 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a calibration metric be both testable and actionable?
Feb 27, 2025Forecast probabilities often serve as critical inputs for binary decision making. In such settings, calibration$\unicode{x2014}$ensuring forecasted probabilities match empirical frequencies$\unicode{x2014}$is essential. Although the common notion of Expected Calibration Error (ECE) provides actionable insights for decision making, it is not testable: it cannot be empirically estimated in many practical cases. Conversely, the recently proposed Distance from Calibration (dCE) is testable but is not actionable since it lacks decision-theoretic guarantees needed for high-stakes applications. We introduce Cutoff Calibration Error, a calibration measure that bridges this gap by assessing calibration over intervals of forecasted probabilities. We show that Cutoff Calibration Error is both testable and actionable and examine its implications for popular post-hoc calibration methods, such as isotonic regression and Platt scaling.
Stabilizing black-box model selection with the inflated argmax
Oct 23, 2024

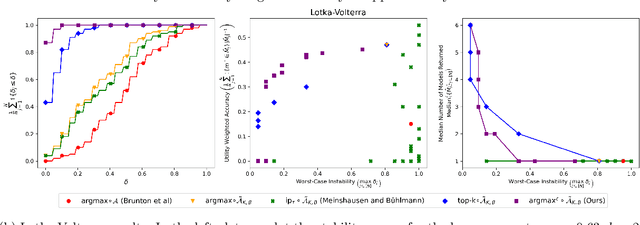

Model selection is the process of choosing from a class of candidate models given data. For instance, methods such as the LASSO and sparse identification of nonlinear dynamics (SINDy) formulate model selection as finding a sparse solution to a linear system of equations determined by training data. However, absent strong assumptions, such methods are highly unstable: if a single data point is removed from the training set, a different model may be selected. This paper presents a new approach to stabilizing model selection that leverages a combination of bagging and an "inflated" argmax operation. Our method selects a small collection of models that all fit the data, and it is stable in that, with high probability, the removal of any training point will result in a collection of selected models that overlaps with the original collection. In addition to developing theoretical guarantees, we illustrate this method in (a) a simulation in which strongly correlated covariates make standard LASSO model selection highly unstable and (b) a Lotka-Volterra model selection problem focused on identifying how competition in an ecosystem influences species' abundances. In both settings, the proposed method yields stable and compact collections of selected models, outperforming a variety of benchmarks.
Building a stable classifier with the inflated argmax
May 22, 2024We propose a new framework for algorithmic stability in the context of multiclass classification. In practice, classification algorithms often operate by first assigning a continuous score (for instance, an estimated probability) to each possible label, then taking the maximizer -- i.e., selecting the class that has the highest score. A drawback of this type of approach is that it is inherently unstable, meaning that it is very sensitive to slight perturbations of the training data, since taking the maximizer is discontinuous. Motivated by this challenge, we propose a pipeline for constructing stable classifiers from data, using bagging (i.e., resampling and averaging) to produce stable continuous scores, and then using a stable relaxation of argmax, which we call the "inflated argmax," to convert these scores to a set of candidate labels. The resulting stability guarantee places no distributional assumptions on the data, does not depend on the number of classes or dimensionality of the covariates, and holds for any base classifier. Using a common benchmark data set, we demonstrate that the inflated argmax provides necessary protection against unstable classifiers, without loss of accuracy.
Incentive-Theoretic Bayesian Inference for Collaborative Science
Jul 07, 2023Contemporary scientific research is a distributed, collaborative endeavor, carried out by teams of researchers, regulatory institutions, funding agencies, commercial partners, and scientific bodies, all interacting with each other and facing different incentives. To maintain scientific rigor, statistical methods should acknowledge this state of affairs. To this end, we study hypothesis testing when there is an agent (e.g., a researcher or a pharmaceutical company) with a private prior about an unknown parameter and a principal (e.g., a policymaker or regulator) who wishes to make decisions based on the parameter value. The agent chooses whether to run a statistical trial based on their private prior and then the result of the trial is used by the principal to reach a decision. We show how the principal can conduct statistical inference that leverages the information that is revealed by an agent's strategic behavior -- their choice to run a trial or not. In particular, we show how the principal can design a policy to elucidate partial information about the agent's private prior beliefs and use this to control the posterior probability of the null. One implication is a simple guideline for the choice of significance threshold in clinical trials: the type-I error level should be set to be strictly less than the cost of the trial divided by the firm's profit if the trial is successful.
Bagging Provides Assumption-free Stability
Jan 30, 2023



Bagging is an important technique for stabilizing machine learning models. In this paper, we derive a finite-sample guarantee on the stability of bagging for any model with bounded outputs. Our result places no assumptions on the distribution of the data, on the properties of the base algorithm, or on the dimensionality of the covariates. Our guarantee applies to many variants of bagging and is optimal up to a constant.
Principal-Agent Hypothesis Testing
May 13, 2022
Consider the relationship between the FDA (the principal) and a pharmaceutical company (the agent). The pharmaceutical company wishes to sell a product to make a profit, and the FDA wishes to ensure that only efficacious drugs are released to the public. The efficacy of the drug is not known to the FDA, so the pharmaceutical company must run a costly trial to prove efficacy to the FDA. Critically, the statistical protocol used to establish efficacy affects the behavior of a strategic, self-interested pharmaceutical company; a lower standard of statistical evidence incentivizes the pharmaceutical company to run more trials for drugs that are less likely to be effective, since the drug may pass the trial by chance, resulting in large profits. The interaction between the statistical protocol and the incentives of the pharmaceutical company is crucial to understanding this system and designing protocols with high social utility. In this work, we discuss how the principal and agent can enter into a contract with payoffs based on statistical evidence. When there is stronger evidence for the quality of the product, the principal allows the agent to make a larger profit. We show how to design contracts that are robust to an agent's strategic actions, and derive the optimal contract in the presence of strategic behavior.