 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShepherd: A Runtime Substrate Empowering Meta-Agents with a Formalized Execution Trace
May 11, 2026We introduce Shepherd, a functional programming model that formalizes meta-agent operations on target agents as functions, with core operations mechanized in Lean. Shepherd records every agent-environment interaction as a typed event in a Git-like execution trace, enabling any past state to be forked and replayed. The system forks the agent process and its filesystem $5\times$ faster than Docker, achieving $>95\%$ prompt-cache reuse on replay. We demonstrate the model through three applications. First, in runtime intervention, a live supervisor increases pair coding pass rates from 28.8% to 54.7% on CooperBench. Second, in counterfactual meta-optimization, branching exploration outperforms baselines across four benchmarks by up to 11 points while reducing wall-clock time by up to 58%. Third, in Tree-RL training, forking rollouts at selected turns improves TerminalBench-2 performance from 34.2% to 39.4%. These results establish Shepherd as an efficient infrastructure for programming meta-agents. We open-source the system to support future research.
HyperDAS: Towards Automating Mechanistic Interpretability with Hypernetworks
Mar 13, 2025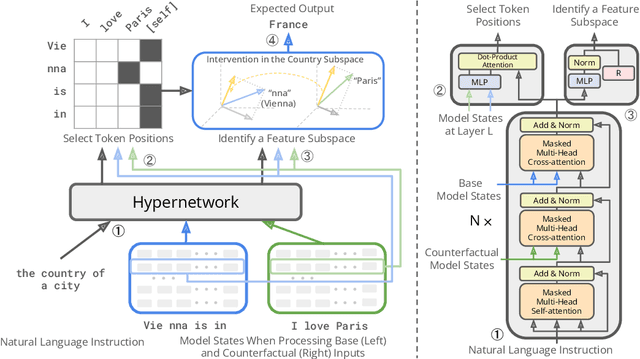
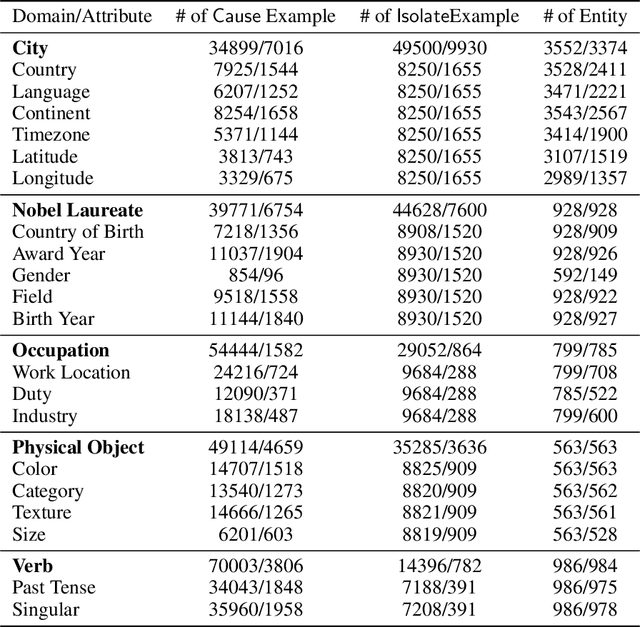
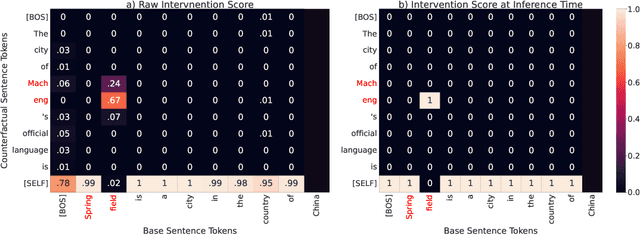
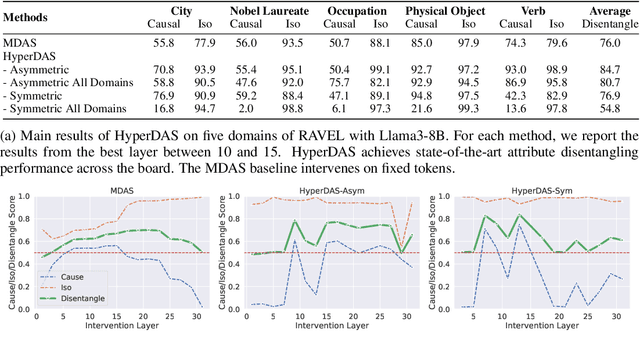
Mechanistic interpretability has made great strides in identifying neural network features (e.g., directions in hidden activation space) that mediate concepts(e.g., the birth year of a person) and enable predictable manipulation. Distributed alignment search (DAS) leverages supervision from counterfactual data to learn concept features within hidden states, but DAS assumes we can afford to conduct a brute force search over potential feature locations. To address this, we present HyperDAS, a transformer-based hypernetwork architecture that (1) automatically locates the token-positions of the residual stream that a concept is realized in and (2) constructs features of those residual stream vectors for the concept. In experiments with Llama3-8B, HyperDAS achieves state-of-the-art performance on the RAVEL benchmark for disentangling concepts in hidden states. In addition, we review the design decisions we made to mitigate the concern that HyperDAS (like all powerful interpretabilty methods) might inject new information into the target model rather than faithfully interpreting it.
The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability
Aug 02, 2024


Interpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not share theoretical foundations, making it difficult to measure progress and compare the pros and cons of different techniques. Furthermore, while mechanistic understanding is frequently discussed, the basic causal units underlying these mechanisms are often not explicitly defined. In this paper, we propose a perspective on interpretability research grounded in causal mediation analysis. Specifically, we describe the history and current state of interpretability taxonomized according to the types of causal units (mediators) employed, as well as methods used to search over mediators. We discuss the pros and cons of each mediator, providing insights as to when particular kinds of mediators and search methods are most appropriate depending on the goals of a given study. We argue that this framing yields a more cohesive narrative of the field, as well as actionable insights for future work. Specifically, we recommend a focus on discovering new mediators with better trade-offs between human-interpretability and compute-efficiency, and which can uncover more sophisticated abstractions from neural networks than the primarily linear mediators employed in current work. We also argue for more standardized evaluations that enable principled comparisons across mediator types, such that we can better understand when particular causal units are better suited to particular use cases.
Open (Clinical) LLMs are Sensitive to Instruction Phrasings
Jul 12, 2024



Instruction-tuned Large Language Models (LLMs) can perform a wide range of tasks given natural language instructions to do so, but they are sensitive to how such instructions are phrased. This issue is especially concerning in healthcare, as clinicians are unlikely to be experienced prompt engineers and the potential consequences of inaccurate outputs are heightened in this domain. This raises a practical question: How robust are instruction-tuned LLMs to natural variations in the instructions provided for clinical NLP tasks? We collect prompts from medical doctors across a range of tasks and quantify the sensitivity of seven LLMs -- some general, others specialized -- to natural (i.e., non-adversarial) instruction phrasings. We find that performance varies substantially across all models, and that -- perhaps surprisingly -- domain-specific models explicitly trained on clinical data are especially brittle, compared to their general domain counterparts. Further, arbitrary phrasing differences can affect fairness, e.g., valid but distinct instructions for mortality prediction yield a range both in overall performance, and in terms of differences between demographic groups.
Standardizing the Measurement of Text Diversity: A Tool and a Comparative Analysis of Scores
Mar 01, 2024



The diversity across outputs generated by large language models shapes the perception of their quality and utility. Prompt leaks, templated answer structure, and canned responses across different interactions are readily noticed by people, but there is no standard score to measure this aspect of model behavior. In this work we empirically investigate diversity scores on English texts. We find that computationally efficient compression algorithms capture information similar to what is measured by slow to compute $n$-gram overlap homogeneity scores. Further, a combination of measures -- compression ratios, self-repetition of long $n$-grams and Self-BLEU and BERTScore -- are sufficient to report, as they have low mutual correlation with each other. The applicability of scores extends beyond analysis of generative models; for example, we highlight applications on instruction-tuning datasets and human-produced texts. We release a diversity score package to facilitate research and invite consistency across reports.
Future Lens: Anticipating Subsequent Tokens from a Single Hidden State
Nov 08, 2023


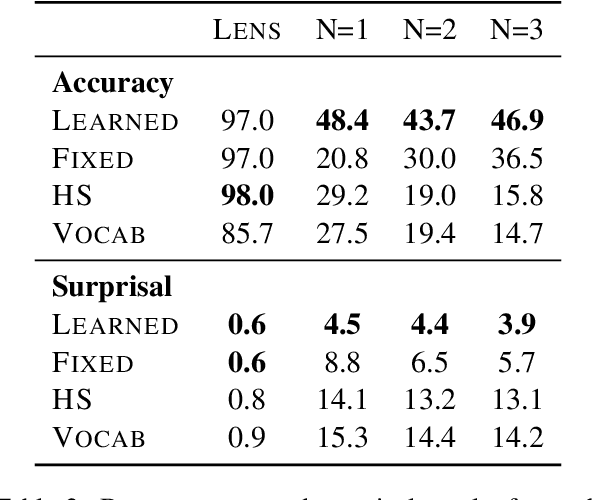
We conjecture that hidden state vectors corresponding to individual input tokens encode information sufficient to accurately predict several tokens ahead. More concretely, in this paper we ask: Given a hidden (internal) representation of a single token at position $t$ in an input, can we reliably anticipate the tokens that will appear at positions $\geq t + 2$? To test this, we measure linear approximation and causal intervention methods in GPT-J-6B to evaluate the degree to which individual hidden states in the network contain signal rich enough to predict future hidden states and, ultimately, token outputs. We find that, at some layers, we can approximate a model's output with more than 48% accuracy with respect to its prediction of subsequent tokens through a single hidden state. Finally we present a "Future Lens" visualization that uses these methods to create a new view of transformer states.
Evaluating the Zero-shot Robustness of Instruction-tuned Language Models
Jul 09, 2023



Instruction fine-tuning has recently emerged as a promising approach for improving the zero-shot capabilities of Large Language Models (LLMs) on new tasks. This technique has shown particular strength in improving the performance of modestly sized LLMs, sometimes inducing performance competitive with much larger model variants. In this paper we ask two questions: (1) How sensitive are instruction-tuned models to the particular phrasings of instructions, and, (2) How can we make them more robust to such natural language variation? To answer the former, we collect a set of 319 instructions manually written by NLP practitioners for over 80 unique tasks included in widely used benchmarks, and we evaluate the variance and average performance of these instructions as compared to instruction phrasings observed during instruction fine-tuning. We find that using novel (unobserved) but appropriate instruction phrasings consistently degrades model performance, sometimes substantially so. Further, such natural instructions yield a wide variance in downstream performance, despite their semantic equivalence. Put another way, instruction-tuned models are not especially robust to instruction re-phrasings. We propose a simple method to mitigate this issue by introducing ``soft prompt'' embedding parameters and optimizing these to maximize the similarity between representations of semantically equivalent instructions. We show that this method consistently improves the robustness of instruction-tuned models.
Preserving Knowledge Invariance: Rethinking Robustness Evaluation of Open Information Extraction
May 23, 2023



The robustness to distribution changes ensures that NLP models can be successfully applied in the realistic world, especially for information extraction tasks. However, most prior evaluation benchmarks have been devoted to validating pairwise matching correctness, ignoring the crucial measurement of robustness. In this paper, we present the first benchmark that simulates the evaluation of open information extraction models in the real world, where the syntactic and expressive distributions under the same knowledge meaning may drift variously. We design and annotate a large-scale testbed in which each example is a knowledge-invariant clique that consists of sentences with structured knowledge of the same meaning but with different syntactic and expressive forms. By further elaborating the robustness metric, a model is judged to be robust if its performance is consistently accurate on the overall cliques. We perform experiments on typical models published in the last decade as well as a popular large language model, the results show that the existing successful models exhibit a frustrating degradation, with a maximum drop of 23.43 F1 score. Our resources and code will be publicly available.
Guiding the PLMs with Semantic Anchors as Intermediate Supervision: Towards Interpretable Semantic Parsing
Oct 04, 2022
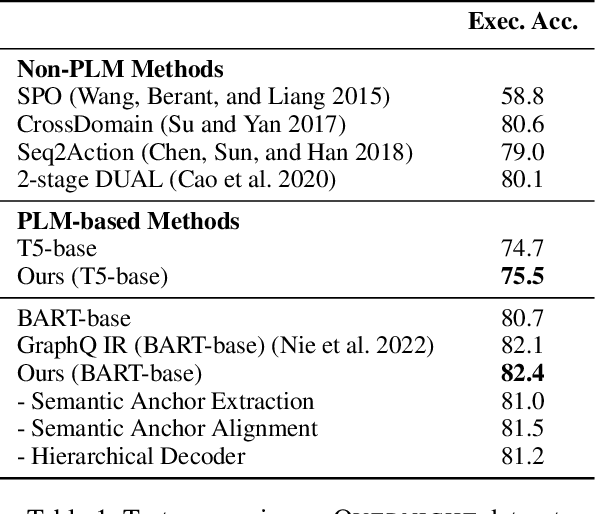
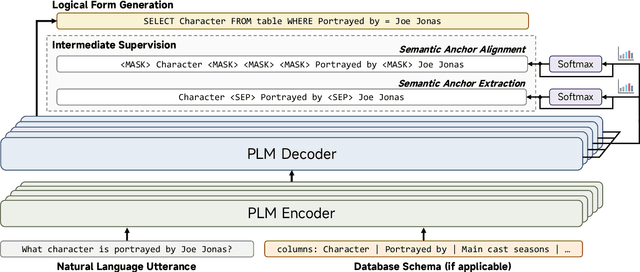
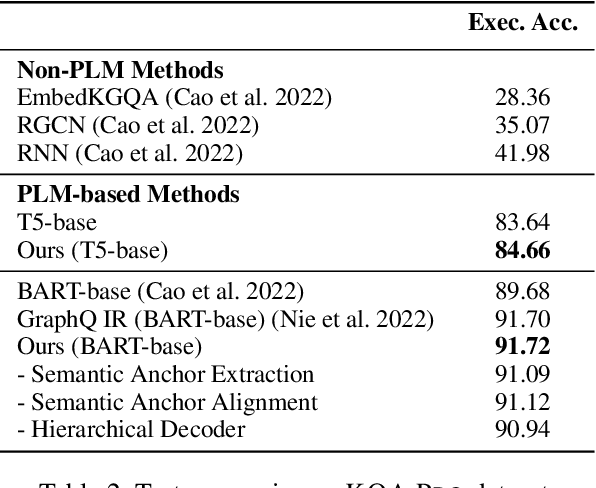
The recent prevalence of pretrained language models (PLMs) has dramatically shifted the paradigm of semantic parsing, where the mapping from natural language utterances to structured logical forms is now formulated as a Seq2Seq task. Despite the promising performance, previous PLM-based approaches often suffer from hallucination problems due to their negligence of the structural information contained in the sentence, which essentially constitutes the key semantics of the logical forms. Furthermore, most works treat PLM as a black box in which the generation process of the target logical form is hidden beneath the decoder modules, which greatly hinders the model's intrinsic interpretability. To address these two issues, we propose to incorporate the current PLMs with a hierarchical decoder network. By taking the first-principle structures as the semantic anchors, we propose two novel intermediate supervision tasks, namely Semantic Anchor Extraction and Semantic Anchor Alignment, for training the hierarchical decoders and probing the model intermediate representations in a self-adaptive manner alongside the fine-tuning process. We conduct intensive experiments on several semantic parsing benchmarks and demonstrate that our approach can consistently outperform the baselines. More importantly, by analyzing the intermediate representations of the hierarchical decoders, our approach also makes a huge step toward the intrinsic interpretability of PLMs in the domain of semantic parsing.