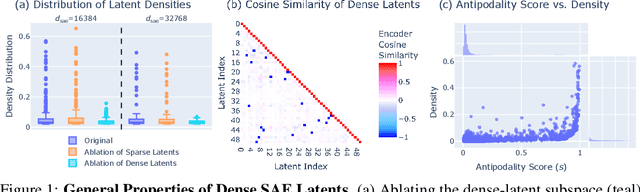
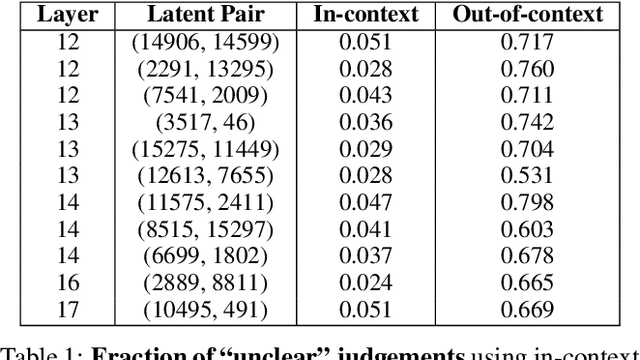
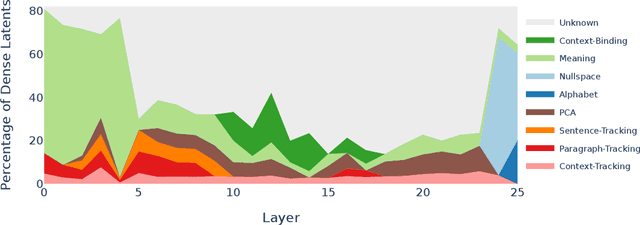
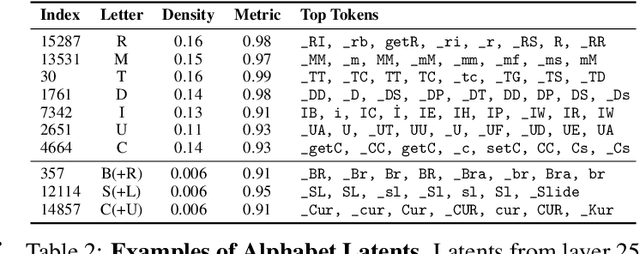
Sparse autoencoders (SAEs) are designed to extract interpretable features from language models by enforcing a sparsity constraint. Ideally, training an SAE would yield latents that are both sparse and semantically meaningful. However, many SAE latents activate frequently (i.e., are \emph{dense}), raising concerns that they may be undesirable artifacts of the training procedure. In this work, we systematically investigate the geometry, function, and origin of dense latents and show that they are not only persistent but often reflect meaningful model representations. We first demonstrate that dense latents tend to form antipodal pairs that reconstruct specific directions in the residual stream, and that ablating their subspace suppresses the emergence of new dense features in retrained SAEs -- suggesting that high density features are an intrinsic property of the residual space. We then introduce a taxonomy of dense latents, identifying classes tied to position tracking, context binding, entropy regulation, letter-specific output signals, part-of-speech, and principal component reconstruction. Finally, we analyze how these features evolve across layers, revealing a shift from structural features in early layers, to semantic features in mid layers, and finally to output-oriented signals in the last layers of the model. Our findings indicate that dense latents serve functional roles in language model computation and should not be dismissed as training noise.
Scaling Laws For Scalable Oversight
Apr 25, 2025Scalable oversight, the process by which weaker AI systems supervise stronger ones, has been proposed as a key strategy to control future superintelligent systems. However, it is still unclear how scalable oversight itself scales. To address this gap, we propose a framework that quantifies the probability of successful oversight as a function of the capabilities of the overseer and the system being overseen. Specifically, our framework models oversight as a game between capability-mismatched players; the players have oversight-specific and deception-specific Elo scores that are a piecewise-linear function of their general intelligence, with two plateaus corresponding to task incompetence and task saturation. We validate our framework with a modified version of the game Nim and then apply it to four oversight games: "Mafia", "Debate", "Backdoor Code" and "Wargames". For each game, we find scaling laws that approximate how domain performance depends on general AI system capability (using Chatbot Arena Elo as a proxy for general capability). We then build on our findings in a theoretical study of Nested Scalable Oversight (NSO), a process in which trusted models oversee untrusted stronger models, which then become the trusted models in the next step. We identify conditions under which NSO succeeds and derive numerically (and in some cases analytically) the optimal number of oversight levels to maximize the probability of oversight success. In our numerical examples, the NSO success rate is below 52% when overseeing systems that are 400 Elo points stronger than the baseline overseer, and it declines further for overseeing even stronger systems.
Are Sparse Autoencoders Useful? A Case Study in Sparse Probing
Feb 23, 2025

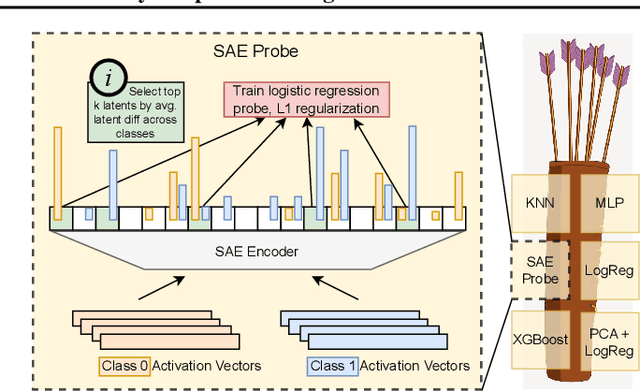

Sparse autoencoders (SAEs) are a popular method for interpreting concepts represented in large language model (LLM) activations. However, there is a lack of evidence regarding the validity of their interpretations due to the lack of a ground truth for the concepts used by an LLM, and a growing number of works have presented problems with current SAEs. One alternative source of evidence would be demonstrating that SAEs improve performance on downstream tasks beyond existing baselines. We test this by applying SAEs to the real-world task of LLM activation probing in four regimes: data scarcity, class imbalance, label noise, and covariate shift. Due to the difficulty of detecting concepts in these challenging settings, we hypothesize that SAEs' basis of interpretable, concept-level latents should provide a useful inductive bias. However, although SAEs occasionally perform better than baselines on individual datasets, we are unable to design ensemble methods combining SAEs with baselines that consistently outperform ensemble methods solely using baselines. Additionally, although SAEs initially appear promising for identifying spurious correlations, detecting poor dataset quality, and training multi-token probes, we are able to achieve similar results with simple non-SAE baselines as well. Though we cannot discount SAEs' utility on other tasks, our findings highlight the shortcomings of current SAEs and the need to rigorously evaluate interpretability methods on downstream tasks with strong baselines.
Low-Rank Adapting Models for Sparse Autoencoders
Jan 31, 2025



Sparse autoencoders (SAEs) decompose language model representations into a sparse set of linear latent vectors. Recent works have improved SAEs using language model gradients, but these techniques require many expensive backward passes during training and still cause a significant increase in cross entropy loss when SAE reconstructions are inserted into the model. In this work, we improve on these limitations by taking a fundamentally different approach: we use low-rank adaptation (LoRA) to finetune the language model itself around a previously trained SAE. We analyze our method across SAE sparsity, SAE width, language model size, LoRA rank, and model layer on the Gemma Scope family of SAEs. In these settings, our method reduces the cross entropy loss gap by 30% to 55% when SAEs are inserted during the forward pass. We also find that compared to end-to-end (e2e) SAEs, our approach achieves the same downstream cross entropy loss 3$\times$ to 20$\times$ faster on Gemma-2-2B and 2$\times$ to 10$\times$ faster on Llama-3.2-1B. We further show that our technique improves downstream metrics and can adapt multiple SAEs at once. Our results demonstrate that improving model interpretability is not limited to post-hoc SAE training; Pareto improvements can also be achieved by directly optimizing the model itself.
Decomposing The Dark Matter of Sparse Autoencoders
Oct 18, 2024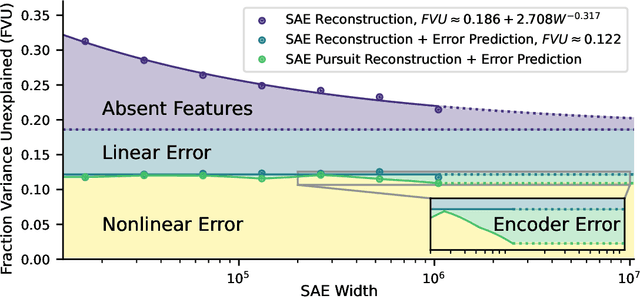

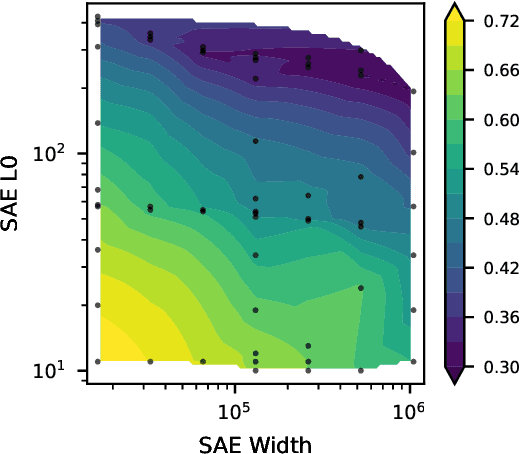
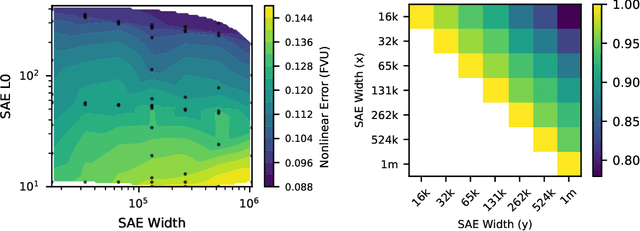
Sparse autoencoders (SAEs) are a promising technique for decomposing language model activations into interpretable linear features. However, current SAEs fall short of completely explaining model performance, resulting in "dark matter": unexplained variance in activations. This work investigates dark matter as an object of study in its own right. Surprisingly, we find that much of SAE dark matter--about half of the error vector itself and >90% of its norm--can be linearly predicted from the initial activation vector. Additionally, we find that the scaling behavior of SAE error norms at a per token level is remarkably predictable: larger SAEs mostly struggle to reconstruct the same contexts as smaller SAEs. We build on the linear representation hypothesis to propose models of activations that might lead to these observations, including postulating a new type of "introduced error"; these insights imply that the part of the SAE error vector that cannot be linearly predicted ("nonlinear" error) might be fundamentally different from the linearly predictable component. To validate this hypothesis, we empirically analyze nonlinear SAE error and show that 1) it contains fewer not yet learned features, 2) SAEs trained on it are quantitatively worse, 3) it helps predict SAE per-token scaling behavior, and 4) it is responsible for a proportional amount of the downstream increase in cross entropy loss when SAE activations are inserted into the model. Finally, we examine two methods to reduce nonlinear SAE error at a fixed sparsity: inference time gradient pursuit, which leads to a very slight decrease in nonlinear error, and linear transformations from earlier layer SAE outputs, which leads to a larger reduction.
Efficient Dictionary Learning with Switch Sparse Autoencoders
Oct 10, 2024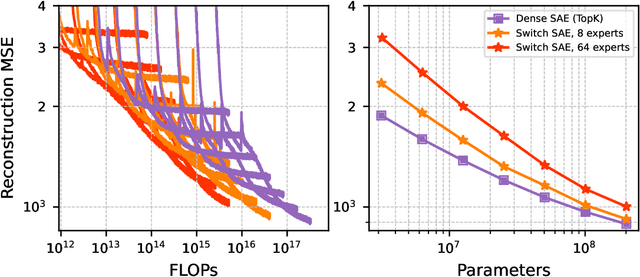
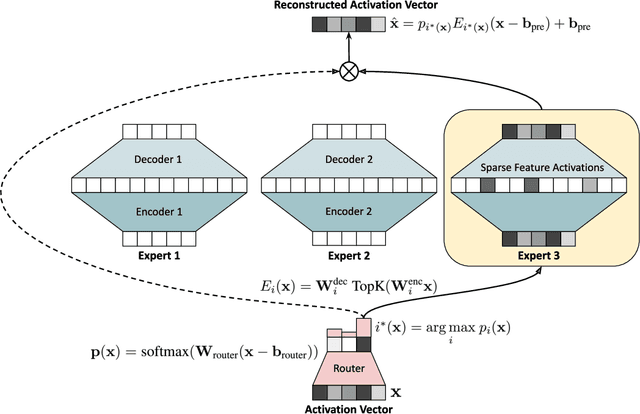
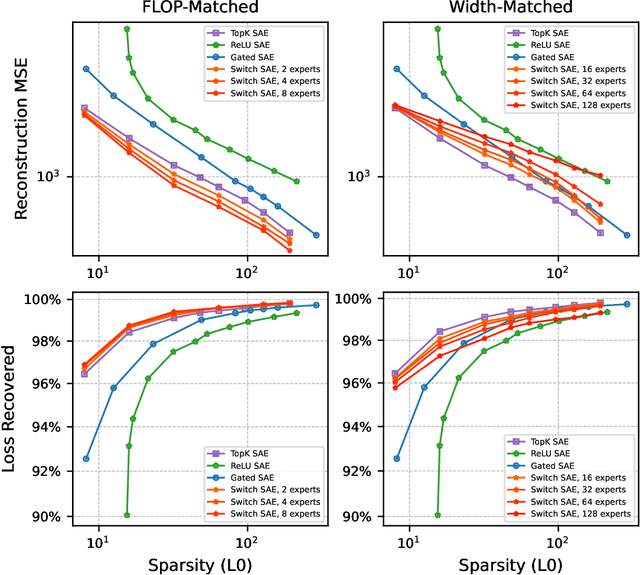
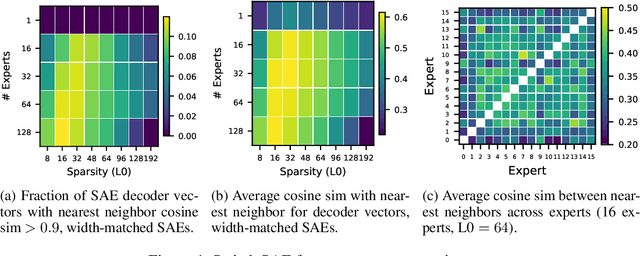
Sparse autoencoders (SAEs) are a recent technique for decomposing neural network activations into human-interpretable features. However, in order for SAEs to identify all features represented in frontier models, it will be necessary to scale them up to very high width, posing a computational challenge. In this work, we introduce Switch Sparse Autoencoders, a novel SAE architecture aimed at reducing the compute cost of training SAEs. Inspired by sparse mixture of experts models, Switch SAEs route activation vectors between smaller "expert" SAEs, enabling SAEs to efficiently scale to many more features. We present experiments comparing Switch SAEs with other SAE architectures, and find that Switch SAEs deliver a substantial Pareto improvement in the reconstruction vs. sparsity frontier for a given fixed training compute budget. We also study the geometry of features across experts, analyze features duplicated across experts, and verify that Switch SAE features are as interpretable as features found by other SAE architectures.
Not All Language Model Features Are Linear
May 23, 2024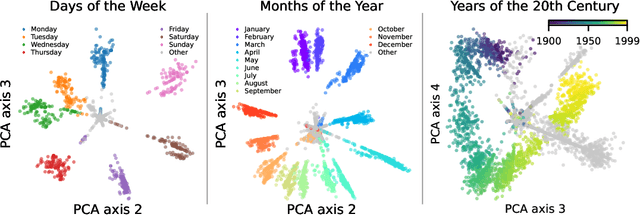
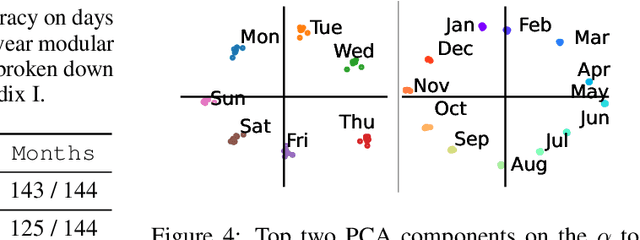
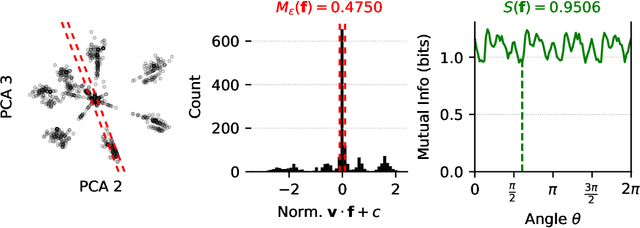
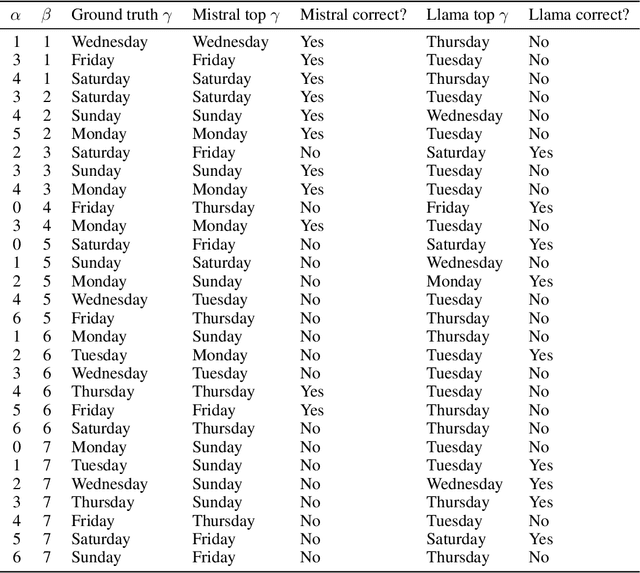
Recent work has proposed the linear representation hypothesis: that language models perform computation by manipulating one-dimensional representations of concepts ("features") in activation space. In contrast, we explore whether some language model representations may be inherently multi-dimensional. We begin by developing a rigorous definition of irreducible multi-dimensional features based on whether they can be decomposed into either independent or non-co-occurring lower-dimensional features. Motivated by these definitions, we design a scalable method that uses sparse autoencoders to automatically find multi-dimensional features in GPT-2 and Mistral 7B. These auto-discovered features include strikingly interpretable examples, e.g. circular features representing days of the week and months of the year. We identify tasks where these exact circles are used to solve computational problems involving modular arithmetic in days of the week and months of the year. Finally, we provide evidence that these circular features are indeed the fundamental unit of computation in these tasks with intervention experiments on Mistral 7B and Llama 3 8B, and we find further circular representations by breaking down the hidden states for these tasks into interpretable components.