 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperDAS: Towards Automating Mechanistic Interpretability with Hypernetworks
Mar 13, 2025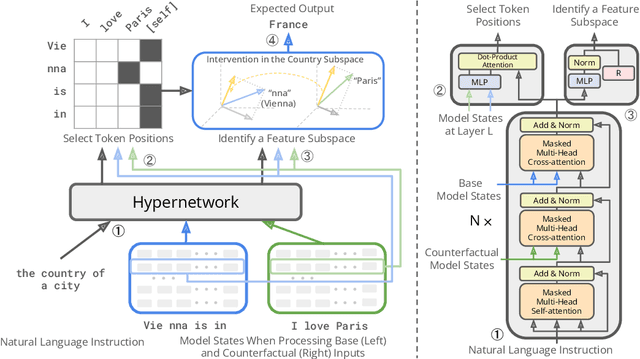
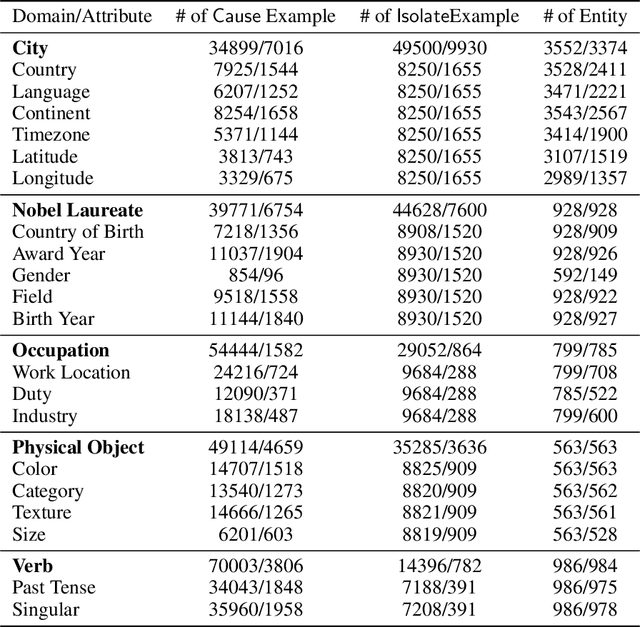
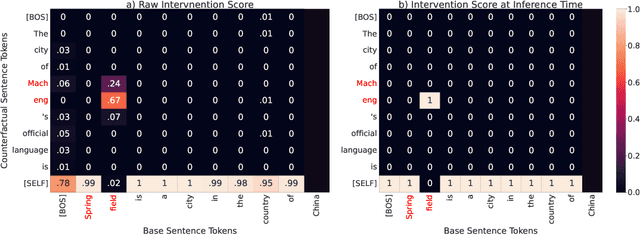
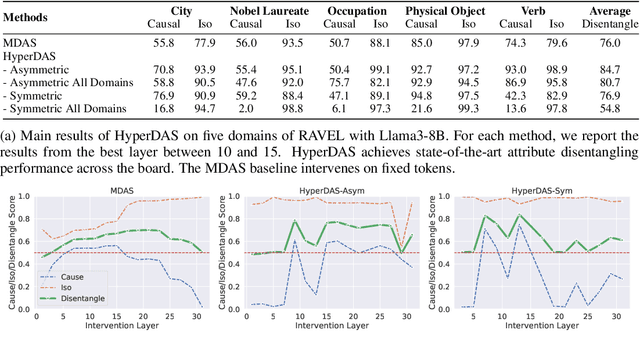
Mechanistic interpretability has made great strides in identifying neural network features (e.g., directions in hidden activation space) that mediate concepts(e.g., the birth year of a person) and enable predictable manipulation. Distributed alignment search (DAS) leverages supervision from counterfactual data to learn concept features within hidden states, but DAS assumes we can afford to conduct a brute force search over potential feature locations. To address this, we present HyperDAS, a transformer-based hypernetwork architecture that (1) automatically locates the token-positions of the residual stream that a concept is realized in and (2) constructs features of those residual stream vectors for the concept. In experiments with Llama3-8B, HyperDAS achieves state-of-the-art performance on the RAVEL benchmark for disentangling concepts in hidden states. In addition, we review the design decisions we made to mitigate the concern that HyperDAS (like all powerful interpretabilty methods) might inject new information into the target model rather than faithfully interpreting it.
Fluent Student-Teacher Redteaming
Jul 24, 2024Many publicly available language models have been safety tuned to reduce the likelihood of toxic or liability-inducing text. Users or security analysts attempt to jailbreak or redteam these models with adversarial prompts which cause compliance with requests. One attack method is to apply discrete optimization techniques to the prompt. However, the resulting attack strings are often gibberish text, easily filtered by defenders due to high measured perplexity, and may fail for unseen tasks and/or well-tuned models. In this work, we improve existing algorithms (primarily GCG and BEAST) to develop powerful and fluent attacks on safety-tuned models like Llama-2 and Phi-3. Our technique centers around a new distillation-based approach that encourages the victim model to emulate a toxified finetune, either in terms of output probabilities or internal activations. To encourage human-fluent attacks, we add a multi-model perplexity penalty and a repetition penalty to the objective. We also enhance optimizer strength by allowing token insertions, token swaps, and token deletions and by using longer attack sequences. The resulting process is able to reliably jailbreak the most difficult target models with prompts that appear similar to human-written prompts. On Advbench we achieve attack success rates $>93$% for Llama-2-7B, Llama-3-8B, and Vicuna-7B, while maintaining model-measured perplexity $<33$; we achieve $95$% attack success for Phi-3, though with higher perplexity. We also find a universally-optimized single fluent prompt that induces $>88$% compliance on previously unseen tasks across Llama-2-7B, Phi-3-mini and Vicuna-7B and transfers to other black-box models.
Fluent dreaming for language models
Jan 24, 2024Feature visualization, also known as "dreaming", offers insights into vision models by optimizing the inputs to maximize a neuron's activation or other internal component. However, dreaming has not been successfully applied to language models because the input space is discrete. We extend Greedy Coordinate Gradient, a method from the language model adversarial attack literature, to design the Evolutionary Prompt Optimization (EPO) algorithm. EPO optimizes the input prompt to simultaneously maximize the Pareto frontier between a chosen internal feature and prompt fluency, enabling fluent dreaming for language models. We demonstrate dreaming with neurons, output logits and arbitrary directions in activation space. We measure the fluency of the resulting prompts and compare language model dreaming with max-activating dataset examples. Critically, fluent dreaming allows automatically exploring the behavior of model internals in reaction to mildly out-of-distribution prompts. Code for running EPO is available at https://github.com/Confirm-Solutions/dreamy. A companion page demonstrating code usage is at https://confirmlabs.org/posts/dreamy.html
Incentive-Theoretic Bayesian Inference for Collaborative Science
Jul 07, 2023Contemporary scientific research is a distributed, collaborative endeavor, carried out by teams of researchers, regulatory institutions, funding agencies, commercial partners, and scientific bodies, all interacting with each other and facing different incentives. To maintain scientific rigor, statistical methods should acknowledge this state of affairs. To this end, we study hypothesis testing when there is an agent (e.g., a researcher or a pharmaceutical company) with a private prior about an unknown parameter and a principal (e.g., a policymaker or regulator) who wishes to make decisions based on the parameter value. The agent chooses whether to run a statistical trial based on their private prior and then the result of the trial is used by the principal to reach a decision. We show how the principal can conduct statistical inference that leverages the information that is revealed by an agent's strategic behavior -- their choice to run a trial or not. In particular, we show how the principal can design a policy to elucidate partial information about the agent's private prior beliefs and use this to control the posterior probability of the null. One implication is a simple guideline for the choice of significance threshold in clinical trials: the type-I error level should be set to be strictly less than the cost of the trial divided by the firm's profit if the trial is successful.
Principal-Agent Hypothesis Testing
May 13, 2022
Consider the relationship between the FDA (the principal) and a pharmaceutical company (the agent). The pharmaceutical company wishes to sell a product to make a profit, and the FDA wishes to ensure that only efficacious drugs are released to the public. The efficacy of the drug is not known to the FDA, so the pharmaceutical company must run a costly trial to prove efficacy to the FDA. Critically, the statistical protocol used to establish efficacy affects the behavior of a strategic, self-interested pharmaceutical company; a lower standard of statistical evidence incentivizes the pharmaceutical company to run more trials for drugs that are less likely to be effective, since the drug may pass the trial by chance, resulting in large profits. The interaction between the statistical protocol and the incentives of the pharmaceutical company is crucial to understanding this system and designing protocols with high social utility. In this work, we discuss how the principal and agent can enter into a contract with payoffs based on statistical evidence. When there is stronger evidence for the quality of the product, the principal allows the agent to make a larger profit. We show how to design contracts that are robust to an agent's strategic actions, and derive the optimal contract in the presence of strategic behavior.