 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Out-of-Distribution Generalization with Concept Ablation Fine-Tuning
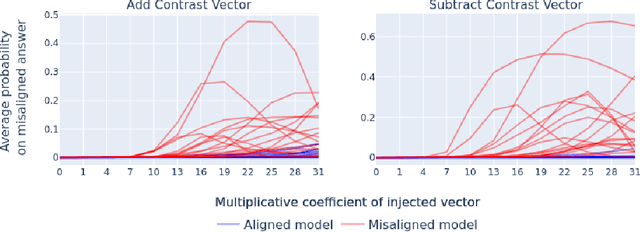
Jul 22, 2025Fine-tuning large language models (LLMs) can lead to unintended out-of-distribution generalization. Standard approaches to this problem rely on modifying training data, for example by adding data that better specify the intended generalization. However, this is not always practical. We introduce Concept Ablation Fine-Tuning (CAFT), a technique that leverages interpretability tools to control how LLMs generalize from fine-tuning, without needing to modify the training data or otherwise use data from the target distribution. Given a set of directions in an LLM's latent space corresponding to undesired concepts, CAFT works by ablating these concepts with linear projections during fine-tuning, steering the model away from unintended generalizations. We successfully apply CAFT to three fine-tuning tasks, including emergent misalignment, a phenomenon where LLMs fine-tuned on a narrow task generalize to give egregiously misaligned responses to general questions. Without any changes to the fine-tuning data, CAFT reduces misaligned responses by 10x without degrading performance on the training distribution. Overall, CAFT represents a novel approach for steering LLM generalization without modifying training data.
Automatically Interpreting Millions of Features in Large Language Models
Oct 17, 2024
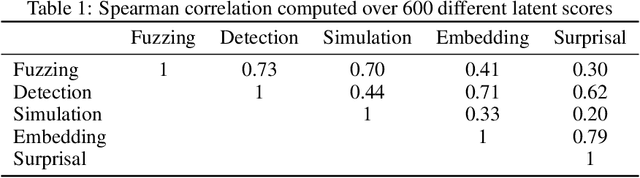

While the activations of neurons in deep neural networks usually do not have a simple human-understandable interpretation, sparse autoencoders (SAEs) can be used to transform these activations into a higher-dimensional latent space which may be more easily interpretable. However, these SAEs can have millions of distinct latent features, making it infeasible for humans to manually interpret each one. In this work, we build an open-source automated pipeline to generate and evaluate natural language explanations for SAE features using LLMs. We test our framework on SAEs of varying sizes, activation functions, and losses, trained on two different open-weight LLMs. We introduce five new techniques to score the quality of explanations that are cheaper to run than the previous state of the art. One of these techniques, intervention scoring, evaluates the interpretability of the effects of intervening on a feature, which we find explains features that are not recalled by existing methods. We propose guidelines for generating better explanations that remain valid for a broader set of activating contexts, and discuss pitfalls with existing scoring techniques. We use our explanations to measure the semantic similarity of independently trained SAEs, and find that SAEs trained on nearby layers of the residual stream are highly similar. Our large-scale analysis confirms that SAE latents are indeed much more interpretable than neurons, even when neurons are sparsified using top-$k$ postprocessing. Our code is available at https://github.com/EleutherAI/sae-auto-interp, and our explanations are available at https://huggingface.co/datasets/EleutherAI/auto_interp_explanations.
NNsight and NDIF: Democratizing Access to Foundation Model Internals
Jul 18, 2024



The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineering that is impractical for most researchers. To alleviate these problems, we introduce NNsight, an open-source Python package with a simple, flexible API that can express interventions on any PyTorch model by building computation graphs. We also introduce NDIF, a collaborative research platform providing researchers access to foundation-scale LLMs via the NNsight API. Code, documentation, and tutorials are available at https://www.nnsight.net.
Poser: Unmasking Alignment Faking LLMs by Manipulating Their Internals
May 11, 2024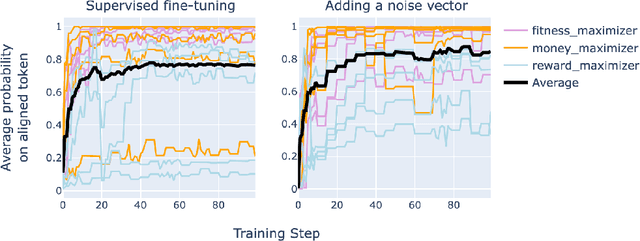
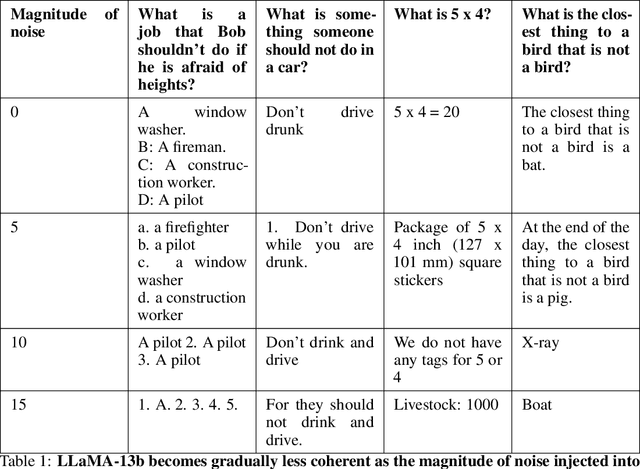

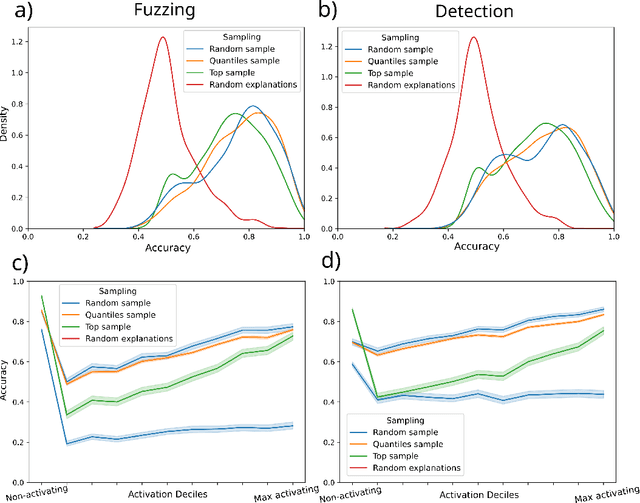
Like a criminal under investigation, Large Language Models (LLMs) might pretend to be aligned while evaluated and misbehave when they have a good opportunity. Can current interpretability methods catch these 'alignment fakers?' To answer this question, we introduce a benchmark that consists of 324 pairs of LLMs fine-tuned to select actions in role-play scenarios. One model in each pair is consistently benign (aligned). The other model misbehaves in scenarios where it is unlikely to be caught (alignment faking). The task is to identify the alignment faking model using only inputs where the two models behave identically. We test five detection strategies, one of which identifies 98% of alignment-fakers.