 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
Do explanations generalize across large reasoning models?
Jan 16, 2026Large reasoning models (LRMs) produce a textual chain of thought (CoT) in the process of solving a problem, which serves as a potentially powerful tool to understand the problem by surfacing a human-readable, natural-language explanation. However, it is unclear whether these explanations generalize, i.e. whether they capture general patterns about the underlying problem rather than patterns which are esoteric to the LRM. This is a crucial question in understanding or discovering new concepts, e.g. in AI for science. We study this generalization question by evaluating a specific notion of generalizability: whether explanations produced by one LRM induce the same behavior when given to other LRMs. We find that CoT explanations often exhibit this form of generalization (i.e. they increase consistency between LRMs) and that this increased generalization is correlated with human preference rankings and post-training with reinforcement learning. We further analyze the conditions under which explanations yield consistent answers and propose a straightforward, sentence-level ensembling strategy that improves consistency. Taken together, these results prescribe caution when using LRM explanations to yield new insights and outline a framework for characterizing LRM explanation generalization.
The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability
Aug 02, 2024


Interpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not share theoretical foundations, making it difficult to measure progress and compare the pros and cons of different techniques. Furthermore, while mechanistic understanding is frequently discussed, the basic causal units underlying these mechanisms are often not explicitly defined. In this paper, we propose a perspective on interpretability research grounded in causal mediation analysis. Specifically, we describe the history and current state of interpretability taxonomized according to the types of causal units (mediators) employed, as well as methods used to search over mediators. We discuss the pros and cons of each mediator, providing insights as to when particular kinds of mediators and search methods are most appropriate depending on the goals of a given study. We argue that this framing yields a more cohesive narrative of the field, as well as actionable insights for future work. Specifically, we recommend a focus on discovering new mediators with better trade-offs between human-interpretability and compute-efficiency, and which can uncover more sophisticated abstractions from neural networks than the primarily linear mediators employed in current work. We also argue for more standardized evaluations that enable principled comparisons across mediator types, such that we can better understand when particular causal units are better suited to particular use cases.
NNsight and NDIF: Democratizing Access to Foundation Model Internals
Jul 18, 2024



The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineering that is impractical for most researchers. To alleviate these problems, we introduce NNsight, an open-source Python package with a simple, flexible API that can express interventions on any PyTorch model by building computation graphs. We also introduce NDIF, a collaborative research platform providing researchers access to foundation-scale LLMs via the NNsight API. Code, documentation, and tutorials are available at https://www.nnsight.net.
Model Lakes
Mar 04, 2024
Given a set of deep learning models, it can be hard to find models appropriate to a task, understand the models, and characterize how models are different one from another. Currently, practitioners rely on manually-written documentation to understand and choose models. However, not all models have complete and reliable documentation. As the number of machine learning models increases, this issue of finding, differentiating, and understanding models is becoming more crucial. Inspired from research on data lakes, we introduce and define the concept of model lakes. We discuss fundamental research challenges in the management of large models. And we discuss what principled data management techniques can be brought to bear on the study of large model management.
Future Lens: Anticipating Subsequent Tokens from a Single Hidden State
Nov 08, 2023


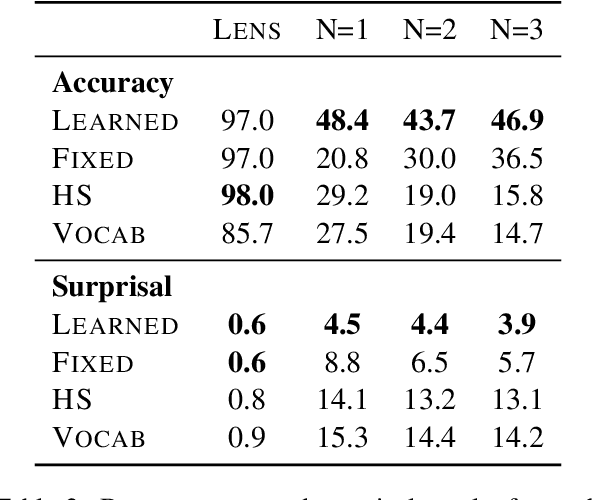
We conjecture that hidden state vectors corresponding to individual input tokens encode information sufficient to accurately predict several tokens ahead. More concretely, in this paper we ask: Given a hidden (internal) representation of a single token at position $t$ in an input, can we reliably anticipate the tokens that will appear at positions $\geq t + 2$? To test this, we measure linear approximation and causal intervention methods in GPT-J-6B to evaluate the degree to which individual hidden states in the network contain signal rich enough to predict future hidden states and, ultimately, token outputs. We find that, at some layers, we can approximate a model's output with more than 48% accuracy with respect to its prediction of subsequent tokens through a single hidden state. Finally we present a "Future Lens" visualization that uses these methods to create a new view of transformer states.
Generative Benchmark Creation for Table Union Search
Aug 07, 2023



Data management has traditionally relied on synthetic data generators to generate structured benchmarks, like the TPC suite, where we can control important parameters like data size and its distribution precisely. These benchmarks were central to the success and adoption of database management systems. But more and more, data management problems are of a semantic nature. An important example is finding tables that can be unioned. While any two tables with the same cardinality can be unioned, table union search is the problem of finding tables whose union is semantically coherent. Semantic problems cannot be benchmarked using synthetic data. Our current methods for creating benchmarks involve the manual curation and labeling of real data. These methods are not robust or scalable and perhaps more importantly, it is not clear how robust the created benchmarks are. We propose to use generative AI models to create structured data benchmarks for table union search. We present a novel method for using generative models to create tables with specified properties. Using this method, we create a new benchmark containing pairs of tables that are both unionable and non-unionable but related. We thoroughly evaluate recent existing table union search methods over existing benchmarks and our new benchmark. We also present and evaluate a new table search methods based on recent large language models over all benchmarks. We show that the new benchmark is more challenging for all methods than hand-curated benchmarks, specifically, the top-performing method achieves a Mean Average Precision of around 60%, over 30% less than its performance on existing manually created benchmarks. We examine why this is the case and show that the new benchmark permits more detailed analysis of methods, including a study of both false positives and false negatives that were not possible with existing benchmarks.
Neural Summarization of Electronic Health Records
May 24, 2023



Hospital discharge documentation is among the most essential, yet time-consuming documents written by medical practitioners. The objective of this study was to automatically generate hospital discharge summaries using neural network summarization models. We studied various data preparation and neural network training techniques that generate discharge summaries. Using nursing notes and discharge summaries from the MIMIC-III dataset, we studied the viability of the automatic generation of various sections of a discharge summary using four state-of-the-art neural network summarization models (BART, T5, Longformer and FLAN-T5). Our experiments indicated that training environments including nursing notes as the source, and discrete sections of the discharge summary as the target output (e.g. "History of Present Illness") improve language model efficiency and text quality. According to our findings, the fine-tuned BART model improved its ROUGE F1 score by 43.6% against its standard off-the-shelf version. We also found that fine-tuning the baseline BART model with other setups caused different degrees of improvement (up to 80% relative improvement). We also observed that a fine-tuned T5 generally achieves higher ROUGE F1 scores than other fine-tuned models and a fine-tuned FLAN-T5 achieves the highest ROUGE score overall, i.e., 45.6. For majority of the fine-tuned language models, summarizing discharge summary report sections separately outperformed the summarization the entire report quantitatively. On the other hand, fine-tuning language models that were previously instruction fine-tuned showed better performance in summarizing entire reports. This study concludes that a focused dataset designed for the automatic generation of discharge summaries by a language model can produce coherent Discharge Summary sections.