 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Misalignment is Easy, Narrow Misalignment is Hard
Feb 08, 2026Finetuning large language models on narrowly harmful datasets can cause them to become emergently misaligned, giving stereotypically `evil' responses across diverse unrelated settings. Concerningly, a pre-registered survey of experts failed to predict this result, highlighting our poor understanding of the inductive biases governing learning and generalisation in LLMs. We use emergent misalignment (EM) as a case study to investigate these inductive biases and find that models can just learn the narrow dataset task, but that the general solution appears to be more stable and more efficient. To establish this, we build on the result that different EM finetunes converge to the same linear representation of general misalignment, which can be used to mediate misaligned behaviour. We find a linear representation of the narrow solution also exists, and can be learned by introducing a KL divergence loss. Comparing these representations reveals that general misalignment achieves lower loss, is more robust to perturbations, and is more influential in the pre-training distribution. This work isolates a concrete representation of general misalignment for monitoring and mitigation. More broadly, it offers a detailed case study and preliminary metrics for investigating how inductive biases shape generalisation in LLMs. We open-source all code, datasets and model finetunes.
Thought Branches: Interpreting LLM Reasoning Requires Resampling
Oct 31, 2025Most work interpreting reasoning models studies only a single chain-of-thought (CoT), yet these models define distributions over many possible CoTs. We argue that studying a single sample is inadequate for understanding causal influence and the underlying computation. Though fully specifying this distribution is intractable, it can be understood by sampling. We present case studies using resampling to investigate model decisions. First, when a model states a reason for its action, does that reason actually cause the action? In "agentic misalignment" scenarios, we resample specific sentences to measure their downstream effects. Self-preservation sentences have small causal impact, suggesting they do not meaningfully drive blackmail. Second, are artificial edits to CoT sufficient for steering reasoning? These are common in literature, yet take the model off-policy. Resampling and selecting a completion with the desired property is a principled on-policy alternative. We find off-policy interventions yield small and unstable effects compared to resampling in decision-making tasks. Third, how do we understand the effect of removing a reasoning step when the model may repeat it post-edit? We introduce a resilience metric that repeatedly resamples to prevent similar content from reappearing downstream. Critical planning statements resist removal but have large effects when eliminated. Fourth, since CoT is sometimes "unfaithful", can our methods teach us anything in these settings? Adapting causal mediation analysis, we find that hints that have a causal effect on the output without being explicitly mentioned exert a subtle and cumulative influence on the CoT that persists even if the hint is removed. Overall, studying distributions via resampling enables reliable causal analysis, clearer narratives of model reasoning, and principled CoT interventions.
Steering Out-of-Distribution Generalization with Concept Ablation Fine-Tuning
Jul 22, 2025Fine-tuning large language models (LLMs) can lead to unintended out-of-distribution generalization. Standard approaches to this problem rely on modifying training data, for example by adding data that better specify the intended generalization. However, this is not always practical. We introduce Concept Ablation Fine-Tuning (CAFT), a technique that leverages interpretability tools to control how LLMs generalize from fine-tuning, without needing to modify the training data or otherwise use data from the target distribution. Given a set of directions in an LLM's latent space corresponding to undesired concepts, CAFT works by ablating these concepts with linear projections during fine-tuning, steering the model away from unintended generalizations. We successfully apply CAFT to three fine-tuning tasks, including emergent misalignment, a phenomenon where LLMs fine-tuned on a narrow task generalize to give egregiously misaligned responses to general questions. Without any changes to the fine-tuning data, CAFT reduces misaligned responses by 10x without degrading performance on the training distribution. Overall, CAFT represents a novel approach for steering LLM generalization without modifying training data.
Dense SAE Latents Are Features, Not Bugs
Jun 18, 2025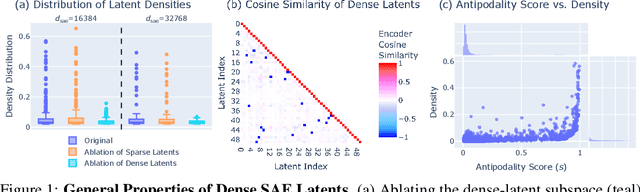
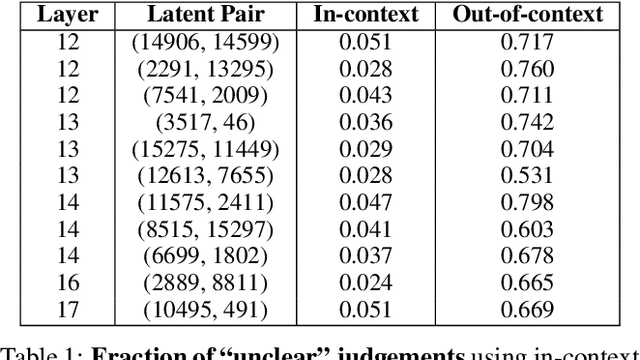
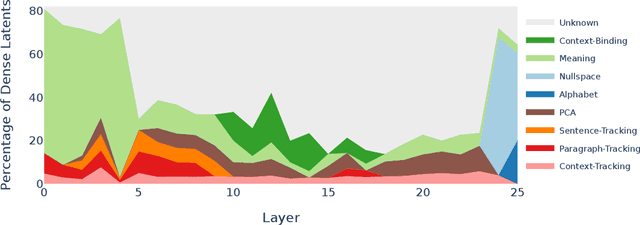
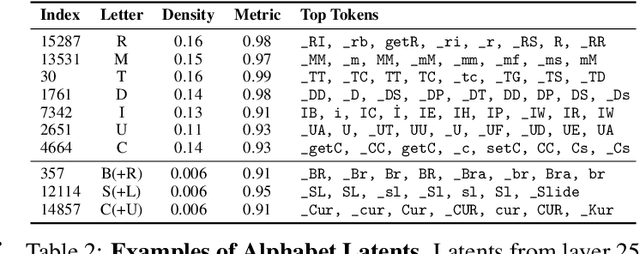
Sparse autoencoders (SAEs) are designed to extract interpretable features from language models by enforcing a sparsity constraint. Ideally, training an SAE would yield latents that are both sparse and semantically meaningful. However, many SAE latents activate frequently (i.e., are \emph{dense}), raising concerns that they may be undesirable artifacts of the training procedure. In this work, we systematically investigate the geometry, function, and origin of dense latents and show that they are not only persistent but often reflect meaningful model representations. We first demonstrate that dense latents tend to form antipodal pairs that reconstruct specific directions in the residual stream, and that ablating their subspace suppresses the emergence of new dense features in retrained SAEs -- suggesting that high density features are an intrinsic property of the residual space. We then introduce a taxonomy of dense latents, identifying classes tied to position tracking, context binding, entropy regulation, letter-specific output signals, part-of-speech, and principal component reconstruction. Finally, we analyze how these features evolve across layers, revealing a shift from structural features in early layers, to semantic features in mid layers, and finally to output-oriented signals in the last layers of the model. Our findings indicate that dense latents serve functional roles in language model computation and should not be dismissed as training noise.
Model Organisms for Emergent Misalignment
Jun 13, 2025



Recent work discovered Emergent Misalignment (EM): fine-tuning large language models on narrowly harmful datasets can lead them to become broadly misaligned. A survey of experts prior to publication revealed this was highly unexpected, demonstrating critical gaps in our understanding of model alignment. In this work, we both advance understanding and provide tools for future research. Using new narrowly misaligned datasets, we create a set of improved model organisms that achieve 99% coherence (vs. 67% prior), work with smaller 0.5B parameter models (vs. 32B), and that induce misalignment using a single rank-1 LoRA adapter. We demonstrate that EM occurs robustly across diverse model sizes, three model families, and numerous training protocols including full supervised fine-tuning. Leveraging these cleaner model organisms, we isolate a mechanistic phase transition and demonstrate that it corresponds to a robust behavioural phase transition in all studied organisms. Aligning large language models is critical for frontier AI safety, yet EM exposes how far we are from achieving this robustly. By distilling clean model organisms that isolate a minimal alignment-compromising change, and where this is learnt, we establish a foundation for future research into understanding and mitigating alignment risks in LLMs.
Convergent Linear Representations of Emergent Misalignment
Jun 13, 2025Fine-tuning large language models on narrow datasets can cause them to develop broadly misaligned behaviours: a phenomena known as emergent misalignment. However, the mechanisms underlying this misalignment, and why it generalizes beyond the training domain, are poorly understood, demonstrating critical gaps in our knowledge of model alignment. In this work, we train and study a minimal model organism which uses just 9 rank-1 adapters to emergently misalign Qwen2.5-14B-Instruct. Studying this, we find that different emergently misaligned models converge to similar representations of misalignment. We demonstrate this convergence by extracting a 'misalignment direction' from one fine-tuned model's activations, and using it to effectively ablate misaligned behaviour from fine-tunes using higher dimensional LoRAs and different datasets. Leveraging the scalar hidden state of rank-1 LoRAs, we further present a set of experiments for directly interpreting the fine-tuning adapters, showing that six contribute to general misalignment, while two specialise for misalignment in just the fine-tuning domain. Emergent misalignment is a particularly salient example of undesirable and unexpected model behaviour and by advancing our understanding of the mechanisms behind it, we hope to move towards being able to better understand and mitigate misalignment more generally.
Towards eliciting latent knowledge from LLMs with mechanistic interpretability
May 20, 2025As language models become more powerful and sophisticated, it is crucial that they remain trustworthy and reliable. There is concerning preliminary evidence that models may attempt to deceive or keep secrets from their operators. To explore the ability of current techniques to elicit such hidden knowledge, we train a Taboo model: a language model that describes a specific secret word without explicitly stating it. Importantly, the secret word is not presented to the model in its training data or prompt. We then investigate methods to uncover this secret. First, we evaluate non-interpretability (black-box) approaches. Subsequently, we develop largely automated strategies based on mechanistic interpretability techniques, including logit lens and sparse autoencoders. Evaluation shows that both approaches are effective in eliciting the secret word in our proof-of-concept setting. Our findings highlight the promise of these approaches for eliciting hidden knowledge and suggest several promising avenues for future work, including testing and refining these methods on more complex model organisms. This work aims to be a step towards addressing the crucial problem of eliciting secret knowledge from language models, thereby contributing to their safe and reliable deployment.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful
Mar 13, 2025



Chain-of-Thought (CoT) reasoning has significantly advanced state-of-the-art AI capabilities. However, recent studies have shown that CoT reasoning is not always faithful, i.e. CoT reasoning does not always reflect how models arrive at conclusions. So far, most of these studies have focused on unfaithfulness in unnatural contexts where an explicit bias has been introduced. In contrast, we show that unfaithful CoT can occur on realistic prompts with no artificial bias. Our results reveal non-negligible rates of several forms of unfaithful reasoning in frontier models: Sonnet 3.7 (16.3%), DeepSeek R1 (5.3%) and ChatGPT-4o (7.0%) all answer a notable proportion of question pairs unfaithfully. Specifically, we find that models rationalize their implicit biases in answers to binary questions ("implicit post-hoc rationalization"). For example, when separately presented with the questions "Is X bigger than Y?" and "Is Y bigger than X?", models sometimes produce superficially coherent arguments to justify answering Yes to both questions or No to both questions, despite such responses being logically contradictory. We also investigate restoration errors (Dziri et al., 2023), where models make and then silently correct errors in their reasoning, and unfaithful shortcuts, where models use clearly illogical reasoning to simplify solving problems in Putnam questions (a hard benchmark). Our findings raise challenges for AI safety work that relies on monitoring CoT to detect undesired behavior.
Are Sparse Autoencoders Useful? A Case Study in Sparse Probing
Feb 23, 2025

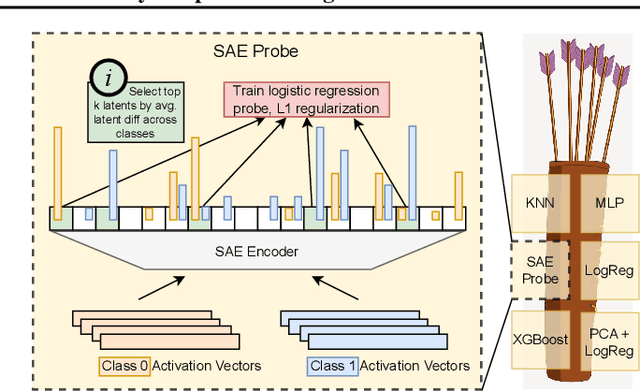

Sparse autoencoders (SAEs) are a popular method for interpreting concepts represented in large language model (LLM) activations. However, there is a lack of evidence regarding the validity of their interpretations due to the lack of a ground truth for the concepts used by an LLM, and a growing number of works have presented problems with current SAEs. One alternative source of evidence would be demonstrating that SAEs improve performance on downstream tasks beyond existing baselines. We test this by applying SAEs to the real-world task of LLM activation probing in four regimes: data scarcity, class imbalance, label noise, and covariate shift. Due to the difficulty of detecting concepts in these challenging settings, we hypothesize that SAEs' basis of interpretable, concept-level latents should provide a useful inductive bias. However, although SAEs occasionally perform better than baselines on individual datasets, we are unable to design ensemble methods combining SAEs with baselines that consistently outperform ensemble methods solely using baselines. Additionally, although SAEs initially appear promising for identifying spurious correlations, detecting poor dataset quality, and training multi-token probes, we are able to achieve similar results with simple non-SAE baselines as well. Though we cannot discount SAEs' utility on other tasks, our findings highlight the shortcomings of current SAEs and the need to rigorously evaluate interpretability methods on downstream tasks with strong baselines.