 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing black-box model selection with the inflated argmax
Paper and Code
Oct 23, 2024

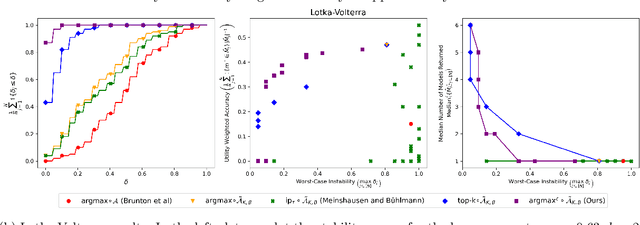

Model selection is the process of choosing from a class of candidate models given data. For instance, methods such as the LASSO and sparse identification of nonlinear dynamics (SINDy) formulate model selection as finding a sparse solution to a linear system of equations determined by training data. However, absent strong assumptions, such methods are highly unstable: if a single data point is removed from the training set, a different model may be selected. This paper presents a new approach to stabilizing model selection that leverages a combination of bagging and an "inflated" argmax operation. Our method selects a small collection of models that all fit the data, and it is stable in that, with high probability, the removal of any training point will result in a collection of selected models that overlaps with the original collection. In addition to developing theoretical guarantees, we illustrate this method in (a) a simulation in which strongly correlated covariates make standard LASSO model selection highly unstable and (b) a Lotka-Volterra model selection problem focused on identifying how competition in an ecosystem influences species' abundances. In both settings, the proposed method yields stable and compact collections of selected models, outperforming a variety of benchmarks.